In Collibra 2024.05, we launched a new user interface (UI) for Collibra Data Intelligence Platform! You can learn more about this latest UI in the UI overview.
Use the following options to see the documentation in the latest UI or in the previous, classic UI:
This topic provides an overview of the necessary steps to create a technical lineage via Edge.
You can also use the Collibra Catalog Cloud Ingestions API to create or update a technical lineage capability and start or schedule a synchronization to create a technical lineage. For more information about using APIs, go to Collibra Developer Portal.
To view the steps to create technical lineage for your data source, select the data source and connection type, if applicable. For a listed of supported data sources and their corresponding connection types, go to Supported data sources for technical lineage.
|
Select a data source and the connection type if needed to see the related information. Currently, the information is shown for: |

Amazon Redshift
Azure Data Factory
Azure SQL Data Warehouse
Azure SQL Server

Azure Synapse Analytics

Databricks Unity Catalog

DB2
dbt Cloud
dbt Core

Google BigQuery
Google Dataplex

Greenplum

HiveQL
IBM InfoSphere DataStage
Informatica Intelligent Cloud Services
Informatica PowerCenter

Looker
Matillion

MicroStrategy

Oracle

PostgreSQL

Power BI

MySQL

Netezza

SAP Analytics Cloud (Beta)

SAP Hana

Snowflake

Spark SQL

SQL Server
SQL Server Integration Services
SSRS-PBRS

Sybase

Tableau

Teradata

Custom technical lineage
|
Which connection type do you use?
For best technical lineage results, use the JDBC connection to ingest JDBC sources when possible, instead of using the Shared Storage connection with SQL files. |
Available vaults
|
You can use a vault to add your data source information to your Edge site connection. |

None

AWS Secrets Manager

Azure Key Vault
CyberArk Vault

Google Secret Manager

HashiCorp Vault
|
|
|
|
Before you begin
- This feature is available only in the latest UI.
- Use Collibra Data Intelligence Platform 2024.07 or newer
- Use Collibra Data Intelligence Platform 2024.02 or newer
- Use Collibra Data Intelligence Platform 2023.03 or newer.
- Use Collibra Data Intelligence Platform 2023.08 or newer
- Create an Edge site in Collibra Data Intelligence Platform.
- Install an Edge site.
-
Enable technical lineage via Edge.
To use technical lineage via Edge, you must first enable it. You can also define some specific technical lineage settings on Edge. The technical lineage settings are general configurations that apply to all technical lineage features on Edge.
Prerequisites and permissions
The settings on the Services Configuration page are also available in the DGC service settings in Collibra Console.
Note The Services Configuration page is not available by default.
Steps
Depending on your environment, follow this procedure either on the Services Configuration tab of the Collibra settings or in Collibra Console:
Important Editing the Services Configuration from the Settings page isn't available in the latest UI. If you use the latest UI, you can configure these settings only in Collibra Console. For more information, go to DGC service configuration settings.-
Open the Services Configuration page.
-
On the main toolbar, click
 , and then click
, and then click
 Settings.
Settings.
The Collibra settings page opens. - Click Services Configuration.
- Click Edit configuration.
Open the DGC service settings for editing:- Open Collibra Console.
Collibra Console opens with the Infrastructure page. - In the tab pane, expand an environment to show its services.
- In the tab pane, click the Data Governance Center service of that environment.
- Click Configuration.
- Click Edit configuration.
-
On the main toolbar, click
- In the Register data source section, for the setting SAP synchronization via Edge, set the value to
 True.
True. - In the Lineage on Edge section, enter the following information:
Setting
Description
DGC user name The user name to be used to ingest metadata in Data Catalog via Collibra Data Lineage service. DGC user password The password for the user to be used to ingest metadata. Collibra system name Indicates whether you want to use the system or server name of a data source to match to the System asset that you create in Data Catalog. Only set the value to
True when you have multiple databases with the same name.  False
False- The technical lineage via Edge ignores all system or server names that you specify for the Collibra system name settings when you add technical lineage capabilities. This is the default value.
- True
- The technical lineage via Edge uses the system or server names that you specify for the Collibra system name settings when you add technical lineage capabilities.
Important If you use technical lineage via Edge and the lineage harvester to generate the technical lineage, the following values must be the same:- The value for this setting.
- The value of the
useCollibraSystemNameproperty in the lineage harvester configuration file.
If the values are different, the technical lineage synchronization ends with an error.
- Click Save all.
-
-
Ensure that you meet the minimum network requirements.
The lineage harvester uses the HTTPS protocol by default and uses port 443.
Ensure that you satisfy your organization's firewall rules so that the Edge harvester can connect to all Collibra Data Lineage service instances in your geographic location:
Region Current service instances New service instances
IP address DNS name DNS name aws-ca 15.222.200.199 techlin-aws-ca.collibra.com techlin-ca-central-1.collibra.com aws-eu 18.198.89.106 techlin-aws-eu.collibra.com techlin-eu-central-1.collibra.com aws-sg 13.228.38.245 techlin-aws-sg.collibra.com techlin-ap-southeast-1.collibra.com aws-us 54.242.194.190 techlin-aws-us.collibra.com techlin-us-east-1.collibra.com gcp-au 35.197.182.41 techlin-gcp-au.collibra.com techlin-australia-souteast1.collibra.com gcp-ca 34.152.20.240 techlin-gcp-ca.collibra.com techlin-northamerica-northeast1.collibra.com gcp-eu 35.205.146.124 techlin-gcp-eu.collibra.com techlin-europe-west1.collibra.com gcp-sg 34.87.122.60 techlin-gcp-sg.collibra.com techlin-asia-southeast1.collibra.com gcp-uk 35.234.130.150 techlin-gcp-uk.collibra.com techlin-europe-west2.collibra.com gcp-us 34.73.33.120 techlin-gcp-us.collibra.com techlin-us-east1.collibra.com Important We are migrating the Collibra Data Lineage service instances to new DNS names. The migration will be completed by the end of December 2024. You can already start referring to the new DNS names in addition to the existing ones. If you have network infrastructure that requires traffic to be explicitly configured, we recommend that you adjust your configurations to also accommodate the new DNS names at your earliest convenience, to mitigate any interruptions of service. Removing any existing DNS names is not required yet during this migration.
The lineage harvester connects to different Collibra Data Lineage service instances based on your geographic location and cloud provider. If your location or cloud provider changes, the lineage harvester rescans all your data sources.
- You have to allow all Collibra Data Lineage service instances in your geographic location.
-
Regardless of your geographic location, you have to allow one of the following. This is required to retrieve the API Key. No other data is transferred.
Region Current service instances New service instances
IP address DNS name DNS name aws-ca 15.222.200.199 techlin-aws-ca.collibra.com techlin-ca-central-1.collibra.com aws-eu 18.198.89.106 techlin-aws-eu.collibra.com techlin-eu-central-1.collibra.com aws-us 54.242.194.190 techlin-aws-us.collibra.com techlin-us-east-1.collibra.com gcp-us 34.73.33.120 techlin-gcp-us.collibra.com techlin-us-east1.collibra.com In addition, we highly recommend that you always allow the techlin-aws-us instance as a backup, in case the lineage harvester cannot connect to other Collibra Data Lineage service instances.
Region Current service instances New service instances
IP address DNS name DNS name aws-us 54.242.194.190 techlin-aws-us.collibra.com techlin-us-east-1.collibra.com -
Connect to a proxy server, if needed.
CollibraData Lineage supports proxy server connection and authentication. Specifically, the technical lineage capability automatically applies all proxy settings that are configured on Edge.
The following proxies are supported when you create technical lineage for Databricks Unity Catalog:
- Path through (No authentication)
- Path through (Basic authentication)
- MITM (No authentication)
- MITM (Basic authentication)
- No proxy for noProxy hosts defined by Edge
For Collibra Data Lineage to connect to a data source that requires a proxy, you can configure a forward proxy on Edge when you install your Edge site. For detailed steps, go to configure a forward proxy on Edge.
When you add and synchronize the technical lineage capability on Edge, the technical lineage capability uses these proxy settings to establish connections to your data source to collect the metadata and create the technical lineage.
Proxy server support is added to each technical lineage capability. If you encounter a connection error while synchronizing a technical lineage capability for a data source with a forward proxy configured, contact Collibra Support.Using a custom certificate
You can use a custom certificate to allow the Edge capability to connect to your data source. To do so, save the certificate as "ca.pem" in the same directory as the Edge site installer. If you save the certificate in another directory, use the
--caargument in the Edge site installation command.Note In older versions of Collibra, the
--caflag only worked in conjunction with the--proxyflag. This is no longer true. You can now use a custom certificate without configuring a proxy. -
Enable technical lineage via Edge.
To use technical lineage via Edge, you must enable the technical lineage for different data sources. You can also define some specific technical lineage settings on Edge. The technical lineage settings are general configurations that apply to all technical lineage features on Edge.
Prerequisites and permissions
The settings on the Services Configuration page are also available in the DGC service settings in Collibra Console.
Note The Services Configuration page is not available by default.
Steps
Depending on your environment, follow this procedure either on the Services Configuration tab of the Collibra settings or in Collibra Console:
Important Editing the Services Configuration from the Settings page isn't available in the latest UI. If you use the latest UI, you can configure these settings only in Collibra Console. For more information, go to DGC service configuration settings.-
Open the Services Configuration page.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. - Click Services Configuration.
- Click Edit configuration.
Open the DGC service settings for editing:- Open Collibra Console.
Collibra Console opens with the Infrastructure page. - In the tab pane, expand an environment to show its services.
- In the tab pane, click the Data Governance Center service of that environment.
- Click Configuration.
- Click Edit configuration.
-
On the main toolbar, click
- In the Register data source section, select the value of True for the technical lineage features that you want to enable.
Setting
Description
Google Dataplex Lineage synchronization via Edge Enable the function of creating technical lineage for Google Dataplex.
- True
- Enable this feature.
- False
- Disable this feature.
- In the same Lineage on Edge section, enter the following information:
Setting
Description
DGC user name The user name to be used to ingest metadata in Data Catalog via Collibra Data Lineage service. DGC user password The password for the user to be used to ingest metadata. Collibra system name Indicates whether you want to use the system or server name of a data source to match to the System asset that you create in Data Catalog. Only set the value to
True when you have multiple databases with the same name. - False
- The technical lineage via Edge ignores all system or server names that you specify for the Collibra system name settings when you add technical lineage capabilities. This is the default value.
- True
- The technical lineage via Edge uses the system or server names that you specify for the Collibra system name settings when you add technical lineage capabilities.
Important If you use technical lineage via Edge and the lineage harvester to generate the technical lineage, the following values must be the same:- The value for this setting.
- The value of the
useCollibraSystemNameproperty in the lineage harvester configuration file.
If the values are different, the technical lineage synchronization ends with an error.
- Click Save all.
-
- Integrate Google Dataplex or register Google BigQuery databases by using the BigQuery JDBC connector. For details, go to Ways to work with Google Cloud Platform (GCP).
- Register the data source via Edge. Before you register the data source, ensure that you add the Catalog JDBC ingestion capability, so that CollibraData Lineage can stitch the data objects in your technical lineage to the assets in Data Catalog.
- Integrate Databricks Unity Catalog or register a Databricks file system.
-
Register Azure Data Factory in the Azure Portal and assign the necessary permissions and access.
Collibra Data Lineage uses Azure APIs to get the information necessary to build technical lineage from Azure Data Factory. Use this information to register Azure Data Factory in the Azure Portal and assign the necessary permissions and access.
Warning Because the tasks covered in this topic are performed outside of Collibra, it is possible that the content changes without us knowing. We strongly recommend that you carefully read the source documentation.
Topics in this section
- Required values for your technical lineage for Azure Data Factory capability
- Register your Azure Data Factory instance in the Azure Portal
- Assign the API permissions
- Create an authentication secret
- Create an Azure Active Directory group and add your Azure Data Factory instance
- Add your Azure Data Factory instance to a resource group
- Retrieve the subscription ID of the resource group
- Assign read-only permissions to the resource group
Required values for your technical lineage for Azure Data Factory capability
The tasks in this topic help you to identify the values you will need when you create an Azure connection and add a technical lineage for Azure Data Factory capability. You need the correct values for the fields shown in the following table.
Important If you want to create a technical lineage for more than one Azure Data Factory instance, you need this information for each instance.
Properties Description Resource Group Name The name of a resource group with the Reader role for the Azure Data Factory instance.
To get the resource group name, go to Add your Azure Data Factory instance to a resource group.
Service Principal ID The Application account ID to connect to the Azure.
For information on the Azure Service Principal user and the Application ID, go to the Azure documentation.To get the application ID for this field, go to Register your Azure Data Factory instance in the Azure Portal.
Service Principal Secret If you want to use the Service Principal authentication type, enter the application secret for the Service Principal.
For information on the application secret value, go to the Azure documentation.If you want to use the Resource Owner Password Credentials authentication type, enter the password.
Ensure that you select the corresponding authentication type when you add the Technical Lineage for ADF capability.
To get the service principal secret, go to Create an authentication secret.
Subscription ID The subscription ID of the resource group.
To get the subscription ID, go to Retrieve the subscription ID of the resource group.
Tenant ID The directory ID of your Azure Data Factory instance.
For information on the Directory (tenant) ID, go to the Azure documentation.To get the directory ID, go to Register your Azure Data Factory instance in the Azure Portal.
Register your Azure Data Factory instance in the Azure Portal
Follow the Microsoft Azure instructions on how to register an application and refer to the following table for help with the various settings:
Setting Description Name The name of your Azure Data Factory instance. Supported account types The type of tenant. This indicates who can access the Azure Data Factory instance.
Select Single tenant.
Redirect URI The location to which a user's client is redirected and where security tokens are sent after successful authorization. In this case, the redirect URI must be of the type Web.
Leave this field empty. You don't have to specify a web location.
The Azure Portal creates:
- The Application ID. Use this ID as the value for the Service Principal ID field in the Azure connection.
- The Directory ID. Use this ID as the value for the Tenant ID field in the technical lineage for ADF capability.
Note When your Azure Data Factory instance is registered, you can find these two IDs in the Overview pane on the Azure Portal or in the upper-right menu.Assign the API permissions
-
In the Azure Portal, click the Authentication pane, and then:
- Click the Advanced settings section.
- For the Allow public client flows option, click Yes.
- Click the API permissions pane, and then:
- For the permission type, click Delegated permissions.
- Assign the Azure Data Factory instance in Microsoft Azure the Microsoft Graph User.Read permission.
The user now has the following permissions:
- Microsoft Graph
- User.Read
Create an authentication secret
- In the sidebar navigation, in the Manage section, click Certificates and secrets.
-
Ciick New client secret. Note that certificates are not supported.
- Enter a description.
- Use the date picker to specify an expiration date for the authentication secret.
- Click Add.
An authentication secret is shown. Use this secret as the value for the Service Principal Secret field in the Azure connection.Important Make note of the authentication secret. For security purposes, It will not be available later. If you lose the authentication secret, you will need to create a new one.
Create an Azure Active Directory group and add your Azure Data Factory instance
- Go to the Group Management page for your Azure Data Factory instance.
-
Follow the Microsoft Azure instructions on how to Create and manage an Azure Active Directory (AD) Group, and refer to the following table for help with the various settings:
Setting Description Group Name The name of the new Azure AD group that you are creating.
Group Type The type of the Azure AD group.
Select Security.
Service Principal The identity an application uses to access Azure resources and APIs.
Enter the Application ID that was generated when you registered Azure Data Factory in the Azure Portal.
Add your Azure Data Factory instance to a resource group
Your Azure Data Factory instance should already be part of a resource group. If it is, you can skip this step. If it's not, you need to create a resource group and add your Azure Data Factory instance to it.
Use the group name as the value for the Resource Group Name field in the technical lineage for ADF capability.
Tip The Data factories page shows all of your Azure Data Factory instances, including their subscriptions and resource groups. Check here to know if your instance is part of a resource group.
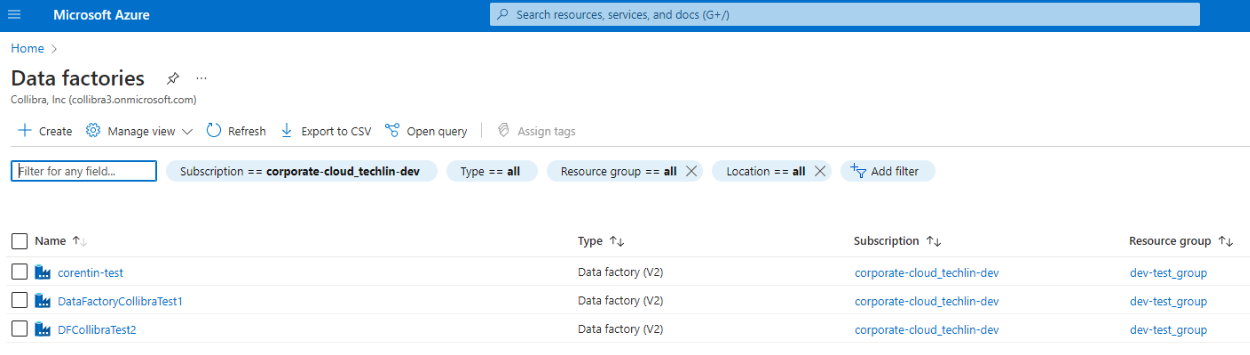
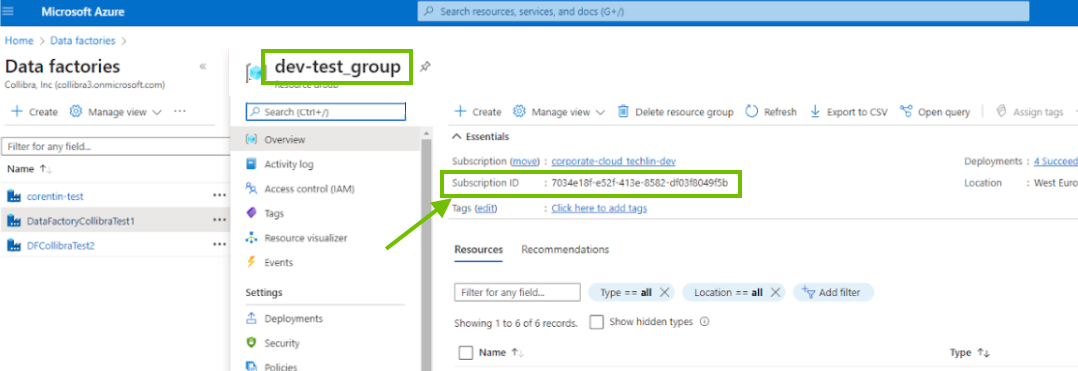
Retrieve the subscription ID of the resource group
On the Data factories page, click the resource group for the Azure Data Factory instance for which you want to create a technical lineage, and make note of the subscription ID.
Use the subscription ID as the value for the Subscription ID field in the technical lineage for ADF capability.
Assign read-only permissions to the resource group
To gather the information needed for technical lineage, the resource group needs permission to read the APIs.
-
Check to see which permissions the resource group has.
- On the Resource groups page, click Access control (IAM).
-
In the Check access search box, type the name of the AD group.
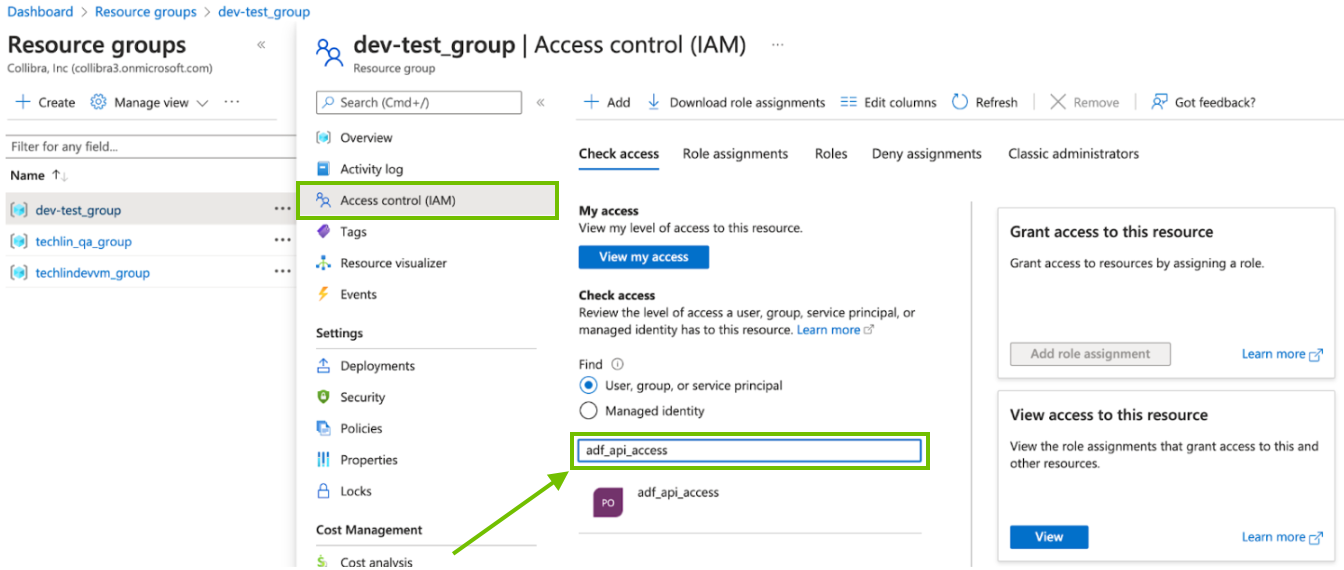
- In the search results, click on the AD group to see the access assignments.
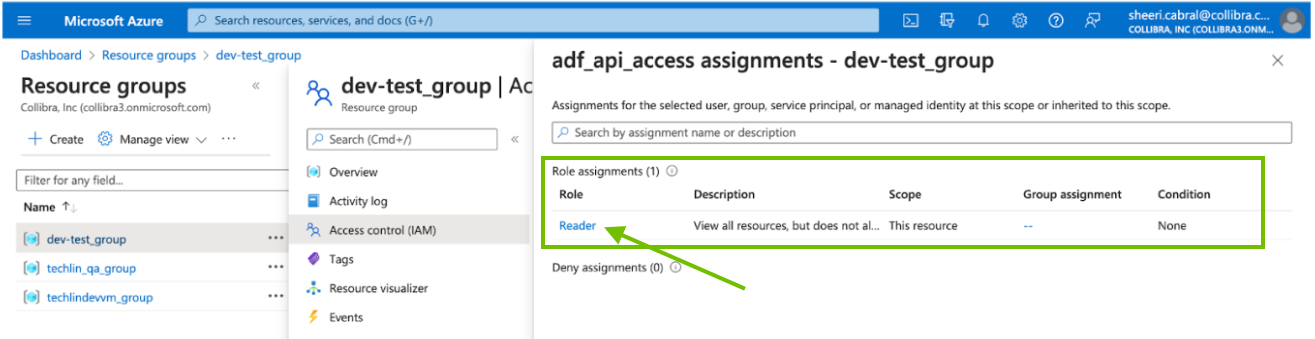
- If your resource group does not have the Reader role, click X in the upper-right corner, to close the Access assignments page.
The Access control (IAM) page again appears. - Click the Role assignments tab.

- Click Add > Add role assignment and follow the Microsoft Azure instructions on how to add a role assignment. Refer to the following table for help with the various settings:
Setting Description Roles The role assignment for the resource group.
Select Reader.
The lineage harvester only needs read access.
Members Ensure that the User, group, or service principal radio button is selected.
Search for and select the AD group.
Conditions No conditions are necessary. Click Next. Review + assign Click Review +assign, to assign the Reader role to the resource group. After a few moments, the read-only permission is assigned to the resource group.
If your resource group already has the Reader role, as shown in the previous image, this task is complete.
- Review the Supported transformation details topic to understand the lineage information Collibra Data Lineage ingests from Databricks Unity Catalog.
Requirements and permissions
The following requirements and permissions are needed for the technical lineage process. Additional, Edge-related roles and resources, are mentioned in each of the specific steps.
- A global role with the following global permissions:
- Data Stewardship Manager
- Manage all resources
- System administration
- Technical lineage
- A resource role with the following resource permissions on the community level in which you created the domain:
- Asset: add
- Attribute: add
- Domain: add
- Attachment: add
- As a technical lineage user, ensure that your Catalog Author global role has the following global permissions. With these permissions, Collibra Data Lineage can process the lineage and synchronize the results to Data Catalog to create technical lineage.
- Catalog > Advanced Data Type > Add
- Catalog > Advanced Data Type > Remove
- Catalog > Advanced Data Type > Update
- Catalog > Technical lineage
- As a Data Catalog user, ensure that your Edge integration engineer global role has the following global permissions. With these permissions, you can create connections and capabilities on Edge, configure the integration, and synchronize the integration.
- Manage connections and capabilities
- View Edge connections and capabilities
- As a Databricks Unity Catalog user, ensure that you have the following permissions in Databricks. The access token of this user must be specified in the Databricks connection so that Collibra Data Lineage can access the system tables (Public Preview) after connecting to Databricks Unity Catalog.
- Enable the lineage system tables.
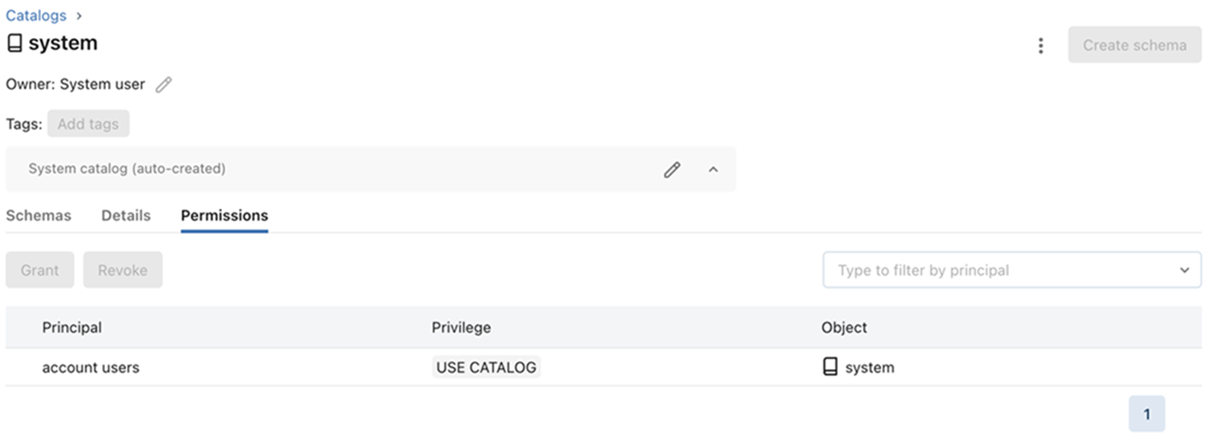
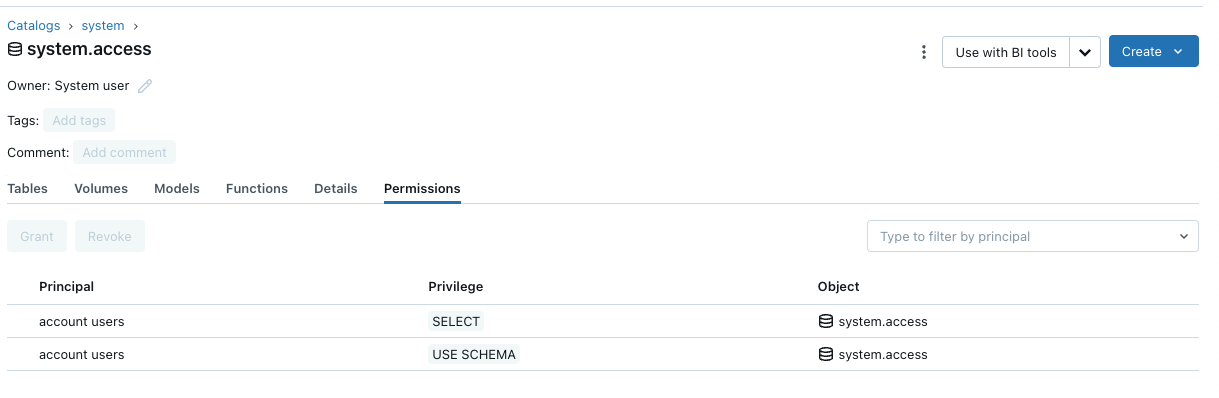
- Have the USE CATALOG privilege to the
systemcatalog. - USE_SCHEMA, and SELECT privileges to the
system.accessschema. - Log into Databricks with the credentials that you use to create a Databricks connection on Edge.
- Run the following SQL query against your
system.accesscatalog and schema in Unity Catalog:
SELECT count(*) FROM column_lineage
For details, go to Enable system tables and Grant access to system tables in Databricks documentation.How to verify whether you have the right accesses in Databricks?If you do not have the right accesses, the Could not get column lineage data error occurs when you synchronize the
Technical Lineage for Databricks Unity Catalogcapability. Contact Databricks support if you encounter issues on getting access to the system tables. - Necessary permissions to all database objects that technical lineage via Edge accesses.
- bigquery.datasets.get
- bigquery.tables.get
- bigquery.tables.list
- bigquery.jobs.create
- resourcemanager.projects.get
- bigquery.routines.get
- bigquery.routines.list
- bigquery.readsessions.create
- bigquery.readsessions.getData
- GRANT SELECT, at table level. Grant this to every table for which you want to create a technical lineage.
-
The role of the user that you specify in the
usernameproperty in lineage harvester configuration file must be the owner of the views in PostgreSQL. - SELECT, at table level. Grant this to every table for which you want to create a technical lineage.
- Read access to the SYS schema or the tables in the schema.
- SELECT on the following views:
- _SYS_REPO.ACTIVE_OBJECT
- _SYS_REPO.ACTIVE_OBJECTCROSSREF
- SYS.OBJECT_DEPENDENCIES
- The CATALOG READ system privilege
- Ensure that the Snowflake user has the appropriate allowed host list. For details, go to Allowing Hostnames in Snowflake documentation.
- You need a role that can access the Snowflake shared read-only database. To access the shared database, the account administrator must grant the OBJECT_VIEWER database role on the shared database to the user. The username of the user must be specified in the JDBC connection that you use to access Snowflake.
- all_tab_cols
- all_col_comments
- all_objects
- ALL_DB_LINKS
- all_mviews
- all_source
- all_synonyms
- all_views
- If via Edge: Replace
all_sourcebydba_sourcein the Other Queries field in your Edge capability. - If via the CLI lineage harvester: Replace
all_sourcebydba_sourcein the file ./sql/oracle/queries.sql, which is included in the ZIP file when you download the lineage harvester. - Your user role must have privileges to export assets.
- You must have read permission on all assets that you want to export.
- You have at least a Matillion Enterprise license.
- You have generated the Matillion certificate. Ensure that the certificate is signed by a certificate authority. Self-signed certificate is not supported when you create technical lineage via Edge.
- You have added the Matillion certificate to a Java truststore. For more information about adding a certificate to a Java truststore, go to Add a Certificate to a Truststore Using Keytool.
- As a technical lineage user, ensure that your Catalog Author global role has the following global permissions. With these permissions, CollibraData Lineage can process the lineage and synchronize the results to Data Catalog to create technical lineage.
- Catalog > Advanced Data Type > Add
- Catalog > Advanced Data Type > Remove
- Catalog > Advanced Data Type > Update
- Catalog > Technical lineage
- As a Data Catalog user, ensure that your Edge integration engineer global role has the following global permissions. With these permissions, you can create connections and capabilities on Edge, configure the integration, and synchronize the integration.
- Manage connections and capabilities
- View Edge connections and capabilities
- As a Google Dataplex user, ensure that you have the following access. Use the service account of this user when you create a GCP connection so that CollibraData Lineage can harvest lineage from Dataplex.
- Enable the Data Lineage API in Dataplex for the projects that you want to harvest lineage from. For more information, go to Data Lineage API in Google Cloud documentation.
- The Data Lineage Viewer role.
- The BigQuery Admin role if you want Collibra Data Lineage to collect lineage not only from stored procedures that you created but also from those that other Dataplex users created.
- The
bigquery.jobs.getpermission.For more information, go to IAM basic and predefined roles reference in the Google Cloud documentation. - When you synchronize technical lineage for Google Dataplex, you can add Project IDs that you want to harvest lineage from. If you want to have Project IDs available for selection when you add Project IDs, ensure that the service account has the
resourcemanager.projects.getpermission to GCP Projects where Dataplex is enabled. If the service account does not have this permission, you can enter the Project IDs manually on the Synchronization configuration page.
-
You need the following Admin API permissions:
- The first call we make to MicroStrategy is to authenticate. We connect to:
<MSTR URL>:<Port>/MicroStrategyLibrary/api-docs/ and use GET api/auth/login.
For complete information, see the MicroStrategy documentation.
If this API call can be made successfully, you can ingest the metadata. - The same connection:
<MSTR URL>:<Port>/MicroStrategyLibrary/api-docs/, but with GET api/model/tables/<tableId>.
For complete information, see the MicroStrategy documentation.
This endpoint is needed to create lineage and stitching.
- The first call we make to MicroStrategy is to authenticate. We connect to:
- You need permissions to access the library server.
- The lineage harvester uses port 443. If the port is not open, you also need permissions to access the repository.
- You have to configure the MicroStrategy Modeling Service. For complete information, see the MicroStrategy documentation.
- Power BI on the Microsoft Power Platform.
- Power BI on Fabric.
- Select the "Disallow Numeric Query IDs" option in Looker.
- Ensure that your Looker user has the Admin role. The Admin role has the Administer permission, which is not available in the custom permission set.
- A system-level role that is at least a System user role.
- An item-level role that is at least a Content Manager role.
dbt compile command, to a Shared Storage connection folder. For more information about the Shared Storage connection folder, go to Step 1 Create a Shared Storage connection. You need Monitoring role permissions.
To create technical lineage from calculated views in an SAP HANA Classic on-premises data source, you also need the following permissions:
SQL or SQL-API.all_source table to retrieve Package bodies. However, this requires the EXECUTE privilege. As an alternative, you can direct the harvester to query the dba_source table, which requires the SELECT_CATALOG_ROLE role. To do so, you need to:Collibra Data Lineage supports:
Collibra Data Lineage uses the API 4.0 endpoints GET /queries/<query_id> and GET /running_queries. Due to a security update by Looker, the behavior of these endpoints has changed. Therefore, you must now:
For complete information, see the Looker Query ID API Patch Notice.
You need the following roles, with user access to the server from which you want to ingest:
We recommend that you use SQL Server 2019 Reporting Services or newer. We can't guarantee that older versions will work.
Steps
- Set up Tableau.
- Set up Power BI.
- Set up Looker.
- Set up SAP Analytics Cloud.
- Set up SSRS-PBRS.
- Set up MicroStrategy.
-
Create a JDBC connection.
For Collibra Data Lineage to connect to and retrieve metadata from your data source, create a JDBC connection.
If you have set up a JDBC connection when you registered the data source via Edge, you can use the existing JDBC connection.
For details about creating a JDBC connection, go to Create a JDBC connection.
-
Create a Google Cloud Platform (GCP) connection.
For Collibra Data Lineage to connect to and retrieve metadata from Google Dataplex, create a GCP connection.
Available vaults
TipYou can use a vault to add your data source information to your Edge site connection.
None
AWS Secrets Manager
Azure Key Vault
CyberArk Vault
Google Secret Manager
HashiCorp VaultBefore you begin
- You have added a vault to your Edge site.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the table, click the name of the Edge site whose status is Healthy.
The Edge site page opens.
-
On the main toolbar, click
- In the Connections section, click Create connection.
The Create connection page appears. - Select the GCP connection to connect to Google Cloud Platform.
- Enter the required information.
Field Description Required Name The name of the Edge connection for Google Cloud Platform.
 Yes
YesDescription The description of the connection.
 No
No
Vault The vault where you store your data source values. No
GCP Service Account The account to connect to the GCP.
Add the full content of the service account key JSON file.Example{
"type": "service_account",
"project_id": "PROJECT_ID",
"private_key_id": "KEY_ID",
"private_key": "-----BEGIN PRIVATE KEY-----\nPRIVATE_KEY\n-----END PRIVATE KEY-----\n",
"client_email": "SERVICE_ACCOUNT_EMAIL",
"client_id": "CLIENT_ID",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/SERVICE_ACCOUNT_EMAIL"}Ensure the service account has the required permissions.
For more information about service account keys, go to the Google documentation.How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example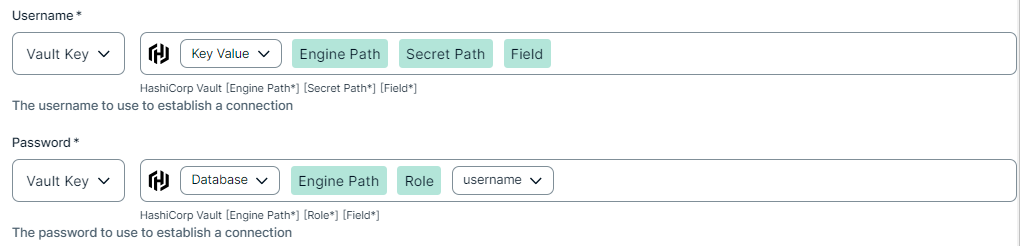
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example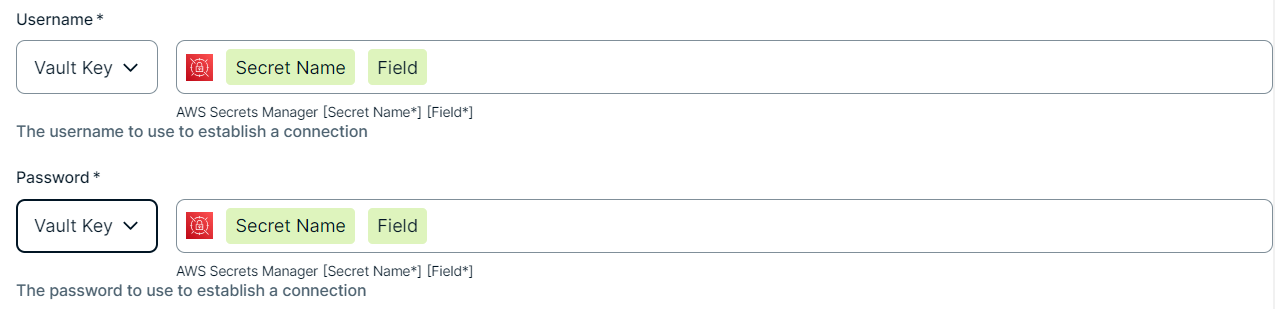
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
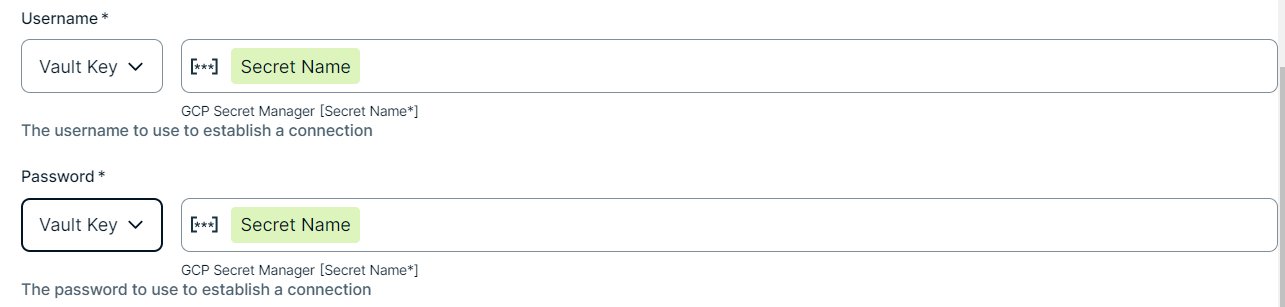
Yes
Property If your connection to GCP requires any additional parameters, click Add Property.
No
- Click Create.
The connection is added to the Edge site.
-
Create an Azure Data Factory connection.
For Collibra Data Lineage to connect to and retrieve metadata from Azure Data Factory, create an Azure connection.
Before you begin
Create an Edge site on K3S.
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage Edge sites global permission.
- You have a global role that has the Manage connections and capabilities global permission.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
- Click Create Connection.
The Connection settings page opens. - In the Connections section, click Create Connection.
The Create Connection dialog box appears. - Select the Azure connection.
-
Enter the connection information.
Field Description Required Connection settings
This section contains the general settings of your connection.
NameThe name of the Edge connection for Azure Data Factory.
YesDescriptionThe description of the connection.
No
Connection providerThe connection provider, which determines the available connection parameters.
Select the Azure connection.
Yes
Connection parameters
This section contains the settings to connect to your data source. Service Principal IDThe Application account ID to connect to the Azure.
For information on the Azure Service Principal user and the Application ID, go to the Azure documentation. Yes
Service Principal SecretIf you want to use the Service Principal authentication type, enter the application secret for the Service Principal.
For information on the application secret value, go to the Azure documentation.If you want to use the Resource Owner Password Credentials authentication type, enter the password.
Ensure that you select the corresponding authentication type when you add the Technical Lineage for ADF capability.
Yes
Encryption optionsSelect the type of encryption used to store the Secret Access Key.
The default is To be encrypted by Edge management server.
Yes
Tenant IDThe directory ID of your Azure Data Factory instance.
For information on the Directory (tenant) ID, go to the Azure documentation. Yes
Field Description Required Name The name of the Edge connection for Azure Data Factory.
YesDescription The description of the connection.
No
Vault The vault where you store your data source values. No
Service Principal IDThe Application account ID to connect to the Azure.
For information on the Azure Service Principal user and the Application ID, go to the Azure documentation.How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Service Principal SecretIf you want to use the Service Principal authentication type, enter the application secret for the Service Principal.
For information on the application secret value, go to the Azure documentation.If you want to use the Resource Owner Password Credentials authentication type, enter the password.
Ensure that you select the corresponding authentication type when you add the Technical Lineage for ADF capability.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Tenant ID
The directory ID of your Azure Data Factory instance.
For information on the Directory (tenant) ID, go to the Azure documentation.How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
- Click Create.
-
Create a Databricks connection.
If you integrated Databricks Unity Catalog, you had created a Databricks connection. You can use the Databricks connection when you add a technical lineage for Databricks Unity Catalog. If you registered your Databricks file system by using the JDBC connection instead, use this information to create a Databricks connection.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
- Click Create Connection.
The Connection settings page appears. -
In the Connections section, click Create Connection and select Databricks connection in the Create Connection dialog box.
The Create Connection dialog box for Databricks connection opens. - Enter the required information.
Field Description Required Name The name of the Edge connection for Databricks.
YesDescription The description of the connection.
No
Vault The vault where you store your data source values. No
Workspace URL Enter the URL of any Databricks workspace connected to Unity Catalog that you want to integrate.
To retrieve the URL, log into Databricks and copy the URL. For example: https://123.cloud.databricks.com.How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Access Token The security token that was generated in Databricks for the workspace.
The access token can be a personal access token or service principle token. We recommend using a service principle token. For information on the service principle token, go to the Databricks documentation.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Field Description Required Connection settings
This section contains the general settings of your connection.
NameThe name of the Edge connection for Databricks.
YesDescriptionThe description of the connection.
No
Connection providerThe connection provider, which determines the available connection parameters.
Select Databricks to connect to Databricks.
Yes
Connection parameters
This section contains the settings to connect to your data source. Workspace URLEnter the URL of any Databricks workspace connected to Unity Catalog that you want to integrate.
To retrieve the URL, log into Databricks and copy the URL. For example: https://123.cloud.databricks.com. Yes
Access TokenThe security token that was generated in Databricks for the workspace.
The access token can be a personal access token or service principle token. We recommend using a service principle token. For information on the service principle token, go to the Databricks documentation.
Yes
Encryption optionsSelect the type of encryption used to store the Secret Access Key.
Default: To be encrypted by Edge management server.
Yes
- Click Create.
The connection is added to the Edge site.
- Open an Edge site.
-
Create a dbt connection.
For CollibraData Lineage to connect to and retrieve metadata from dbt Cloud, create a dbt connection.
Before you begin
Create an Edge site on K3S.
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage Edge sites global permission.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
- Click Create Connection.
The Connection settings page appears. -
In the Connections section, click Create Connection.
The Create Connection dialog box appears. - Select dbt connection.
- Enter the connection information.
Field Description Required Connection settings This section contains the settings to connect to your data source. NameThe name of the connection. Yes
DescriptionThe description of the connection. This field is also visible when you register content. No
Connection providerThe connection provider, which determines the available connection parameters.
Select dbt connection.
Yes
Connection parameters This section contains general settings to connect to your data source. Admin URLThe dbt Cloud Administrative API that Collibra Data Lineage uses to download job artifacts. The default value is
https://cloud.getdbt.com/api/v2.This field is used if you do not enter a value for the Environment Ids field in the Technical Lineage for dbt Cloud capability.
If you enter values for both the Admin URL and Environment Ids fields, the Environment Ids field takes precedence.
No
Metadata URLThe dbt Cloud Discovery API. The default value is
https://metadata.cloud.getdbt.com/graphql.For details, go to Query the Discovery API in dbt documentation.
No
Token NameThe name of the service token. It can be any unique meaningful name.
How to get a service token and token value.- Generate a Service token and ensure that you set the Read-Only permissions for CollibraData Lineage to work properly.
- Copy the token value when you save the service token.
For details, go to Generating service account tokens in dbt documentation.
Yes
Token ValueEnter the service token.
Tip You can select To be encrypted by Edge management server or Encrypted with public key to indicate the encryption method.
Yes
Field Description Required Name
The name of the connection. Yes
Description
The description of the connection. This field is also visible when you register content. No
Vault The vault where you store your data source values. No
Admin URL
The dbt Cloud Administrative API that Collibra Data Lineage uses to download job artifacts. The default value is
https://cloud.getdbt.com/api/v2.This field is used if you do not enter a value for the Environment Ids field in the Technical Lineage for dbt Cloud capability.
If you enter values for both the Admin URL and Environment Ids fields, the Environment Ids field takes precedence.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
No
Metadata URL
The dbt Cloud Discovery API. The default value is
https://metadata.cloud.getdbt.com/graphql.For details, go to Query the Discovery API in dbt documentation.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
No
Token Name
The name of the service token. It can be any unique meaningful name.
How to get a service token and token value.- Generate a Service token and ensure that you set the Read-Only permissions for CollibraData Lineage to work properly.
- Copy the token value when you save the service token.
For details, go to Generating service account tokens in dbt documentation.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Token Value
Enter the service token.
Tip You can select To be encrypted by Edge management server or Encrypted with public key to indicate the encryption method.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
- Click Create.
-
Create an Informatica Intelligent Cloud Services connection.
For CollibraData Lineage to connect to and retrieve metadata from Informatica Intelligent Cloud Services, create an Informatica Intelligent Cloud Services (IICS) connection.
Before you begin
- To create and use Informatica Intelligent Cloud Services (IICS) connection, use Collibra Data Intelligence Platform 2023.03 or later.
- Create an Edge site on K3S.
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage Edge sites global permission.
- You have a global role that has the Manage connections and capabilities global permission.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
- Click Create Connection.
The Connection settings page appears. -
In the Connections section, click Create Connection.
The Create Connection dialog box appears. - Select Informatica Intelligent Cloud Services (IICS) connection.
- Enter the connection information.
Field Description Required Connection settings This section contains the settings to connect to your data source. NameThe name of the connection. Yes
DescriptionThe description of the connection. This field is also visible when you register content. No
Connection providerThe connection provider, which determines the available connection parameters.
Select Informatica Intelligent Cloud Services (IICS) connection.
Yes
Connection parameters This section contains general settings to connect to your data source. IICS URLThe URL of the Informatica Intelligent Cloud Services environment sign-in page. For example:
https://dm-us.informaticaintelligentcloud.com. Yes
UsernameThe username that you use to sign in to Informatica Intelligent Cloud Services. Yes
PasswordThe password that you use to sign in to Informatica Intelligent Cloud Services.
Tip You can select To be encrypted by Edge management server or Encrypted with public key to indicate the encryption method.
Yes
Field Description Required Name
The name of the connection. Yes
Description
The description of the connection. This field is also visible when you register content. No
Vault The vault where you store your data source values. No
IICS URL
The URL of the Informatica Intelligent Cloud Services environment sign-in page. For example:
https://dm-us.informaticaintelligentcloud.com.How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Username
The username that you use to sign in to Informatica Intelligent Cloud Services.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Password
The password that you use to sign in to Informatica Intelligent Cloud Services.
Tip You can select To be encrypted by Edge management server or Encrypted with public key to indicate the encryption method.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
- Click Create.
-
Create a Tableau connection.
To retrieve data from Tableau, you have to connect to Tableau via the Edge site.
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage Edge sites global permission.
- You have a global role that has the Manage connections and capabilities global permission.
- You have a resource role with the Configure external system resource permission, for example, Owner.
- If you connect to Tableau Online, you have a Tableau user with at least Viewer rights.
- If you connect to Tableau Server, you have a Tableau user with access to at least one site.
- You have the necessary Tableau permissions.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
-
In the Connections section, click Create Connection.
The Connection settings page appears. -
In the Connections section, click Create Connection.
The Create Connection dialog box appears. - Select Tableau connection.
- Enter the required information.
Field Description Required Connection settings This section contains general information about the connection. Name The name of the connection. The name can be anything, as long as it is unique.
Tip The name that you provide here is the name you have to select in the Tableau connection field, when adding the Technical Lineage for Tableau capability to the Edge site.
Yes
Description The description of the connection. No
Connection provider The type of connection.
Select Tableau connection.
Yes
Connection parameters This section contains connection authentication information. URL The URL of your Tableau server. Yes
Authentication type The authentication type for your connection to the Tableau server.
Yes
Username/Token name - If you selected authentication type username, enter the username of the Tableau user.
- If you selected authentication type token, enter the personal access token name of the Tableau user.
Yes
Password/Token secret - If you selected authentication type username, enter the password of the Tableau user.
- If you selected authentication type token, enter the personal access token secret of the Tableau user.
Yes
Custom certificate Important This field will soon be deprecated. For guidance on uploading a custom certificate to an Edge site, refer to the "Connect to a proxy server if needed" content in the "Before you begin" section of this topic.
Optional field for uploading a custom server certificate, to connect to
Click Upload and search for your custom server certificate.
You don't need to add the certificate to the Java Truststore. Edge stores the certificate as it does any other input parameter, and automatically uses it when connecting to
NoField Description Required Name The name of the connection. The name can be anything, as long as it is unique.
Tip The name that you provide here is the name you have to select in the Tableau connection field, when adding the Technical Lineage for Tableau capability to the Edge site.
Yes
Description The description of the connection. No
Vault The vault where you store your data source values. No
URL The URL of your Tableau server.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Authentication Type The authentication type for your connection to the Tableau server.
Yes
Username/Token Name - If you selected authentication type username, enter the username of the Tableau user.
- If you selected authentication type token, enter the personal access token name of the Tableau user.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Password/Token Secret - If you selected authentication type username, enter the password of the Tableau user.
- If you selected authentication type token, enter the personal access token secret of the Tableau user.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Custom Certificate Important This field will soon be deprecated. For guidance on uploading a custom certificate to an Edge site, refer to the "Connect to a proxy server if needed" content in the "Before you begin" section of this topic.
Optional field for uploading a custom server certificate, to connect to
Click Upload and search for your custom server certificate.
You don't need to add the certificate to the Java Truststore. Edge stores the certificate as it does any other input parameter, and automatically uses it when connecting to
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
No - Click Create.
What's next?
Add the Technical Lineage for Tableau capability to the Edge site.
-
Create a Looker connection.
To retrieve data from Looker, you have to connect to Looker via the Edge site.
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage Edge sites global permission.
- You have a global role that has the Manage connections and capabilities global permission.
- You have a resource role with the Configure external system resource permission, for example, Owner.
- You have a Looker user with the Admin role.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
-
In the Connections section, click Create Connection.
The Connection settings page appears. -
In the Connections section, click Create Connection.
The Create Connection dialog box appears. - Select Looker connection.
- Enter the required information.
Field Description Required Connection settings This section contains general information about the connection. Name The name of the connection. The name can be anything, as long as it is unique.
Tip The name that you provide here is the name you have to select in the Looker connection field, when adding the Technical Lineage for Looker capability to the Edge site.
Yes
Description The description of the connection. No
Connection provider The type of connection.
Select Looker connection.
Yes
Connection parameters This section contains connection authentication information. Looker URL The URL to your Looker API. Yes
Client ID The username you use to access the Looker API. Yes
Client secret key The secret key you use to access the Looker API. Yes
Field Description Required Name The name of the connection. The name can be anything, as long as it is unique.
Tip The name that you provide here is the name you have to select in the Looker connection field, when adding the Technical Lineage for Looker capability to the Edge site.
Yes
Description The description of the connection. No
Vault The vault where you store your data source values. No
Looker URL The URL to your Looker API.
Tip There are two ways to find the Looker API URL:- In the API Host URL field in the Looker Admin menu. If this field is empty, you can use the default Looker API URL which you can find in the interactive API documentation.
- In the interactive API documentation URL. It is the part of the URL before
/api-docs/.
Note Looker 3.1 APIs are deprecated; however, the API3 credentials for authorization and access control remain valid.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Client ID The username you use to access the Looker API.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Client secret key The secret key you use to access the Looker API.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
- Click Create.
What's next?
Add the Technical Lineage for Looker capability to the Edge site.
-
Create a Microsoft SSRS/PBRS connection.
To retrieve data from SSRS-PBRS, you have to connect to SSRS-PBRS via the Edge site.
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage Edge sites global permission.
- You have a global role that has the Manage connections and capabilities global permission.
- You have a resource role with the Configure external system resource permission, for example, Owner.
-
You need the following roles, with user access to the server from which you want to ingest:
- A system-level role that is at least a System user role.
- An item-level role that is at least a Content Manager role.
We recommend that you use SQL Server 2019 Reporting Services or newer. We can't guarantee that older versions will work.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
-
In the Connections section, click Create Connection.
The Connection settings page appears. -
In the Connections section, click Create Connection.
The Create Connection dialog box appears. - Select Microsoft SSRS/PBRS connection.
- Enter the required information.
Field Description Required Connection settings This section contains general information about the connection. Name The name of the connection. The name can be anything, as long as it is unique.
Tip The name that you provide here is the name you have to select in the Microsoft SSRS/PBRS connection field, when adding the Technical Lineage for SSRS-PBRS capability to the Edge site.
Yes
Description The description of the connection. No
Connection provider The type of connection.
Select Microsoft SSRS/PBRS connection.
Yes
Connection parameters This section contains connection authentication information. Microsoft SSRS-PBRS URL The URL to the server's web portal. By default, the URL is http://<computer-name>/reports. For example, "http://1.23.45.678/PowerBIReports". Yes
Username The username you use to sign in to the web portal. Yes
Password The password you use to sign in to the web portal. Yes
Field Description Required Name The name of the connection. The name can be anything, as long as it is unique.
Tip The name that you provide here is the name you have to select in the Microsoft SSRS/PBRS connection field, when adding the Technical Lineage for SSRS-PBRS capability to the Edge site.
Yes
Description The description of the connection. No
Vault The vault where you store your data source values. No
Microsoft SSRS-PBRS URL The URL to the server's web portal. By default, the URL is http://<computer-name>/reports. For example, "http://1.23.45.678/PowerBIReports".
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Username The username you use to sign in to the web portal.
Tip If you use NTLM authentication, your username also contains the NTLM domain name. For example
MyDomain\\username.How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Password The password you use to sign in to the web portal.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
- Click Create.
What's next?
Add the Technical Lineage for SSRS-PBRS capability to the Edge site.
-
Create a Power BI connection.
To retrieve data from Power BI, you have to connect to Power BI via the Edge site.
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage Edge sites global permission.
- You have a global role that has the Manage connections and capabilities global permission.
- You have a resource role with the Configure external system resource permission, for example, Owner.
- You have the necessary Power BI permissions.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
-
In the Connections section, click Create Connection.
The Connection settings page appears. -
In the Connections section, click Create Connection.
The Create Connection dialog box appears. - Select Power BI connection.
- Enter the required information.
Field Description Required Connection settings This section contains general information about the connection. Name The name of the connection. The name can be anything, as long as it is unique.
Tip The name that you provide here is the name you have to select in the Power BI connection field, when adding the Technical Lineage for Power BI capability to the Edge site.
Yes
Description The description of the connection. No
Connection provider The type of connection.
Select Power BI connection.
Yes
Connection parameters This section contains connection authentication information. Tenant Domain The domain associated with the Microsoft Azure tenant. This domain is either a default domain or a custom domain. For example, collibrapowerbi.onmicrosoft.com.
Note Usually, you can find a list of Power BI tenant or server domains in your Azure Active Directory or in the top right menu.
Yes
Authentication type The authentication type for your connection to Power BI. Enter one of the following:
- Service Principal
- Resource Owner Password Credentials
Yes
Application ID The unique ID of the Microsoft Azure Application (client) ID. Yes
Username The email address of your Azure Active Directory user.
This field only applies if you entered Resource Owner Password Credentials in the Authentication type field.
No
Password/Secret key Your password (if you entered Resource Owner Password Credentials in the Authentication type field) or your secret key (if you entered Service Principal in the Authentication type field), for your Azure Active Directory user.
Yes
Custom certificate Important This field will soon be deprecated. For guidance on uploading a custom certificate to an Edge site, refer to the "Connect to a proxy server if needed" content in the "Before you begin" section of this topic.
Optional field for uploading a custom server certificate, to connect to
Click Upload and search for your custom server certificate.
You don't need to add the certificate to the Java Truststore. Edge stores the certificate as it does any other input parameter, and automatically uses it when connecting to
NoField Description Required Name The name of the connection. The name can be anything, as long as it is unique.
Tip The name that you provide here is the name you have to select in the Power BI connection field, when adding the Technical Lineage for Power BI capability to the Edge site.
Yes
Description The description of the connection. No
Vault The vault where you store your data source values. No
Tenant Domain The domain associated with the Microsoft Azure tenant. This domain is either a default domain or a custom domain. For example, collibrapowerbi.onmicrosoft.com.
Note Usually, you can find a list of Power BI tenant or server domains in your Azure Active Directory or in the top right menu.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Authentication type The authentication type for your connection to Power BI. Enter one of the following:
- Service Principal
- Resource Owner Password Credentials
Yes
Application ID The unique ID of the Microsoft Azure Application (client) ID.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Username The email address of your Azure Active Directory user.
This field only applies if you entered Resource Owner Password Credentials in the Authentication type field.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
No
Password/Secret key Your password (if you entered Resource Owner Password Credentials in the Authentication type field) or your secret key (if you entered Service Principal in the Authentication type field), for your Azure Active Directory user.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Custom certificate Important This field will soon be deprecated. For guidance on uploading a custom certificate to an Edge site, refer to the "Connect to a proxy server if needed" content in the "Before you begin" section of this topic.
Optional field for uploading a custom server certificate, to connect to
Click Upload and search for your custom server certificate.
You don't need to add the certificate to the Java Truststore. Edge stores the certificate as it does any other input parameter, and automatically uses it when connecting to
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
No - Click Create.
What's next?
Add the Technical Lineage for Power BI capability to the Edge site.
-
Create a MicroStrategy connection.
To retrieve data from MicroStrategy, you have to connect to MicroStrategy via the Edge site.
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage Edge sites global permission.
- You have a global role that has the Manage connections and capabilities global permission.
- You have a resource role with the Configure external system resource permission, for example, Owner.
- You have the necessary MicroStrategy permissions.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
-
In the Connections section, click Create Connection.
The Connection settings page appears. -
In the Connections section, click Create Connection.
The Create Connection dialog box appears. - Select MicroStrategy connection.
- Enter the required information.
Field Description Required Connection settings This section contains general information about the connection. Name The name of the connection. The name can be anything, as long as it is unique.
Tip The name that you provide here is the name you have to select in the MicroStrategy connection field, when adding the Technical Lineage for MicroStrategy capability to the Edge site.
Yes
Description The description of the connection. No
Connection provider The type of connection.
Select MicroStrategy connection.
Yes
Connection parameters This section contains connection authentication information. URL The URL of your MicroStrategy Intelligence Server.
Yes
Authentication type The authentication type for your connection to MicroStrategy.
Yes
Username The email address of your Azure Active Directory user.
This field only applies if you entered Resource Owner Password Credentials in the Authentication type field.
No
Password/Secret key Your password (if you entered Resource Owner Password Credentials in the Authentication type field) or your secret key (if you entered Service Principal in the Authentication type field), for your Azure Active Directory user.
Yes
Field Description Required Name The name of the connection. The name can be anything, as long as it is unique.
Tip The name that you provide here is the name you have to select in the MicroStrategy connection field, when adding the Technical Lineage for MicroStrategy capability to the Edge site.
Yes
Description The description of the connection. No
Vault The vault where you store your data source values. No
MicroStrategy URL
The URL of your MicroStrategy Intelligence Server.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Username The email address of your Azure Active Directory user.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Password Your password for your Azure Active Directory user.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
- Click Create.
What's next?
Add the Technical Lineage for MicroStrategy capability to the Edge site.
-
Create a SAP Analytics Cloud connection.
To retrieve data from SAP Analytics Cloud, you have to connect to SAP Datasphere Catalog via the Edge site.
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage Edge sites global permission.
- You have a global role that has the Manage connections and capabilities global permission.
- You have a resource role with the Configure external system resource permission, for example, Owner.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
-
In the Connections section, click Create Connection.
The Connection settings page appears. -
In the Connections section, click Create Connection.
The Create Connection dialog box appears. - Select SAP Datasphere Catalog connection.
- Enter the required information.
Field Description Required Connection settings This section contains general information about the connection. Name The name of the connection. The name can be anything, as long as it is unique.
Tip The name that you provide here is the name you have to select in the SAP Datasphere connection field, when adding the SAP Datasphere synchronization capability or the Technical Lineage for SAP Analytics Cloud capability to the Edge site.
Yes
Description The description of the connection. No
Connection provider The type of connection.
Select SAP Datasphere Catalog connection
Yes
Connection parameters This section contains connection authentication information. SAP Datasphere Catalog URL The URL to the SAP Datasphere tenant where you have configured the SAP Datasphere Catalog.
Yes
Token URL The token URL of your OAuth client.
Show me how to find the token URL- In SAP, toward the bottom of the SAP Datasphere homepage, click System > Administration.
- Click App Integration.

- In the OAuth Clients section, you'll find the token URL.
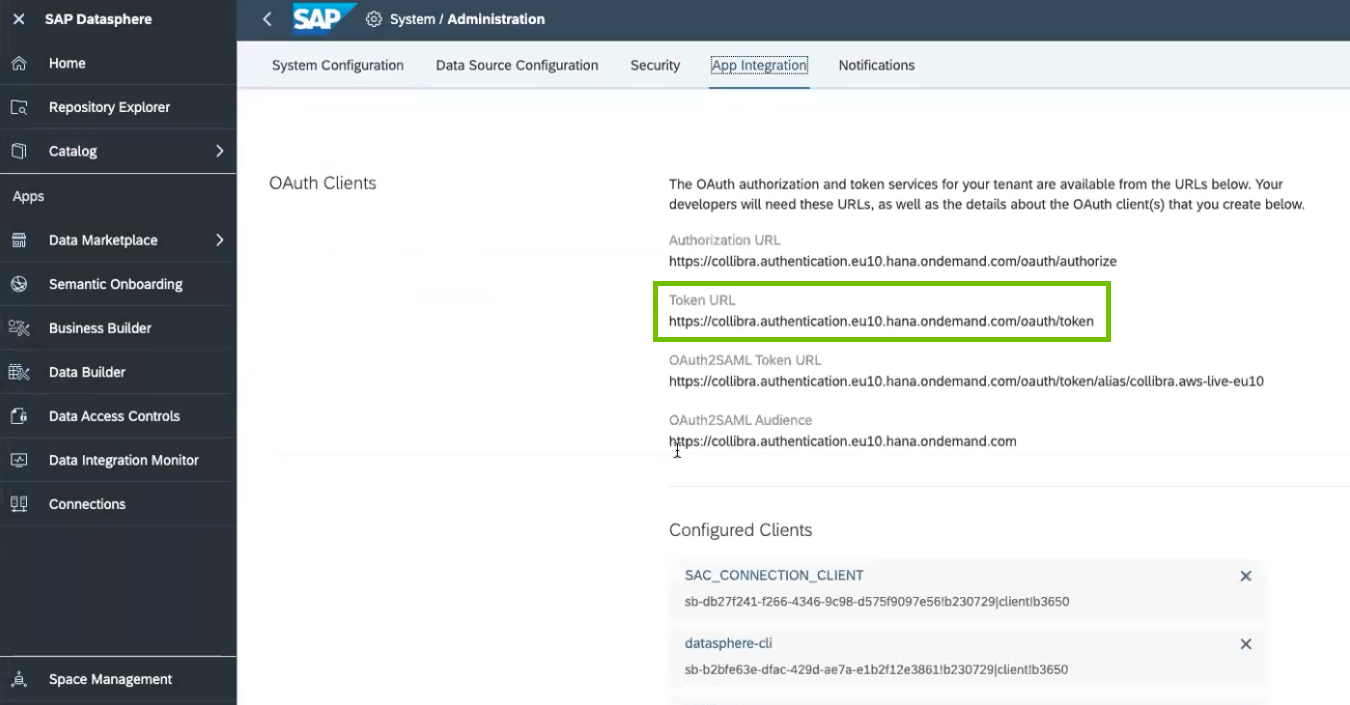
Yes
Client ID The Client ID of your OAuth client.
Show me how to find the client ID- In SAP, toward the bottom of the SAP Datasphere homepage, click System > Administration.
- Click App Integration.
- In the OAuth Clients section, scroll down to the Configured Clients. Client IDs start with "sb".
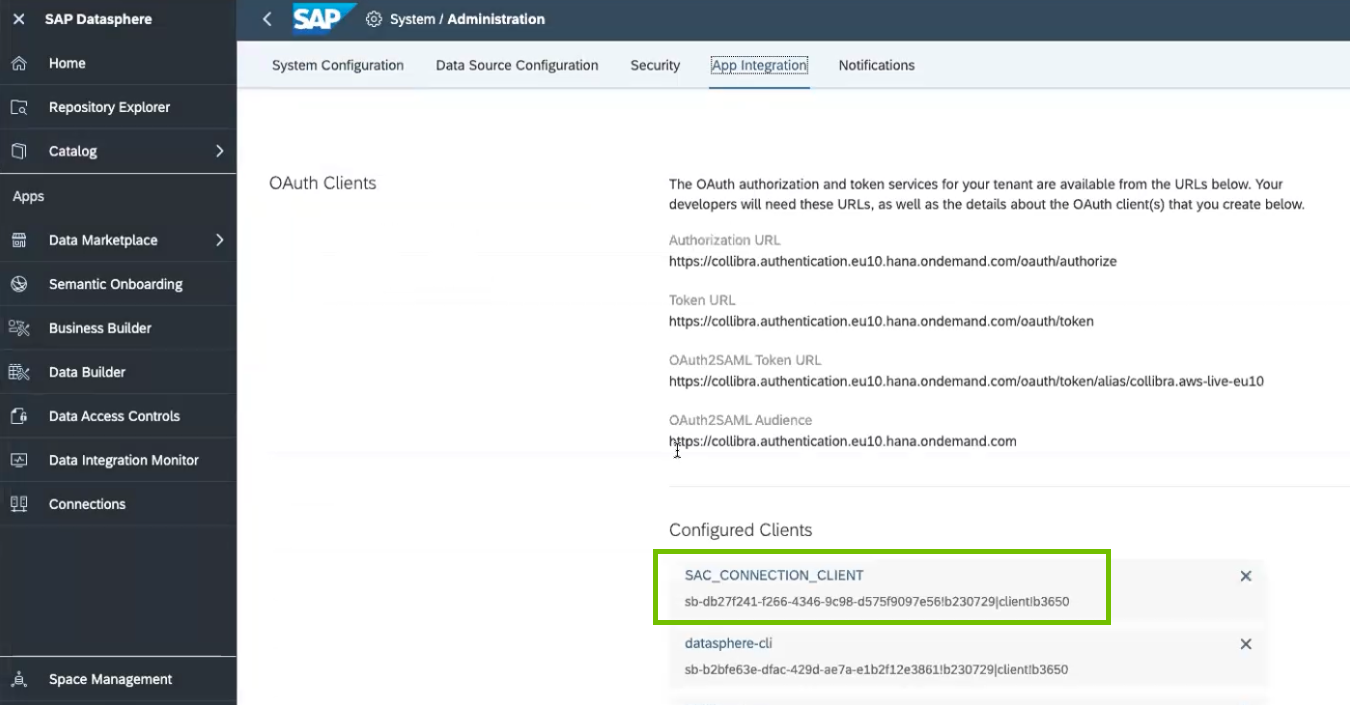
Yes
Client secret key The secret of your OAuth client. The secret key is used to generate a token to access the SAP Datasphere Catalog API.
Yes
Field Description Required Name The name of the connection. The name can be anything, as long as it is unique.
Tip The name that you provide here is the name you have to select in the SAP Datasphere connection field, when adding the SAP Datasphere synchronization capability or the Technical Lineage for SAP Analytics Cloud capability to the Edge site.
Yes
Description The description of the connection. No
Vault The vault where you store your data source values. No
SAP Datasphere Catalog URL The URL to the SAP Datasphere tenant where you have configured the Datasphere Catalog.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Token URL The token URL of your OAuth client.
Show me how to find the token URL- In SAP, toward the bottom of the SAP Datasphere homepage, click System > Administration.
- Click App Integration.
- In the OAuth Clients section, you'll find the token URL.
Yes
Client ID The Client ID of your OAuth client.
Show me how to find the client ID- In SAP, toward the bottom of the SAP Datasphere homepage, click System > Administration.
- Click App Integration.
- In the OAuth Clients section, scroll down to the Configured Clients. Client IDs start with "sb".
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Client secret key The secret of your OAuth client. The secret key is used to generate a token to access the SAP Datasphere Catalog API.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
- In SAP, toward the bottom of the SAP Datasphere homepage, click System > Administration.
- Click Create.
What's next?
Add the Technical Lineage for SAP Analytics Cloud capability to the Edge site.
-
Create a Matillion connection.
For Collibra Data Lineage to connect to and retrieve metadata from Matillion, create a Matillion connection.
Before you begin
- To create and use Matillion connection, use Collibra Data Intelligence Platform 2023.03 or later.
- Create an Edge site on K3S.
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage Edge sites global permission.
- You have a global role that has the Manage connections and capabilities global permission.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
-
In the Connections section, click Create Connection.
The Connection settings page appears. -
In the Connections section, click Create Connection.
The Create Connection dialog box appears. - Select Matillion connection.
- Enter the connection information.
Field Description Required Connection settings This section contains the settings to connect to your data source. NameThe name of the connection. Yes
DescriptionThe description of the connection. This field is also visible when you register content. No
Connection providerThe connection provider, which determines the available connection parameters.
Select Matillion connection.
Yes
Connection parameters This section contains general settings to connect to your data source. Matillion URLThe URL of your Matillion environment. For example, https://<domain name>orhttps://<IP address>. Yes
Authentication TypeThe authentication details for signing in to Matillion. You can select one of the following values:
Credentials- Use the username and password authentication type.
Token- Use the token-based authentication type.
Yes
UsernameThe username that you use to sign in to Matillion.
This field is required if you set the Authentication type field to Credentials.PasswordThe password that you use to sign in to Matillion.
Tip You can select To be encrypted by Edge management server or Encrypted with public key to indicate the encryption method.
Yes
Field Description Required Name
The name of the connection. Yes
Description
The description of the connection. This field is also visible when you register content. No
Vault The vault where you store your data source values. No
Matillion URL
The URL of your Matillion environment. For example,
https://<domain name>orhttps://<IP address>.How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
Authentication Type
The authentication details for signing in to Matillion. You can select one of the following values:
Credentials- Use the username and password authentication type.
Token- Use the token-based authentication type.
Yes
Username
The username that you use to sign in to Matillion.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
This field is required if you set the Authentication type field to Credentials.Password/Token secret
The password that you use to sign in to Matillion.
Tip You can select To be encrypted by Edge management server or Encrypted with public key to indicate the encryption method.
How to use your vault...To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the query value to identify the secret in your vault.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Engine Type Select one of the following:
- Key Value
- Database
Engine Path The engine path to your vault where the value is stored. Secret Path The secret path to your vault where the value is stored. Field The name of the field to your vault where the value is stored.
Note Only available if you selected Key Value in the Secret Engine Type field.
Role The role specified in the Database engine.
Note Only available if you selected Database in the Secret Engine Type field.
Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Vault Name The name of your Azure Key Vault in your Azure Key Vault service where the value is stored. Secret Name The name of the secret in your vault where the value is stored. Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the required information:
Name Description Secret Name The name of the secret in your vault where the value is stored. Field If the secret stored in your AWS Secrets Manager is a JSON value, for example
{"pass1": "my-password", "pass2": "my-password2"}, then you need to specify the Field to point to the exact JSON value that should be used. For example,Secret Name: edge-db-customer; Field: pass.Note If the secret stored in your AWS Secrets Manager is a plain string value, for example
my-password, then you do not need to specify the Field.Example
To use your vault, do the following:- In the Value Type field, select Vault Key.
- Enter the name of the secret in your vault where the value is stored.
Example
Yes
- Click Create.
-
Create a Shared Storage connection.
A Shared Storage connection allows you to grant your capabilities access to files from a shared folder. This connection is especially useful for capabilities with large files, as you don't need to manually upload the files directly to Edge. Instead, you define the path to the files when creating the new connection.
Before you begin
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage Edge sites global permission.
- You have a global role that has the Manage connections and capabilities global permission.
Steps
- Run one of the following commands in the Edge CLI tool included with the Edge site installer to create a new shared folder and upload your source files:Note If your Edge site is installed on a bundled k3s cluster, you must add
sudoto the beginning of any command run in the Edge CLI. For example:sudo ./edgecli objects folder-upload -h
- Show me how to upload a folder with source files...Upload a shared folder which contains multiple data source files:
./edgecli objects folder-upload --source <source-string> --target <target-string> --ttlSeconds <time>
Key Definition <source-string> The data source file you want to upload for your Shared Storage connection. <target-string> The folder in your Edge site where you want to store the shared folder and files. Note This folder does not have to already exist in your Edge site. If it does not, a folder with the name entered here will be created in your Edge site, containing the folder and files you have uploaded.<time> (optional) The number of seconds that the uploaded files will be available before being evicted, the default is 15552000 seconds (180 days). Example
Let's say we have a shared folder /tmp/folder-a, with the following directory structure:
- /tmp/folder-a/file-a.txt
- /tmp/folder-a/sub-folder-1/file-b.txt
- /tmp/folder-a/sub-folder-1/file-c.txt
Let's upload everything in /tmp/folder-a to a shared folder named shared-folder-1. To do so, run the following command:
./edgecli objects folder-upload \ --source /tmp/folder-a \ --target shared-folder-1 \ --ttlSeconds 3600
The resulting output is the following:
Uploaded 3 files: target=shared-folder-1 key=file-a.txt: size=14 ttlSeconds=3600 target=shared-folder-1 key=sub-folder-1/file-b.txt: size=14 ttlSeconds=3600 target=shared-folder-1 key=sub-folder-1/file-c.txt: size=14 ttlSeconds=3600 Total of 42 bytes uploaded
Note- If you repeat the command, all existing objects that are present in the shared folder will be overwritten.
- If you remove some files in the source directory, they will not be removed from the shared folder.
- If you want file parity with your source folder, use the
folder-deletecommand, and then use thefolder-uploadcommand. - If you need help with the command parameters, run the help command in the Edge CLI.
./edgecli objects folder-upload -h
- Show me how to upload a single source file...Upload a single shared data source file:
./edgecli objects file-upload --source <source-string> --target <target-string> --key <key-string> --ttlSeconds <time>
Key Definition <source-string> The data source file you want to upload for your Shared Storage connection. <target-string> The folder in your Edge site where you want to store the shared file. Note This folder does not have to already exist in your Edge site. If it does not, a folder with the name entered here will be created in your Edge site, containing the file you have uploaded.<key-string> (optional) The path of a specific file within a folder or nested within multiple folders. For example, you only want to upload the myFile.txt file, which is in the myFolders folder. If you do not specify this property, it will default to the file name.
<time> (optional) The number of seconds that the uploaded file will be available before being evicted, the default is 15552000 seconds (180 days). Example
Let's say we have a shared file called
/tmp/data-source-file-to-upload/a.txt \, and we want to upload it to a folder calledshared-folder-2in our Edge site.To do so, run the following command:
./edgecli objects file-upload --source /tmp/data-source-file-to-upload/a.txt \ --target shared-folder-2 \ --key rekeyed-a.txt \ --ttlSeconds 8000
The resulting output is the following:
Uploaded 1 file: target=shared-folder-2 key=rekeyed-a.txt: size=14 ttlSeconds=8000
Note- If you repeat the command, all existing objects that are present in the shared folder will be overwritten.
- If you remove the file in the source directory, it will not be removed from the shared folder.
- If you want file parity with your source folder, use the
folder-deletecommand, and then use thefolder-uploadcommand. - If you need help with the command parameters, run the help command in the Edge CLI.
./edgecli objects file-upload -h
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
- Click Create Connection.
The Connection settings page appears. -
In the Connections section, click Create Connection.
The Create Connection dialog box opens. - Select Shared storage connection.
The Create Connection dialog box for Shared storage connection opens. -
Enter the connection information.
Field Description Required Name The name of the connection. Yes
Description The description of the connection. No
Connection provider Select Shared Storage Connection. Yes
Folder Enter the name of your folder created in step 1. Subfolders are not allowed.
Note Edge lists the location of this file to the right of this field. Yes
Field Description Required Name The name of the connection. Yes
Description The description of the connection. No
Folder Enter the name of your folder created in step 1. Subfolders are not allowed.
Note Edge lists the location of this file to the right of this field. Yes
- Click Create.
-
Prepare the SQL directory.
To create technical lineage for JDBC data sources by using the Shared Storage Connection, you must provide SQL files that include your SQL queries. Collibra Data Lineage processes the metadata based on your queries to create the technical lineage.
For more information about the connection types for different data sources, go to Supported data sources for technical lineage.
Steps
-
Create your SQL files. Ensure that the following requirements are met for the SQL files:
- The SQL files must be UTF-8 encoded.
- The SQL files can't have white spaces in their names.
- For better ingestion, include one SQL statement in one SQL file.
- Collibra Data Lineage processes the SQL files in alphabetical order. The SQL files that include the Data Definition Language (DDL) statements must be processed before the SQL files that include the Data Manipulation Language (DML) statements. To ensure this order, name the SQL files such that those containing DDL statements come before those containing DML statements alphabetically.
- The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. For more information, go to Add a technical lineage capability to your Edge site and Automatic stitching for technical lineage.
- For Collibra Data Lineage to correctly highlight the transformation logic in the Source code pane, we strongly recommend that your SQL files have Unix line endings. Non-Unix line endings, for example Carriage Return (CR) and Line Feed (LF) line breaks, do not influence the extracted lineage and can result in incorrect highlighting.
For more information, go to Supported SQL syntax.
- Store the SQL files in the folder that you created when you created the Shared Storage connection.
Example 1 SQL statements do not include schema and database names
This example shows the SQL files that include the queries on the
PersonsandJobInformationtables and theJobTitleViewview.- The ddl-persons.sql file
CREATE TABLE Persons ( PersonID int, LastName varchar(255), FirstName varchar(255), Address varchar(255), City varchar(255) ); - The ddl-jobinformation.sql file
CREATE TABLE JobInformation ( PersonID int, Department varchar(255), Title varchar(255) ); - The view-jobtitle.sql file
CREATE VIEW JobTitleView AS SELECT Persons.PersonID, Persons.FirstName, Persons.LastName, JobInformation.Title from Persons INNER JOIN JobInformation ON Persons.PersonID = JobInformation.PersonId
Example 2 SQL statements include schema and database names
This example shows SQL files that include the queries on the
PersonsandJobInformationtables and theJobTitleViewview. The SQL statements contain the database and schema names for each table and view, and Collibra Data Lineage uses them for stitching. The SQL files are named in a way that ensures the DDL statements are processed before the DML statement.- The ddl-db1-schemaA-persons.sql file
CREATE TABLE DB1.SchemaA.Persons ( PersonID int, LastName varchar(255), FirstName varchar(255), Address varchar(255), City varchar(255) ); - The ddl-db2-schemaB-jobinformation.sql file
CREATE TABLE DB2.SchemaB.JobInformation ( PersonID int, Department varchar(255), Title varchar(255) ); - The view-db2-schemaC-jobtitleview.sql file
CREATE VIEW DB2.SchemaC.JobTitleView AS SELECT Persons.PersonID, Persons.FirstName, Persons.LastName, JobInformation.Title from DB1.SchemaA.Persons INNER JOIN DB2.SchemaB.JobInformation ON Persons.PersonID = JobInformation.PersonId
-
-
Prepare the data source files.
Prepare the data source files and store the data source files in the folder that you created when you created the Shared Storage connection in the previous step.
Prerequisites
You have IBM InfoSphere Information Server version 11.5 or newer.
Steps
-
Export the DataStage project files (DSX) for which you want to create a technical lineage. If you want to include runtime parameters in parameter set files in the technical lineage, ensure to export DataStage files with executables.
-
Store the DataStage files in your Shared Storage connection folder.
Note If you use Collibra Data Intelligence Platform 2024.05 or newer, ensure that you use the Edge CLI tool for creating the Shared Storage connection and storing files in the Shared Storage connection folder. Go to the following Create a Shared Storage connection step for detailed instructions. For more information, go to Edge Command Line Interface (CLI). -
Optionally, if your DataStage project uses environment variables, manually export the environment files (ENV).
-
Give the environment files the same name as the DataStage project files. For example, if your project file is named datastage-project-1.dmx, name your environment file datastage-project-1.env.
-
Store the environment files in the same Shared Storage connection folder.
Important- Collibra Data Lineage only supports DSX and ENV files.
- You can have one DSX file per DataStage project.
- You can have more than one DSX file in the Shared Storage connection folder.
- You can have one or none ENV file per DSX file.
- The name of the DSX file and the ENV file has to be the same.
-
-
Prepare the data source files.
Prepare the data source files and store the data source files in the folder that you created when you created the Shared Storage connection in the previous step.
Steps
- In the dbt Core environment, locate the target/ directory of your dbt project. The target/ directory must contain the manifest JSON file and compiled SQL files. This directory is created by running the
dbt runanddbt compilecommands. - If the target/ directory does not exist or the directory does not contain the manifest JSON file or compiled SQL files, complete the following steps to create the directory and the required files:
- Set the profile of your dbt Core to the environment that you want to retrieve the lineage information from.
- Use the
dbt compilecommand to generate SQL files. For details, go to About dbt compile command and Manifest JSON file in dbt documentation.
-
Store the target/ directory in your Shared Storage connection folder and ensure that you maintain the folder structure. Your Shared Storage connection folder must contain all files and subdirectories, such as target/manifest.json and target/compiled/project-name/models/.
Note If you use Collibra Data Intelligence Platform 2024.05 or newer, ensure that you use the Edge CLI tool for creating the Shared Storage connection and storing files in the Shared Storage connection folder. Go to the following Create a Shared Storage connection step for detailed instructions. For more information, go to Edge Command Line Interface (CLI).
- In the dbt Core environment, locate the target/ directory of your dbt project. The target/ directory must contain the manifest JSON file and compiled SQL files. This directory is created by running the
-
Prepare the data source files.Prepare the data source files and store the data source files in the folder that you created when you created the Shared Storage connection in the previous step.
Prerequisites
You have Informatica PowerCenter version 9.6 or newer.Steps
- Export the Informatica objects or repository for which you want to create a technical lineage to the Shared Storage connection folder.
Make sure to export all objects, parameter files, mappings and sessions at the same time.Manually exporting Informatica objects in Informatica PowerCenter 10.0.0.
- Open Informatica PowerCenter Repository Manager.
- Connect to your Informatica repository.
- In the navigation panel, navigate to the workflow that contains the Informatica objects that you want to export.
- Right-click on the workflow and click Dependencies.
- In the Dependencies dialog box, do the following:
- Select Primary/Foreign Key dependencies.
- Select Global Shortcut dependencies.
- In the Object Types selector, select all object types except User-Defined.
- Click OK.
The Dependencies dialog box closes.
A dialog box with all Informatica objects appears. - Select all objects.
- In the toolbar, click
 (Export to XML).
(Export to XML). 
- Save the resulting XML files in your local folder.
Exporting Informatica repository objects in Informatica PowerCenter via command line.- In the Informatica PowerCenter Client or PowerCenter Services bin directories, open pmrep.
- Export Informatica PowerCenter repository objects.
Note Make sure that you export the same Informatica PowerCenter repository objects as during a manual export.
- Save the resulting XML files in your local folder.
Note- If your folder contains previous versions of the parameter files, objects might be duplicated across different file versions. The duplicated objects cause CollibraData Lineage to ignore some transformations, resulting in missing lineage and error messages. For example, if a parameter file is exported after a column was added to a table, duplicated objects exist if the previous version of the parameter file remains in the folder. To avoid missing lineage, export all objects and parameter files at the same time.
- All XML and parameter files, for example PAR, TXT or PRM files in this folder and its subfolders are taken into account when you create a technical lineage, but Collibra Data Lineage only shows a technical lineage for workflows that have mappings with sources, transformations and targets. Collibra supports the most common Informatica PowerCenter transformations. For more information, see the Informatica PowerCenter documentation.
- When you export a workflow, ensure that all dependencies are included in the same export file. This applies whether you export the XML file manually or by using the command line. If any dependencies are missing for a workflow, the lineage information for the workflow will be missing in the technical lineage.
- A technical lineage is created when the following tags are present in your XML file:
- <REPOSITORY>
- <FOLDER>
- <SOURCE> / <TARGET>
- <SESSION>
- <MAPPING>
- <TRANSFORMATION> (within a <MAPPING> tag)
- If parameters are missing from the parameter files, the UNRESOLVED PARAMETERS analyze error will be displayed in the analysis results in the Sources tab page. For details, go to Analyze errors and possible solutions in Technical lineage Sources tab page.
In the Shared Storage connection folder, create a folder named techlin-param and put the parameter files in the techlin-param folder.
Note If you use Collibra Data Intelligence Platform 2024.05 or newer, ensure that you use the Edge CLI tool for creating the Shared Storage connection and storing files in the Shared Storage connection folder. Go to the following Create a Shared Storage connection step for detailed instructions. For more information, go to Edge Command Line Interface (CLI).
- Export the Informatica objects or repository for which you want to create a technical lineage to the Shared Storage connection folder.
Make sure to export all objects, parameter files, mappings and sessions at the same time.
-
Prepare the data source files.
Prepare the data source files and store the data source files in the folder that you created when you created the Shared Storage connection in the previous step.
Prerequisites
- You have SQL Server Integration Services 2012 or newer with package format version 6 or newer.
- You have Microsoft Visual Studio version 2012 or newer.
Steps
-
Export the SSIS files for which you want to create a technical lineage.
Tip You can export them directly from the SQL Server Integration Services repository or via Microsoft Visual Studio. For more information, see the SQL Server Integration Services documentation. -
Store the SSIS files to
- SSIS package files (DTSX), containing the SQL Server Integration Services source code.
- Connection manager files (CONMGR), containing environment and connection information.
- Parameter files (PARAMS), if applicable.
Note- If you use Collibra Data Intelligence Platform 2024.05 or newer, ensure that you use the Edge CLI tool for creating the Shared Storage connection and storing files in the Shared Storage connection folder. Go to the following Create a Shared Storage connection step for detailed instructions. For more information, go to Edge Command Line Interface (CLI).
- All files in this folder and subfolders are taken into account when you create a technical lineage.
- Not all SSIS files are processed and shown in the technical lineage.
-
Create a Shared Storage connection.
A Shared Storage connection allows you to grant your capabilities access to files from a shared folder. This connection is especially useful for capabilities with large files, as you don't need to manually upload the files directly to Edge. Instead, you define the path to the files when creating the new connection.
Before you begin
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage Edge sites global permission.
- You have a global role that has the Manage connections and capabilities global permission.
Steps
- Run one of the following commands in the Edge CLI tool included with the Edge site installer to create a new shared folder and upload your source files:Note If your Edge site is installed on a bundled k3s cluster, you must add
sudoto the beginning of any command run in the Edge CLI. For example:sudo ./edgecli objects folder-upload -h
- Show me how to upload a folder with source files...Upload a shared folder which contains multiple data source files:
./edgecli objects folder-upload --source <source-string> --target <target-string> --ttlSeconds <time>
Key Definition <source-string> The data source file you want to upload for your Shared Storage connection. <target-string> The folder in your Edge site where you want to store the shared folder and files. Note This folder does not have to already exist in your Edge site. If it does not, a folder with the name entered here will be created in your Edge site, containing the folder and files you have uploaded.<time> (optional) The number of seconds that the uploaded files will be available before being evicted, the default is 15552000 seconds (180 days). Example
Let's say we have a shared folder /tmp/folder-a, with the following directory structure:
- /tmp/folder-a/file-a.txt
- /tmp/folder-a/sub-folder-1/file-b.txt
- /tmp/folder-a/sub-folder-1/file-c.txt
Let's upload everything in /tmp/folder-a to a shared folder named shared-folder-1. To do so, run the following command:
./edgecli objects folder-upload \ --source /tmp/folder-a \ --target shared-folder-1 \ --ttlSeconds 3600
The resulting output is the following:
Uploaded 3 files: target=shared-folder-1 key=file-a.txt: size=14 ttlSeconds=3600 target=shared-folder-1 key=sub-folder-1/file-b.txt: size=14 ttlSeconds=3600 target=shared-folder-1 key=sub-folder-1/file-c.txt: size=14 ttlSeconds=3600 Total of 42 bytes uploaded
Note- If you repeat the command, all existing objects that are present in the shared folder will be overwritten.
- If you remove some files in the source directory, they will not be removed from the shared folder.
- If you want file parity with your source folder, use the
folder-deletecommand, and then use thefolder-uploadcommand. - If you need help with the command parameters, run the help command in the Edge CLI.
./edgecli objects folder-upload -h
- Show me how to upload a single source file...Upload a single shared data source file:
./edgecli objects file-upload --source <source-string> --target <target-string> --key <key-string> --ttlSeconds <time>
Key Definition <source-string> The data source file you want to upload for your Shared Storage connection. <target-string> The folder in your Edge site where you want to store the shared file. Note This folder does not have to already exist in your Edge site. If it does not, a folder with the name entered here will be created in your Edge site, containing the file you have uploaded.<key-string> (optional) The path of a specific file within a folder or nested within multiple folders. For example, you only want to upload the myFile.txt file, which is in the myFolders folder. If you do not specify this property, it will default to the file name.
<time> (optional) The number of seconds that the uploaded file will be available before being evicted, the default is 15552000 seconds (180 days). Example
Let's say we have a shared file called
/tmp/data-source-file-to-upload/a.txt \, and we want to upload it to a folder calledshared-folder-2in our Edge site.To do so, run the following command:
./edgecli objects file-upload --source /tmp/data-source-file-to-upload/a.txt \ --target shared-folder-2 \ --key rekeyed-a.txt \ --ttlSeconds 8000
The resulting output is the following:
Uploaded 1 file: target=shared-folder-2 key=rekeyed-a.txt: size=14 ttlSeconds=8000
Note- If you repeat the command, all existing objects that are present in the shared folder will be overwritten.
- If you remove the file in the source directory, it will not be removed from the shared folder.
- If you want file parity with your source folder, use the
folder-deletecommand, and then use thefolder-uploadcommand. - If you need help with the command parameters, run the help command in the Edge CLI.
./edgecli objects file-upload -h
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the Edge site overview, click the name of an Edge site.
The Edge site page appears.
-
On the main toolbar, click
- Click Create Connection.
The Connection settings page appears. -
In the Connections section, click Create Connection.
The Create Connection dialog box opens. - Select Shared storage connection.
The Create Connection dialog box for Shared storage connection opens. -
Enter the connection information.
Field Description Required Name The name of the connection. Yes
Description The description of the connection. No
Connection provider Select Shared Storage Connection. Yes
Folder Enter the name of your folder created in step 1. Subfolders are not allowed.
Note Edge lists the location of this file to the right of this field. Yes
Field Description Required Name The name of the connection. Yes
Description The description of the connection. No
Folder Enter the name of your folder created in step 1. Subfolders are not allowed.
Note Edge lists the location of this file to the right of this field. Yes
- Click Create.
-
Which custom lineage definition option are you using?
- Single-file definition
You have to define the technical lineage in a single JSON file. Use the following format and code examples to create the JSON file, and then store the file in the folder that you created when you created the Shared Storage connection, earlier in this procedure.
JSON file formatting for the single-file definition optionIf you opt for the single-file definition option, you use a lineage.json file to define the lineage between two or more data objects, and optionally include transformations details to create the custom technical lineage.
The following sections in the JSON file define different parts in the resulting Collibra technical lineage graph:
tree, which defines the data object hierarchy. The data objects are shown as nodes in the technical lineage graph.lineages, which defines the lineage relation. The lineage relations are shown as edges in the technical lineage graph. The edges represent the data flow from a source to a target.codebase_files, which points to the source code files that include transformation details.
To create a simple custom technical lineage, you need to include
assetsandlineagessections in your JSON file. You can add the transformation code in thelineagessection.To create an advanced custom technical lineage, you need to include
assets,lineagesandcodebase_filessections in your JSON file. You add references to the transformation code in source code files in thecodebase_filessection.Transformation code in both simple and advanced custom technical lineages is shown in the source code pane at the bottom part of the technical lineage graph.
Requirements and restrictions
The source code files must be in the same directory as the lineage.json file. Otherwise, an error occurs indicating that the lineage harvester cannot find the source code files.
Sections
Sections
Description version
The version of the JSON architecture. Specify the value of
1.0, which is the only supported version.This section contains tree definitions of data objects between which lineages can be defined. The data objects are systems, databases, schemas, tables, views, columns, dashboards and reports.
Each node of a tree contains the name, type and optionally children or leaves properties which form a hierarchy of data objects. You must define a node only once in this section. With the nested tree format, you can reuse the properties of one node for multiple children. For example, you can define a database once and use the
childrenarray to define multiple tables in the database.Tip Usually, the structure you map is the following: system > database > schema > table > column. The system is optional, unless the
useCollibraSystemNameproperty is set totruein your lineage harvester configuration file. Collibra Data Lineage can stitch these data objects to assets in Data Catalog. However, you can also map custom objects, for example dashboards and reports. Custom objects cannot be stitched to assets in Data Catalog.Important If the
useCollibraSystemNameproperty is set tofalsein your lineage harvester configuration file, do not specify the system data object in this section, or else stitching will fail.lineages This section contains the path from a source to a target and defines the transformation code or transformation references to be processed by the Collibra Data Lineage service.
Important If the
useCollibraSystemNameproperty is set tofalsein your lineage harvester configuration file, do not specify the system data object in this section, or else stitching will fail.codebase_files
This optional section defines the reference to source code files. Store the source code files that contain the transformation code in the same directory as the lineage.json file.
Include this section only when you create an advanced custom technical lineage.
tree section properties
Properties
Description nameThe name of your data object. Specify this property with the system name, database name, schema name, table name, view name or column name.
The following rules apply when you specify this property:
- The names are case sensitive.
- The names of children and leaves can be identical if the children and leaves with the same names are in different parent nodes.
typeThe type of your data object. You can specify one of the following options:
system,database,schema,table,view,column,dashboardorreport.If theuseCollibraSystemNameproperty in your lineage harvester configuration file is set totrue, the system data object is used to stitch to the System asset in Data Catalog. If theuseCollibraSystemNameproperty is set tofalsein your lineage harvester configuration file, do not specify the system data object in this section, or else stitching will fail.childrenThe sub-objects that have a hierarchical relation to the defined data object.
Each child can contain
childrenproperties, except for the penultimate child. The penultimatechildrenproperty must contain theleavesproperty. Theleavesproperty cannot contain achildrenproperty.For example, you can use the
childrenproperty to define a table and use theleavesproperties to define columns that have a relation to the table node.Each child and leave have the
nameandtypeproperties and the optionalcatalog_fullname,catalog_domain_id,catalog_asset_type_nameandcatalog_asset_type_uuidproperties.leavesThe sub-objects of an object that is defined in a
childrenproperty, but cannot have sub-objects of their own.A technical lineage is defined as relations between leaf nodes of the tree.
The value of the
typeproperty of theleavesproperty must becolumnorreport. Indirect and table-level technical lineages are not supported. For the workarounds to create a table level or indirect technical lineage, see Programming considerations.lineage section properties
Properties
Required Description src_pathYes The hierarchical path to the source data object. This data object is defined as a leaf in the
treesection.This property represents where the data comes from for a transformation.
trg_pathYes The hierarchical path to the target data object. This data object is defined as a leaf in the
treesection.This property represents where the data flows to.
<data objects>Yes An ordered array of data object names. This array is required to define the sub-objects of the
src_pathandtrg_pathproperties.Specify the array with the data object names that start from the top of the
treesection and finish at a leaf node.This example shows data objects that can be stitched: system > database > schema > table > column.
This example shows data objects that cannot be stitched: dashboard > report > column.
If theuseCollibraSystemNameproperty in your lineage harvester configuration file is set totrue, the system data object is used to stitch to the System asset in Data Catalog. If theuseCollibraSystemNameproperty is set tofalsein your lineage harvester configuration file, do not specify the system data object in this section, or else stitching will fail.mappingYes
Simple custom technical lineage only
The mapping name. This property specifies a name for the transformation code.
source_codeYes
Simple custom technical lineage only
The transformation code, which determines how the technical lineage is constructed.
The transformation code can be a descriptive string or a SQL statement that manipulates data.
mapping_refNo
Advanced custom technical lineage only
This property contains the name of the mapping reference to the transformation code in source code files. This property also contains the position and length of the transformation code to be highlighted in the technical lineage graph.
source_codeNo
Advanced custom technical lineage only
The name of the source code file that contains the transformation code. The transformation code can be a SQL statement, code that manipulates data or a descriptive string.
mappingNo
Advanced custom technical lineage only
The unique descriptor of a part of transformation code in a source code file that is in the same directory as the lineage.json file.
A source code file can contain different parts of transformation code that represent different data flows. This property indicates the referenced data flow.
The value of this property is the same as the value of the
mapping_refsproperty in thecodebase_filessection.codebase_posNo
Advanced custom technical lineage only
The positions indicate a string of the transformation code in a source code file to be highlighted in the bottom part of the Collibra technical lineage graph. The whole lines that include the transformation code are highlighted.
The string must be a subset of the string of the transformation code that is defined by the
pos_startandpos_lenproperties of themapping_refsproperty in thecodebase_filessection.pos_startNo
Advanced custom technical lineage only
The start position of the string of the transformation code to be highlighted. The start position is in characters, not bytes.
The value must be equal to or greater than the value of the
pos_startproperty of themapping_refsproperty in thecodebase_filessection.pos_lenNo
Advanced custom technical lineage only
The length of the string of the transformation code to be highlighted. The length is in characters, not bytes.
Specify a value in the following range:
- Equal to or greater than 1.
- Less than or equal to the length of the string that is defined by the
pos_lenproperty of themapping_refsproperty in the thecodebase_filessection.
For example, if you specify
"pos_start": 10and"pos_len": 160in thecodebase_filessection, specify a value for this property in the range of 0 - 149.codebase_files section properties
Properties
Description <source code path>The file path to source code files that contain the transformation code. The transformation code can be a SQL statement or code that manipulates data.
The mapping of the transformation code and the position of the transformation code that is shown in the bottom part of the technical lineage graph.
This property defines a string of the transformation code in the source code file to be shown in the technical lineage graph. The string must include the string that is defined by the
pos_startandpos_lenproperties of themappingproperty in thelineagesection.<mapping>The unique descriptor of a part of transformation code in a source code file that is in the same directory as the lineage.json file.
A source code file can contain different parts of transformation code that represent different data flows. This property indicates the referenced data flow.
The value must match the value of the
mappingproperty in thelineagesection.pos_startThe start position of the string of the transformation code. The start position is in characters, not bytes.
Specify a value in the following range:
- Equal to or greater than 0.
- Less than or equal to the value of the
pos_startproperty in themappingproperty in thelineagesection.
pos_lenThe length of the string of the transformation code. The length is in characters, not bytes.
Specify a value in the following range:
- Greater than or equal to 1.
- Less than or equal to the length of the source code file minus the start position.
For example, if you specify
"pos_start": 10and the file length is 160 characters, specify a value for this property in the range of 1 - 150.Programming considerations
Currently, there is no native support for indirect and table-level lineages. As a workaround, you can specify
"type": "column"and"name": "*"for theleavesproperty to create a table level or indirect technical lineage. With this specification, the indirect technical lineage is shown as a solid line instead of a dashed line in the Collibra technical lineage graph, and is always shown, regardless of whether or not the Show indirect dependencies option is enable or disabled.Example
For some example JSON files, go to Custom technical lineage JSON file examples.
Single file-definition JSON file examplesThis section shows some example lineage.json files for simple custom technical lineage and advanced custom technical lineage.
Each example can be used to generate technical lineage graphs in Collibra to represent the IOT_JSON and IOT_DEVICES_PER_COUNTRY tables with the following columns:
IOT_JSON
IOT_DEVICES_PER_COUNTRY CCA3
COUNTRY
DEVICE_ID
NUMBER_DEVICES
Example JSON file for a simple custom technical lineage
In the following example, the
treesection defines the IOT_JSON and IOT_DEVICES_PER_COUNTRY tables and columns. The tables are in a schema named COLLIBRA. The COLLIBRA schema is in a database named COLLIBRA and a system named Databricks.Important If you define the System asset in your lineage.json file, the
useCollibraSystemNameproperty in your lineage harvester configuration file must be set totrue; otherwise, relations will not be created between the relevant assets in Collibra and stitching will fail.To show the transformation code at the bottom of the technical lineage graph, specify the
mappingandsource_codeproperties in thelineagessection.{ "version": "1.0", "tree": [ { "name": "Databricks", "type": "system", "children": [ { "name": "COLLIBRA", "type": "database", "children": [ { "name": "COLLIBRA", "type": "schema", "children": [ { "name": "IOT_JSON", "type": "table", "leaves": [ { "name": "CCA3", "type": "column" }, { "name": "DEVICE_ID", "type": "column" } ] }, { "name": "IOT_DEVICES_PER_COUNTRY", "type": "table", "leaves": [ { "name": "COUNTRY", "type": "column" }, { "name": "NUMBER_DEVICES", "type": "column" } ] } ] } ] } ] } ], "lineages": [ { "src_path": [ { "system": "Databricks" }, { "database": "COLLIBRA" }, { "schema": "COLLIBRA" }, { "table": "IOT_JSON" }, { "column": "CCA3" } ], "trg_path": [ { "system": "Databricks" }, { "database": "COLLIBRA" }, { "schema": "COLLIBRA" }, { "table": "IOT_DEVICES_PER_COUNTRY" }, { "column": "COUNTRY" } ], "mapping": "dev_no_bat_per_country_view", "source_code": "INSERT INTO ... SELECT CCA3 AS COUNTRY...FROM IOT_JSON" } ] }Example JSON file for an advanced custom technical lineage
In the following example, the
treesection defines the IOT_JSON and IOT_DEVICES_PER_COUNTRY tables and columns. The tables are in a schema named COLLIBRA. The COLLIBRA schema is in a database named COLLIBRA and a system named Databricks.If you define the System asset in your lineage.json file, theuseCollibraSystemNameproperty in your lineage harvester configuration file must be set totrue; otherwise, relations will not be created between the relevant assets in Collibra and stitching will fail.{ "version": "1.0", "tree": [ { "name": "Databricks", "type": "system", "children": [ { "name": "COLLIBRA", "type": "database", "children": [ { "name": "COLLIBRA", "type": "schema", "children": [ { "name": "IOT_JSON", "type": "table", "leaves": [ { "name": "CCA3", "type": "column" }, { "name": "DEVICE_ID", "type": "column" } ] }, { "name": "IOT_DEVICES_PER_COUNTRY", "type": "table", "leaves": [ { "name": "COUNTRY", "type": "column" }, { "name": "NUMBER_DEVICES", "type": "column" } ] } ] } ] } ] } ], "lineages": [ { "src_path": [ { "system": "Databricks" }, { "database": "COLLIBRA" }, { "schema": "COLLIBRA" }, { "table": "IOT_JSON" }, { "column": "CCA3" } ], "trg_path": [ { "system": "Databricks" }, { "database": "COLLIBRA" }, { "schema": "COLLIBRA" }, { "table": "IOT_DEVICES_PER_COUNTRY" }, { "column": "COUNTRY" } ], "mapping_ref": { "source_code": "transforms.sql", "mapping": "dev_no_bat_per_country_view", "codebase_pos": [ { "pos_start": 71, "pos_len": 69 } ] } } ], "codebase_files": { "transforms.sql": { "mapping_refs": { "dev_no_bat_per_country_view": { "pos_start": 0, "pos_len": 246 } } } } }Example technical lineage graphs
Both example lineage.json files generate the following technical lineage graph, which contains 2 nodes and 1 edge.
The following technical lineage graph is generated by using the example lineage.json file for an advanced custom technical lineage. The bottom part shows the transformation code that generated the data flow.
In the
lineagessection, thepos_startproperty is specified with 71 and thepos_lenproperty is specified with 69. The specifications indicate that the transformation code that starts at position 71 and the following 69 characters are highlighted in blue. Line 2 in the technical lineage graph contains the highlighted transformation code.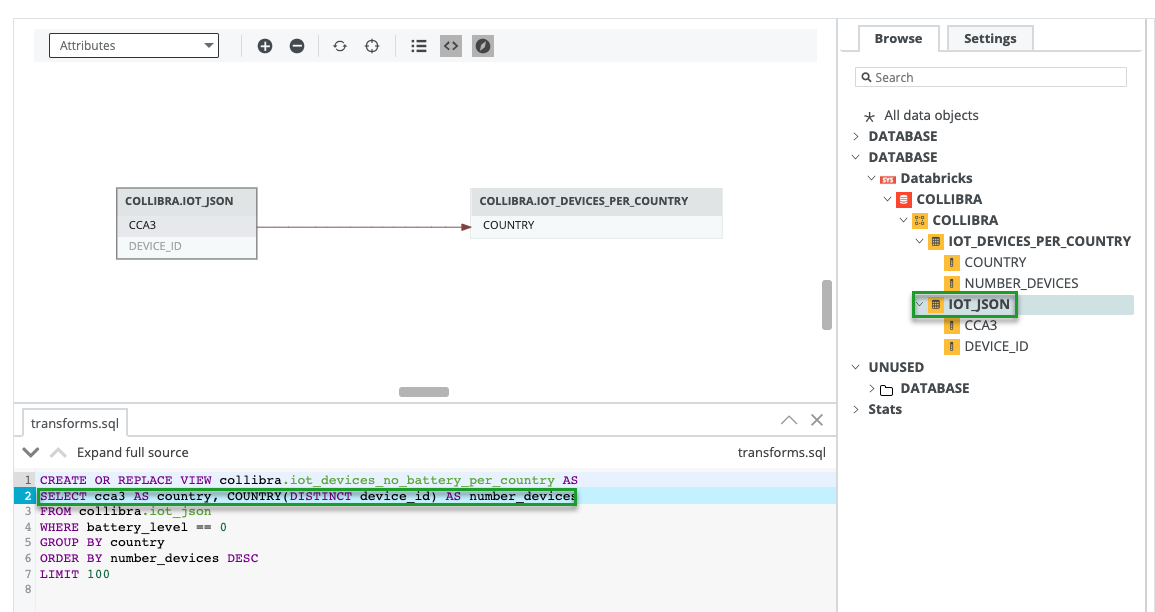
- Batch definition
You can define the custom technical lineage in any number of JSON files. Use the following format and code examples to create the JSON files, and then store the files in the folder that you created when you created the Shared Storage connection, earlier in this procedure.
JSON file formatting for the batch-definition optionIf you opt for the batch definition option, you need to create a folder with all of your JSON files and specify the folder in your lineage harvester configuration file. The harvester then accesses the folder, zips the content and ingests it for processing.
Which files do you need in your batch folder?
Let's say that you create a folder and name it custom-lineage. In this folder, you need the following:
- Exactly one metadata file, to provide the JSON architecture version, the data source type, and asset type UUIDs of the assets you want to include in the technical lineage.
- Optionally, one or more asset files, to provide a list of data objects you want to include in the technical lineage and define the data object hierarchy to achieve stitching.
- One or more lineage files, to define the lineage relation between two or more data objects.
- Optionally, a subfolder of source code files that contain the transformation code.
Example__CUSTOM-LINEAGE__ ├── assets-domain1.json ├── assets1.json ├── lineage.json ├── lineage-extra.json ├── metadata.json └── source_codes ├── sc1.sql └── sc2.pyMetadata file
Your metadata file has to be named metadata.json. Format the file as shown in the following image:
Example{ "version": 3, "application_name": "databricks", "asset_types":{ "Column":{"uuid": "00000000-0000-0000-0000-000000031008"}, "Table":{"uuid": "00000000-0000-0000-0000-000000031007"}, "Database":{"uuid": "00000000-0000-0000-0000-000000031006"}, "Schema":{"uuid": "00000000-0000-0000-0001-000400000002"} } }TipView the JSON schema for the metadata file{ "$schema": "https://json-schema.org/draft/2020-12/schema", "type": "object", "properties": { "version": { "anyOf": [ { "type": "integer" }, { "type": "string", "pattern": "^\\d+$" } ] }, "application_name": { "type": "string" }, "asset_types": { "type": "object", "additionalProperties": { "type": "object", "properties": { "uuid": { "type": "string" } } } } }, "required": [ "application_name", "version" ] }Section Description version
The version of the JSON architecture. For batch-file instruction, the value must be
3.application_name
The type of data source for which you are creating a technical lineage.
This helps us to better understand your needs and make more informed decisions concerning future integrations.
asset_types
The asset types and UUIDs of the asset types you want to include in the technical lineage.
Important If you choose to include asset files in your batch definition, the values (meaning the asset types) that you specify in this property must match the values that you specify in the
typeproperties in your asset files. Likewise, the values that you specify in this property must match the asset types that you mention in your lineage files.Assets files
Optionally, you can include one or more assets files. You use asset files to provide the list of data objects you want to include in the technical lineage and define the data object hierarchy. The
propsproperty allows you to specify the full names and domain IDs of the assets.TipDon't use asset files in the following scenarios:
- Your data source consists of the traditional (System) > Database > Schema > Table > Column asset types and hierarchy. In that case, full names are automatically, correctly constructed.
- You are working with assets that are not part of that traditional asset hierarchy (in which case, you need to use the
propsproperty to achieve stitching) and you definepropsin one or more lineage files.
The names of your assets files have to follow the format assets<something-unique>.json.
Asset files can consist of
nodes,parent, andleafkinds of assets. In the following example code, we used thenodesproperty to specify the highest levels of the data object hierarchy that we want to view in the technical lineage: Database and Schema. We then used theparentandleafproperties to build out the lower levels of the data object hierarchy: Table and Column, respectively.parentassets represent what we traditionally refer to as the table-level lineage.leafassets represents what we traditionally refer to as the column-level lineage.Keep in mind that the property names
nodes,parent, andleafare designed to be non-restrictive, so you can define a hierarchy to reflect the hierarchy of any asset types (similar to the database > schema > table > column hierarchy), including your custom asset types.Tip For examples of how to configure the
propsproperty, as shown in the following code examples, see Using the props property.TipView the JSON schema for assets files{ "$schema": "https://json-schema.org/draft/2020-12/schema", "$defs": { "assetData": { "type": "object", "properties": { "name": { "type": "string" }, "type": { "type": "string" } }, "required": [ "name", "type" ] }, "props": { "type": ["object", "null"], "properties": { "fullname": { "type": "string" }, "domain_id": { "type": "string" } }, "required": [ "fullname" ] } }, "anyOf": [ { "type": "object", "properties": { "nodes": { "type": "array", "items": { "$ref": "#/$defs/assetData" } }, "props": { "$ref": "#/$defs/props" }, "parent": { "$ref": "#/$defs/assetData" }, "leaf": { "$ref": "#/$defs/assetData" } }, "required": [ "nodes", "parent", "leaf" ] }, { "type": "object", "properties": { "nodes": { "type": "array", "items": { "$ref": "#/$defs/assetData" } }, "props": { "$ref": "#/$defs/props" }, "parent": { "$ref": "#/$defs/assetData" } }, "required": [ "nodes", "parent" ] }, { "type": "object", "properties": { "nodes": { "type": "array", "items": { "$ref": "#/$defs/assetData" } }, "props": { "$ref": "#/$defs/props" } }, "required": [ "nodes" ] } ] }Property
Description nodes
A JSON element in which you specify the highest levels of the hierarchy. In the example code, the nodes specify the hierarchy of GCS File System > GCS Bucket.
Example{ "nodes": [ { "name": "GCS1", "type": "GCS File System" }, { "name": "GCS-B1", "type": "GCS Bucket" } ], "props": { "fullname": "<full name of the GCS Bucket asset>", "domain_id": "<domain of the GCS Bucket asset>" } }nameThe name of the node data object. The value is case-sensitive.
Case-sensitivity exceptionThe value of the
nameproperty is not case-sensitive for Database, Schema, Table and Column assets. For those assets, any capitalization discrepancies are rectified during processing, and the names always appear in uppercase in the technical lineage. However, assets files are not needed or recommended for these asset types.typeThe type of data object of the specified node, for example:
System,Database,Dashboard, orReport. The value is case-sensitive.Important The values (meaning the asset types) that you specify for this property must match the values that you specify in the
asset_typesproperty in your metadata file.parent
A lower-level data object in a hierarchy for which the highest levels are specified in the
nodessection. Theparentproperty represents what we traditionally refer to as the table-level lineage.When specifying parent data objects, you also have to include the nodes information, as shown in the following example code.
Example{ "nodes": [ { "name": "GCS1", "type": "GCS File System" }, { "name": "GCS-B1", "type": "GCS Bucket" } ], "parent": { "name": "DIR1", "type": "Directory" }, "props": { "fullname": "<full name of the Directory asset>", "domain_id": "<domain of the Directory asset>" } }Tip Each parent object can contain
leafdata objects. For example, you can use theparentproperty to specify a table, and use theleafproperties to specify the columns in the table.nameThe name of the parent data object. The value is case-sensitive.
Case-sensitivity exceptionThe value of the
nameproperty is not case-sensitive for Database, Schema, Table and Column assets. For those assets, any capitalization discrepancies are rectified during processing, and the names always appear in uppercase in the technical lineage. However, assets files are not needed or recommended for these asset types.typeThe asset type of the parent data object, for example:
Table,Directory,Dashboard, orReport. The value is case-sensitive.Important The values (meaning the asset types) that you specify for this property must match the values that you specify in the
asset_typesproperty in your metadata file.leaf
The lowest level data object in your hierarchy. The
leafproperty represents what we traditionally refer to as the column-level lineage.When specifying leaf data objects, you also have to include the nodes and parent information, as shown in the following example code.
The names of parents and leaf data objects can be identical if the data objects with the same names are sub-objects of different
nodesdata objects.Example{ "nodes": [ { "name": "GCS1", "type": "GCS File System" }, { "name": "GCS-B1", "type": "GCS Bucket" } ], "parent": { "name": "DIR1", "type": "Directory" }, "leaf": { "name": "data.xls", "type": "File" }, "props": { "fullname": "<full name of the File asset>", "domain_id": "<domain of the File asset>" } }nameThe name of the leaf data object. The value is case-sensitive.
Case-sensitivity exceptionThe value of the
nameproperty is not case-sensitive for Database, Schema, Table and Column assets. For those assets, any capitalization discrepancies are rectified during processing, and the names always appear in uppercase in the technical lineage. However, assets files are not needed or recommended for these asset types.typeThe asset type of the leaf data object, for example:
Column,Dashboard, orReport. The value is case-sensitive.Important The values (meaning the asset types) that you specify for this property must match the values that you specify in the
asset_typesproperty in your metadata file.props This property allows you to specify the full name and domain ID of an asset for the purpose of stitching, regardless of asset type hierarchy.
When you add the props property to define the full name of an asset, it applies to the last asset in the array.
Tip For examples of how to configure the
propsproperty and how to use it for a custom hierarchy, see Using the props property.Important considerations
- You don't need to use this property for the traditional (System) > Database > Schema > Table > Column asset types and hierarchy. In fact, assets files are not needed or recommended for those asset types, as the full name is automatically, correctly constructed for that hierarchy. Instead, use this property to specify the full names of assets that are not part of that traditional asset hierarchy.
- You must specify in your metadata file the asset types and UUIDs of all the assets types used.
- If the
useCollibraSystemNameproperty in your lineage harvester configuration file is set totrue, the system data object is used to stitch to the System asset in Data Catalog. If theuseCollibraSystemNameproperty is set tofalsein your lineage harvester configuration file, do not specify the system data object in this section, or else stitching will fail.
A word about file processing order and inadvertently specifying the same asset more than once
Assets files and lineage files are processed in the following order: first, all assets files in alphabetical order, followed by all lineage files in alphabetical order. If you choose to specify
propsfor an asset, we recommend that you do so in either an assets file or a lineage file; not both. For any asset that is inadvertently defined more than once, the first occurrence, with respect to the processing order, is the occurrence that is used.In other words:
-
If you inadvertently define a single asset, with
props, in both an assets file and a lineage file, thepropsvalues in the assets file are used. -
If you inadvertently define a single asset, with
props, more than once in a single assets file, or in multiple assets files, the first occurrence of the asset, with respect to the processing order, is used along with thepropsvalues defined for that occurrence of the asset.
fullnameThe full name of the asset in Collibra. Names are case-sensitive.
domainIdThe reference ID of the domain in which the asset exists in Collibra.
Using the props property
The following examples offer some guidance as to when to use the
propsproperty and how to configure it.Show me a typical scenario using the props property for a custom hierarchyFirst off, let's examine why you don't need to use the
propsproperty for the traditional database > schema > table > column hierarchy. Let's say you have an assets file in which you define a leaf kind of asset:{ "nodes": [{ "name": "Snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "T1", "type": "Table" }, "leaf": { "name": "COL1", "type": "Column" } }In this case, the full name of the leaf asset (in this case a Column asset) is automatically and correctly constructed as: "snowflake>DB1>PUBLIC>T1>COL1". In fact, for the traditional database type of hierarchy, you don't even need to use asset files, much less the
propsproperty.However, for the following custom hierarchy, you can use the
propsproperty to specify the correct full name of the leaf asset, in this case a File asset.{ "nodes": [{ "name": "gcs", "type": "GCS File System" }, { "name": "bucket1", "type": "GCS Bucket" }, { "name": "/", "type": "Directory" }], "parent": { "name": "examples", "type": "Directory" }, "leaf": { "name": "data.xls", "type": "File" }, "props": { "fullname": "gcs > bucket1/examples/data.xls", "domain_id": "<domain in which the file asset resides>" }If you don't provide the full name of the leaf asset, it will be constructed using the default traditional formatting (system) > database > schema > table > column. The result would be the full name: "gcs > bucket1 > / > examples > data.xls". However, this is not the correct construction for File assets. The full name provided in the example above ensures the correct construction, so that stitching is achieved.
Show me example configurations for the props property-
A
propsproperty in anodessection describes the last asset in the array. In this example, you are specifying the full name and domain ID of the Schema asset "SCH1", not the Database asset "DB1".{ "nodes": [{"name":"DB1", "type": "Database"}, {"name": "SCH1", "type": "Schema"}], "props": { "fullname": "<full name of the Schema asset>", "domain_id": "<domain of the Schema asset>" } } - If you also want to specify the full name and domain ID of the Database asset, you need two entries, as follows:
{ "nodes": [{"name":"DB1", "type": "Database"}], "props": { "fullname": "<full name of the Database asset>", "domain_id": "<domain of the Database asset>" } }} "nodes": [{"name":"DB1", "type": "Database"}, {"name": "SCH1", "type": "Schema"}], "props": { "fullname": "<full name of the Schema asset>", "domain_id": "<domain of the Schema asset>" } } - To specify the full name and domain ID of a
parentasset, use thepropsproperty as follows:{ "nodes": [{"name":"DB1", "type": "Database"}, {"name": "SCH1", "type": "Schema"}], "parent": {"name": "TB1", "type": "Table"}, "props": { "fullname": "<full name of the Table asset>", "domain_id": "<domain of the Table asset>" } } - To specify the full name and domain ID of a
leafasset, use thepropsproperty as follows:{ "nodes": [{"name":"DB1", "type": "Database"}, {"name": "SCH1", "type": "Schema"}], "parent": {"name": "TB1", "type": "Table"}, "leaf": {"name": "COL1", "type": "Column"}, "props": { "fullname": "<full name of the Column asset>", "domain_id": "<domain of the Column asset>" } }
Show me how to find the full name and domain ID of an assetThere are two ways to find this information.
Via API
You can use the Find assets API, as documented in the Collibra Developer Portal. In the body of the response, look for the following details in the results array:
name: This is the full name of the asset.domain > id: This is the unique reference ID of the domain in which the asset is located.
Via Data Catalog
- To find the full name, open the relevant asset page, and then click Actions > Edit. The Edit dialog box appears. The full name is shown in the Name field.
- To find the domain ID, open the relevant domain in Collibra. In the following example URL, the reference ID is in bold:
https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001.
Lineage files
You can have one or more lineage files in the folder. The names of your lineage files have to follow the format lineage<something-unique>.json.
You use the lineage file to define the lineage relation between two or more data objects. The lineage relations are shown as edges in the technical lineage graph. The edges represent the data flow from a source to a target.
This section contains the path from a source to a target and defines the transformation code or transformation references to be processed by the Collibra Data Lineage service.
Note If theuseCollibraSystemNameproperty in your lineage harvester configuration file is set totrue, the system data object is used to stitch to the System asset in Data Catalog. If theuseCollibraSystemNameproperty is set tofalsein your lineage harvester configuration file, do not specify the system data object in these files, or else stitching will fail.TipView the JSON schema for lineage files{ "$schema": "https://json-schema.org/draft/2020-12/schema", "$defs": { "assetData": { "type": "object", "properties": { "name": { "type": "string" }, "type": { "type": "string" } }, "required": [ "name", "type" ] }, "props": { "type": ["object", "null"], "properties": { "fullname": { "type": "string" }, "domain_id": { "type": "string" } }, "required": [ "fullname" ] } }, "type": "object", "properties": { "src": { "anyOf": [ { "type": "object", "properties": { "nodes": { "type": "array", "items": { "$ref": "#/$defs/assetData" } }, "parent": { "$ref": "#/$defs/assetData" }, "leaf": { "$ref": "#/$defs/assetData" }, "props": { "$ref": "#/$defs/props" } }, "required": [ "nodes", "parent", "leaf" ] }, { "type": "object", "properties": { "nodes": { "type": "array", "items": { "$ref": "#/$defs/assetData" } }, "parent": { "$ref": "#/$defs/assetData" }, "props": { "$ref": "#/$defs/props" } }, "required": [ "nodes", "parent" ] } ] }, "trg": { "anyOf": [ { "type": "object", "properties": { "nodes": { "type": "array", "items": { "$ref": "#/$defs/assetData" } }, "parent": { "$ref": "#/$defs/assetData" }, "leaf": { "$ref": "#/$defs/assetData" }, "props": { "$ref": "#/$defs/props" } }, "required": [ "nodes", "parent", "leaf" ] }, { "type": "object", "properties": { "nodes": { "type": "array", "items": { "$ref": "#/$defs/assetData" } }, "parent": { "$ref": "#/$defs/assetData" }, "props": { "$ref": "#/$defs/props" } }, "required": [ "nodes", "parent" ] } ] }, "source_code": { "type": "object", "properties": { "path": { "type": "string" }, "highlights": { "type": ["array", "null"], "items": { "type": "object", "properties": { "start": { "type": "integer" }, "len": { "type": "integer" } }, "required": [ "len", "start" ] } } }, "required": [ "path" ] } }, "required": [ "src", "trg" ] }Example[ { "src": { "nodes": [{"name":"DB1", "type": "Database"}, {"name": "SCH1", "type": "Schema"}], "parent": {"name": "TB1", "type": "Table"}, "leaf": {"name": "COL1", "type": "Column"}, "props": { "fullname": "<full name of the leaf asset>", "domain_id": "<domain of the leaf asset>" }, }, "trg": { "nodes": [{"name":"DB1", "type": "Database"}, {"name": "SCH1", "type": "Schema"}], "parent": {"name": "TB2", "type": "Table"}, "props": { "fullname": "<full name of the parent asset>", "domain_id": "<domain of the parent asset>" }, "source_code" : { "path": "<folder name>/sc1.sql", "highlights": [{"start": 71, "len": 69 }, ...], "transformation_display_name": "middle bubble" } } } ]Properties
Description srcThe hierarchical path to the source data object. This property represents where the data comes from for a transformation.
Important The source of a lineage can only be a parent or a leaf.
Example{ "src": { "nodes": [{"name":"DB1", "type": "Database"}, {"name": "SCH1", "type": "Schema"}], "parent": {"name": "TB1", "type": "Table"}, "leaf": {"name": "COL1", "type": "Column"} }trgThe hierarchical path to the target data object. This property represents where the data flows to.
Important The target can be a parent or a leaf; however, if the source is a parent, the target must be a parent.
Tip If the target asset is a parent asset and the source asset is a leaf asset, we refer to the lineage as "indirect lineage". If the target asset is a parent asset and the source asset is a parent asset, we refer to the lineage as "table-level lineage".
Example{ "trg": { "nodes": [{"name":"DB1", "type": "Database"}, {"name": "SCH1", "type": "Schema"}], "parent": {"name": "TB2", "type": "Table"} }propsAn optional property that allows you to specify the full name and domain of an asset, for the purpose of stitching.
This property is not required for Database, Schema, Table and Column asset types.
A word about file processing order and inadvertently specifying the same asset more than once
Assets files and lineage files are processed in the following order: first, all assets files in alphabetical order, followed by all lineage files in alphabetical order. If you choose to specify
propsfor an asset, we recommend that you do so in either an assets file or a lineage file; not both. For any asset that is inadvertently defined more than once, the first occurrence, with respect to the processing order, is the occurrence that is used.In other words:
-
If you inadvertently define a single asset, with
props, in both an assets file and a lineage file, thepropsvalues in the assets file are used. -
If you inadvertently define a single asset, with
props, more than once in a single assets file, or in multiple assets files, the first occurrence of the asset, with respect to the processing order, is used along with thepropsvalues defined for that occurrence of the asset.
source_codeThe transformation code that determines how the technical lineage is constructed. This can be a descriptive string or a SQL statement that manipulates data.
This section is optional.
pathThe path and name of the source code file that contains the transformation code. The path relative to the source_codes folder, which is in the same folder as the lineage JSON files.
highlightsThis optional property identifies a string of transformation code in a source code file to be highlighted in the source code pane at the bottom part of the technical lineage graph. The entire lines that include the transformation code are highlighted.
The string must be a subset of the string of transformation code that is defined by the
startandlenproperties.startThe start position of the string of the transformation code to be highlighted. The start position is in characters, not bytes.
lenThe length of the string of the transformation code to be highlighted. The length is in characters, not bytes.
transformation_display_nameThe name of the transformation when looking at the transformations view in the technical lineage viewer.
Source codes subfolder and files
You can provide a subfolder of source code files that define the transformation details. The source code folder and your JSON files must be in the CUSTOM_LINEAGE folder, along with the JSON files. If it's not, an error occurs indicating that the lineage harvester cannot find the source code files.
The source code paths are relative to the CUSTOM_LINEAGE folder.
Example- source_codes/sc1.sql
- source_codes/another-subfolder/sc2.sql
What happens if I choose not to provide source code files?
If you are using the lineage harvester and there are no source code files to analyze, the batch stats are empty, as shown below. The lineage relations are still created, but because batch stats are directly linked to the source codes, if source code files are not provided, this is expected.
Batch stats: Parsing errors: 0 Analysis errors: 0 Done: 1
The
Done: 1result is a dummy entry, so that the source appears in the Sources tab page.Example JSON files
For some example JSON files, go to Custom technical lineage JSON file examples.
Example batch-definition JSON filesIn this section, we provide three detailed examples of how to configure your metadata, assets and lineage JSON files for the batch definition option.
Example 1 is the least complex. It shows a configuration for working with data sources that conform to the traditional (System) > Database > Schema > Table > Column hierarchy. Examples 2 and 3 are more complex examples.
Helpful considerations to keep in mind
Don't use asset files in the following scenarios:
- Your data source consists of the traditional (System) > Database > Schema > Table > Column asset types and hierarchy. In that case, full names are automatically, correctly constructed.
- You are working with assets that are not part of that traditional asset hierarchy (in which case, you need to use the
propsproperty to achieve stitching) and you definepropsin one or more lineage files.
- Don't use the
propsproperty for the traditional (System) > Database > Schema > Table > Column hierarchy.Typical scenario in which you need to use the props propertyFirst off, let's examine why you don't need to use the
propsproperty for the traditional database > schema > table > column hierarchy. Let's say you have an assets file in which you define a leaf kind of asset:{ "nodes": [{ "name": "Snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "T1", "type": "Table" }, "leaf": { "name": "COL1", "type": "Column" } }In this case, the full name of the leaf asset (in this case a Column asset) is automatically and correctly constructed as: "snowflake>DB1>PUBLIC>T1>COL1".
However, for the following custom hierarchy, you can use the
propsproperty to specify the correct full name of the leaf asset, in this case a File asset.{ "nodes": [{ "name": "gcs", "type": "GCS File System" }, { "name": "bucket1", "type": "GCS Bucket" }, { "name": "/", "type": "Directory" }], "parent": { "name": "examples", "type": "Directory" }, "leaf": { "name": "data.xls", "type": "File" }, "props": { "fullname": "gcs > bucket1/examples/data.xls", "domain_id": "<domain in which the file asset resides>" }If you don't provide the full name of the leaf asset, it will be constructed using the default traditional formatting (system) > database > schema > table > column. The result would be the full name: "gcs > bucket1 > / > examples > data.xls". However, this is not the correct construction for File assets. The full name provided in the example above ensures the correct construction, so that stitching is achieved.
Examples
Example 1Scenario
In this example, we are working with a single data source with the traditional (System) > Database > Schema > Table > Column asset types and hierarchy. Therefore, we don't need to include an asset file or use the
propsproperty.Which files to include?
We are including the following files:
__CUSTOM-LINEAGE__ ├── lineage.json ├── metadata.json └── source_codes ├── source_code_view_1.txt └── source_code_view_2.txt- A metadata JSON file. Tip You always need exactly one metadata JSON file.
- One lineage JSON file, to define the lineage relationships and to show:
- Column-level lineage.
- Column-level lineage from the same source (
src), which is achieved by adding another entry with the same source. - Indirect lineage, in other words the target (
trg) is a parent asset. - Table-level lineage, in other words both the source and the target are a parent asset.
- Two source code files in a source_code directory.Tip Source code files are always optional.
The metadata JSON file
{ "version": 3, "application_name": "custom lineage batch example 1", "asset_types": { "System": { "uuid": "00000000-0000-0000-0000-000000031302" }, "Column": { "uuid": "00000000-0000-0000-0000-000000031008" }, "Table": { "uuid": "00000000-0000-0000-0000-000000031007" }, "Database": { "uuid": "00000000-0000-0000-0000-000000031006" }, "Schema": { "uuid": "00000000-0000-0000-0001-000400000002" } } }The lineage JSON file
[{ "src": { "nodes": [{ "name": "snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "T1", "type": "Table" }, "leaf": { "name": "col1", "type": "Column" } }, "trg": { "nodes": [{ "name": "snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "VIEW_1", "type": "Table" }, "leaf": { "name": "col1", "type": "Column" } } }, { "src": { "nodes": [{ "name": "snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "T1", "type": "Table" }, "leaf": { "name": "col1", "type": "Column" } }, "trg": { "nodes": [{ "name": "snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "VIEW_1", "type": "Table" }, "leaf": { "name": "col2", "type": "Column" } }, "source_code": { "path": "source_codes/source_code_view_1.txt", "highlights": [{ "start": 0, "len": 43 }], "transformation_display_name": "view_1 creation" } }, { "src": { "nodes": [{ "name": "snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "T1", "type": "Table" }, "leaf": { "name": "col2", "type": "Column" } }, "trg": { "nodes": [{ "name": "snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "VIEW_1", "type": "Table" } } }, { "src": { "nodes": [{ "name": "snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "T2", "type": "Table" } }, "trg": { "nodes": [{ "name": "snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "VIEW_2", "type": "Table" } }, "source_code": { "path": "source_codes/source_code_view_2.txt", "highlights": [{ "start": 0, "len": 39 }], "transformation_display_name": "view_2 creation" } } ]Example 2Scenario
In this example, we are working with two data sources:
- A source system with the following asset types and hierarchy: GCS File System > GCS Bucket > Directory > File.
- A target system with the traditional (System) > Database > Schema > Table > Column asset types and hierarchy.
To achieve stitching, we need to use the
propsproperty to define the correct full-name construction for the File asset in the source system. We can definepropsin a lineage file. By doing so, we don't need to include any asset files.Which files to include?
We are including the following files:
__CUSTOM-LINEAGE__ ├── lineage.json ├── metadata.json- A metadata JSON file. Tip You always need exactly one metadata JSON file.
- One lineage JSON file, with the
propsproperty, to define the correct full-name construction for the File asset in the source system and achieve stitching.Tip By defining thepropsin the lineage file, we don't need to include an assets file. If, for example, we had several lineage files, it would be easier to include an assets file and define thepropsthere once, rather than define thepropsin each lineage file.
We are not including source code files. They are always optional.
The metadata JSON file
{ "version": 3, "application_name": "custom lineage batch example 2", "asset_types": { "System": { "uuid": "00000000-0000-0000-0000-000000031302" }, "Column": { "uuid": "00000000-0000-0000-0000-000000031008" }, "Table": { "uuid": "00000000-0000-0000-0000-000000031007" }, "Database": { "uuid": "00000000-0000-0000-0000-000000031006" }, "Schema": { "uuid": "00000000-0000-0000-0001-000400000002" }, "File": { "uuid": "00000000-0000-0000-0000-000000031304" }, "Directory": { "uuid": "00000000-0000-0000-0000-000000031303" }, "GCS Bucket": { "uuid": "00000000-0000-0000-0001-002700000002" }, "GCS File System": { "uuid": "00000000-0000-0000-0001-002700000001" } } }The lineage JSON file
[{ "src": { "nodes": [{ "name": "gcs", "type": "GCS File System" }, { "name": "catingestiontest", "type": "GCS Bucket" }, { "name": "/", "type": "Directory" }, { "name": "ingestion-test", "type": "Directory" }], "parent": { "name": "ingestion copy", "type": "Directory" }, "leaf": { "name": "mytest.csv", "type": "File" }, "props": { "fullname": "f13bf705-13a4-44c9-843e-f341feccfb6e > catingestiontest/ingestion-test/ingestion copy/mytest.csv/1611609340099809", "domain_id": "fea1b0b0-705f-4e0d-b5eb-1f21132cc718" } }, "trg": { "nodes": [{ "name": "snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "T1", "type": "Table" }, "leaf": { "name": "col1", "type": "Column" } } }]Example 3Scenario
In this example, we are working with the same two data sources as in Example 2:
- A source system with the following asset types and hierarchy: GCS File System > GCS Bucket > Directory > File.
- A target system with the traditional (System) > Database > Schema > Table > Column asset types and hierarchy.
To achieve stitching, we need to use the
propsproperty to define the correct full-name construction for the File asset in the source system. However, this time we have multiple lineage files. Instead of definingpropsin each lineage file, let's include an asset file. That way we only have to definepropsthere once.Which files to include?
We are including the following files:
__CUSTOM-LINEAGE__ ├── assets.json ├── lineage-1.json ├── lineage-2.json ├── metadata.json- A metadata JSON file. Tip You always need exactly one metadata JSON file.
- An assets JSON file, in which provide the list of data objects we want to include in the technical lineage, and define
props. - Two lineage JSON files, to define the lineage relationships.
We are not including source code files. They are always optional.
Metadata JSON file
{ "version": 3, "application_name": "custom lineage batch example 2", "asset_types": { "System": { "uuid": "00000000-0000-0000-0000-000000031302" }, "Column": { "uuid": "00000000-0000-0000-0000-000000031008" }, "Table": { "uuid": "00000000-0000-0000-0000-000000031007" }, "Database": { "uuid": "00000000-0000-0000-0000-000000031006" }, "Schema": { "uuid": "00000000-0000-0000-0001-000400000002" }, "File": { "uuid": "00000000-0000-0000-0000-000000031304" }, "Directory": { "uuid": "00000000-0000-0000-0000-000000031303" }, "GCS Bucket": { "uuid": "00000000-0000-0000-0001-002700000002" }, "GCS File System": { "uuid": "00000000-0000-0000-0001-002700000001" } } }Assets JSON file
[{ "nodes": [{ "name": "gcs", "type": "GCS File System" }, { "name": "catingestiontest", "type": "GCS Bucket" }, { "name": "/", "type": "Directory" }, { "name": "ingestion-test", "type": "Directory" }], "parent": { "name": "ingestion copy", "type": "Directory" }, "leaf": { "name": "mytest.csv", "type": "File" }, "props": { "fullname": "f13bf705-13a4-44c9-843e-f341feccfb6e > catingestiontest/ingestion-test/ingestion copy/mytest.csv/1611609340099809", "domain_id": "fea1b0b0-705f-4e0d-b5eb-1f21132cc718" } }, { "nodes": [{ "name": "snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "T1", "type": "Table" }, "leaf": { "name": "col3", "type": "Column" } }]Lineage JSON file (1 of 2)
[{ "src": { "nodes": [{ "name": "gcs", "type": "GCS File System" }, { "name": "catingestiontest", "type": "GCS Bucket" }, { "name": "/", "type": "Directory" }, { "name": "ingestion-test", "type": "Directory" }], "parent": { "name": "ingestion copy", "type": "Directory" }, "leaf": { "name": "mytest.csv", "type": "File" } }, "trg": { "nodes": [{ "name": "snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "T1", "type": "Table" }, "leaf": { "name": "col1", "type": "Column" } } }]Lineage JSON file (2 of 2)
[{ "src": { "nodes": [{ "name": "gcs", "type": "GCS File System" }, { "name": "catingestiontest", "type": "GCS Bucket" }, { "name": "/", "type": "Directory" }, { "name": "ingestion-test", "type": "Directory" }], "parent": { "name": "ingestion copy", "type": "Directory" }, "leaf": { "name": "mytest.csv", "type": "File" } }, "trg": { "nodes": [{ "name": "snowflake", "type": "System" }, { "name": "DB1", "type": "Database" }, { "name": "PUBLIC", "type": "Schema" }], "parent": { "name": "T1", "type": "Table" }, "leaf": { "name": "col2", "type": "Column" } } }]
-
Add a technical lineage capability to your Edge site.
Complete the following steps to add the technical lineage capability to your Edge site.
Prerequisites
- You have a global role that has the System administration global permission.
- You have a global role that has the Manage connections and capabilities global permission, for example, Edge integration engineer.
Steps
- Open an Edge site.
-
On the main toolbar, click
, and then click
Settings.
The Collibra settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of the Edge sites. - In the table, click the name of the Edge site whose status is Healthy.
The Edge site page opens.
-
On the main toolbar, click
- In the Capabilities section, click Add capability.
The Add capability page appears. - Select the relevant capability template
Technical Lineage for ADFTechnical Lineage for Databricks Unity CatalogTechnical Lineage for DataStageTechnical Lineage for Informatica Intelligent Cloud Services (IICS)Technical Lineage for Informatica PowerCenterTechnical Lineage for MatillionTechnical Lineage for SQL Server Integration Services (SSIS)Technical Lineage for dbtTechnical Lineage for dbt CloudGoogle Dataplex - Enter the required information.
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Amazon Redshift Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Important This field is mandatory, but the value you specify is not taken into consideration. We will remove this field in a future Collibra version.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key>  Yes for US government customers.
Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee

For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Important This field is mandatory, but the value you specify is not taken into consideration. We will remove this field in a future Collibra version.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
 No
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
Source ID
The name of the data source. Specify a name that is unique.
Yes
Authentication Type
The authentication details for signing in to Azure Data Factory. You can select one of the following values:
Service Principal- When you select this authentication type, ensure that you entered the application secret for the Service Principal in the Service Principal Secret field when you created the Azure connection.
Resource Owner Password Credentials- When you select this authentication type, ensure that you specify the username field in this capability and also entered the password in the Service Principal Secret field when you created the Azure connection.
Yes
ADF ConnectionThe Azure connection that you created.
Yes
Username
The email address of your Azure Active Directory user.
This field applies only when you selected
Resource Owner Password Credentialsfor the field. No
Resource Group Name The name of the resource group that the data factory belongs to.
Yes
Subscription ID The subscription ID of the resource group.
Yes
Factories The Azure Data Factory factories that Collibra Data Lineage collects and processes. Specify this property with an array of Azure Data Factory factory names. This property is optional.
The following rules apply when you specify this property:
- Enter the factory names in square brackets ([ ]), enclose each factory name in double quotes (" "), and separate them by a comma, for example, ["MyFirstFactory", "MySecondFactory"].
- The factory name is not case-sensitive. For example, the MyFactory and myfactory factories are considered the same by Azure Data Factory and Collibra Data Lineage.
- If you do not specify any factory name, Collibra Data Lineage collects and processes all factories that have datasets and piplelines in them.
No
Source Configuration
The source configuration for database mapping, system mapping, schema mapping, and filtering. Specify the following properties in JSON format and enter the content in this field.
If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the <sourceId>.conf file in this field.Connection definition propertiesProperty
Description Mandatory?
found_dbname=<database name>;found_hostname=<server name>;found_schema=<schema name> | found_dbname=<datafactory_name>_<linkedservice_name>;found_hostname=*
The information of the supported data sources in Azure Data Factory to be collected by Collibra Data Lineage. You can specify any of the following values for the
found_dbnameproperty:- A database name. And then you can specify the following properties:
found_hostname=<server name>, where<server name>is the name of the server that the database is running on.found_schema=<schema name>, where<schema name>is the name of the schema. This property is optional.
- The combination of
<datafactory_name>_<linkedservice_name>, where<datafactory_name>is a data factory name and<linkedservice_name>is a linked service name. If you use this combination, specify*for thefound_hostnameproperty.
TipYou can use wildcards to capture multiple connection string combinations:
Show me the supported wildcardsPattern Description * Matches everything. ? Matches any single character. [seq] Matches any character in "seq". [!seq] Matches any character not in "seq". Yes
dbnameThe name of the database asset in Data Catalog.
No
schemaThe name of the schema asset in Data Catalog. Specify this property with the schema name that you created when you registered the data source.
If the Collibra Data Lineage fails to find the schema that you specify, it uses the default schema.
No
dialectIf you specify a database name for the
found_dbnameproperty, select one of the following dialects. If you specify a linked service name for thefound_dbnameproperty, ignore this property.Click here for a list of dialects of supported data sources in Azure Data Factory.- azure, for an Azure SQL Server data source.
- bigquery, for a Google BigQuery data source.
- db2, for a IBM Db2 data source.
- generic, for any data source.
- greenplum, for a Greenplum data source.
- hana, for a SAP HANA data source.
- hive, for a Hive data source.
- impala, for a Impala data source.
- mssql, for a Microsoft SQL Server data source.
- mysql, for a MySQL data source.
- netezza, for a Netezza data source.
- oracle, for an Oracle data source.
- postgres, for an PostgreSQL data source.
- redshift, for an Amazon Redshift data source.
- snowflake, for a Snowflake data source.
- spark, for a Spark SQL data source.
- sybase, for a Sybase data source.
- teradata, for a Teradata data source.
- vertica, for a Vertica data source.
No
collibraSystemNameThe system or server name of the data source.
Specify this property when you set the value of the Collibra system name setting to
True to override the default Collibra System asset name for this data source. Specify this property with the same name as the name of the System asset that you created when you registered the data source.
If you don't specify a value for this property,
DEFAULTis shown in the technical lineage.How do I configure this property if I have two databases with the same name?"found_dbname=databasename1;found_hostname=*;found_schema=schema1": { "dbname": "Customers", "schema": "mssql-schema-name", "dialect": "mssql", "collibraSystemName": "Customers-Europe" }, "found_dbname=databasename2;found_hostname=server-name.onmicrosoft.com;found_schema=schema2": { "dbname": "Customers", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "Customers-USA" },Warning The value of this property must exactly match (including for case-sensitivity) the name of your System asset in Collibra.
No
ExampleShow me an example <source ID> configuration file{ "found_dbname=databasename1;found_hostname=server-name.onmicrosoft.com;found_schema=schema1": { "dbname": "mssql-database-name", "schema": "mssql-schema-name", "dialect": "mssql", "collibraSystemName": "mssql-system-name" }, "found_dbname=datafactory_linkedservice;found_hostname=*": { "dbname": "linkedservice-dbname", "schema": "linkedservice-schema", "collibraSystemName": "linkedservice-system-name" } } No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
NameThe name of the Edge capability.
Yes
DescriptionThe description of the Edge capability.
Yes
Capability templateThe capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for ADF Yes
Main Properties This section contains the information for creating a technical lineage.
Source IDThe name of the data source. Specify a name that is unique.
Yes
Authentication TypeThe authentication details for signing in to Azure Data Factory. You can select one of the following values:
Service Principal- When you select this authentication type, ensure that you entered the application secret for the Service Principal in the Service Principal Secret field when you created the Azure connection.
Resource Owner Password Credentials- When you select this authentication type, ensure that you specify the username field in this capability and also entered the password in the Service Principal Secret field when you created the Azure connection.
Yes
ADF ConnectionThe Azure connection that you created.
Yes
UsernameThe email address of your Azure Active Directory user.
This field applies only when you selected
Resource Owner Password Credentialsfor the field. No
Resource Group NameThe name of the resource group that the data factory belongs to.
Yes
Subscription IDThe subscription ID of the resource group.
Yes
FactoriesThe Azure Data Factory factories that Collibra Data Lineage collects and processes. Specify this property with an array of Azure Data Factory factory names. This property is optional.
The following rules apply when you specify this property:
- Enter the factory names in square brackets ([ ]), enclose each factory name in double quotes (" "), and separate them by a comma, for example, ["MyFirstFactory", "MySecondFactory"].
- The factory name is not case-sensitive. For example, the MyFactory and myfactory factories are considered the same by Azure Data Factory and Collibra Data Lineage.
- If you do not specify any factory name, Collibra Data Lineage collects and processes all factories that have datasets and piplelines in them.
No
Source ConfigurationThe source configuration for database mapping, system mapping, schema mapping, and filtering. Specify the following properties in JSON format and enter the content in this field.
If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the connection_definitions.conf file in this field.Connection definition propertiesProperty
Description Mandatory?
found_dbname=<database name>;found_hostname=<server name>;found_schema=<schema name> | found_dbname=<datafactory_name>_<linkedservice_name>;found_hostname=*
The information of the supported data sources in Azure Data Factory to be collected by Collibra Data Lineage. You can specify any of the following values for the
found_dbnameproperty:- A database name. And then you can specify the following properties:
found_hostname=<server name>, where<server name>is the name of the server that the database is running on.found_schema=<schema name>, where<schema name>is the name of the schema. This property is optional.
- The combination of
<datafactory_name>_<linkedservice_name>, where<datafactory_name>is a data factory name and<linkedservice_name>is a linked service name. If you use this combination, specify*for thefound_hostnameproperty.
TipYou can use wildcards to capture multiple connection string combinations:
Show me the supported wildcardsPattern Description * Matches everything. ? Matches any single character. [seq] Matches any character in "seq". [!seq] Matches any character not in "seq". Yes
dbnameThe name of the database asset in Data Catalog.
No
schemaThe name of the schema asset in Data Catalog. Specify this property with the schema name that you created when you registered the data source.
If the Collibra Data Lineage fails to find the schema that you specify, it uses the default schema.
No
dialectIf you specify a database name for the
found_dbnameproperty, select one of the following dialects. If you specify a linked service name for thefound_dbnameproperty, ignore this property.Click here for a list of dialects of supported data sources in Azure Data Factory.- azure, for an Azure SQL Server data source.
- bigquery, for a Google BigQuery data source.
- db2, for a IBM Db2 data source.
- generic, for any data source.
- greenplum, for a Greenplum data source.
- hana, for a SAP HANA data source.
- hive, for a Hive data source.
- impala, for a Impala data source.
- mssql, for a Microsoft SQL Server data source.
- mysql, for a MySQL data source.
- netezza, for a Netezza data source.
- oracle, for an Oracle data source.
- postgres, for an PostgreSQL data source.
- redshift, for an Amazon Redshift data source.
- snowflake, for a Snowflake data source.
- spark, for a Spark SQL data source.
- sybase, for a Sybase data source.
- teradata, for a Teradata data source.
- vertica, for a Vertica data source.
No
collibraSystemNameThe system or server name of the data source.
Specify this property when you set the value of the Collibra system name setting to
True to override the default Collibra System asset name for this data source. Specify this property with the same name as the name of the System asset that you created when you registered the data source.
If you don't specify a value for this property,
DEFAULTis shown in the technical lineage.How do I configure this property if I have two databases with the same name?"found_dbname=databasename1;found_hostname=*;found_schema=schema1": { "dbname": "Customers", "schema": "mssql-schema-name", "dialect": "mssql", "collibraSystemName": "Customers-Europe" }, "found_dbname=databasename2;found_hostname=server-name.onmicrosoft.com;found_schema=schema2": { "dbname": "Customers", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "Customers-USA" },Warning The value of this property must exactly match (including for case-sensitivity) the name of your System asset in Collibra.
No
ExampleShow me an example <source ID> configuration file{ "found_dbname=databasename1;found_hostname=server-name.onmicrosoft.com;found_schema=schema1": { "dbname": "mssql-database-name", "schema": "mssql-schema-name", "dialect": "mssql", "collibraSystemName": "mssql-system-name" }, "found_dbname=datafactory_linkedservice;found_hostname=*": { "dbname": "linkedservice-dbname", "schema": "linkedservice-schema", "collibraSystemName": "linkedservice-system-name" } } No
PropertyThis section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On SourcesThis option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After ProcessingTechnical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze OnlyThis option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
ActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging
This section contains the properties for debug logging. This setting is not valid for this integration.
Debug
This setting is not valid for this integration. It should be set to false. NoField Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
GCP Connection The GCP connection that you created.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> No
Save Input Metadata This option determines whether you want to save the input metadata that is extracted from the data source in a file. The file can be useful for troubleshooting. Select this option only on request of Collibra Support.
No
Logging configuration, Memory (MiB), and JVM arguments These fields contain configuration options that can help when investigating issues with the capability.
Important Only complete these fields on request of or together with Collibra Support. No
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Azure Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Synonyms
This query retrieves the alternative names for the database objects.
Views This query retrieves the view definitions.
Other Queries This query retrieves other data that technical lineage needs, for example stored procedures, functions, and packages. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Synonyms
This query retrieves the alternative names for the database objects.
Views This query retrieves the view definitions.
Other Queries This query retrieves other data that technical lineage needs, for example stored procedures, functions, and packages. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Azure Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Important This field is mandatory, but the value you specify is not taken into consideration. We will remove this field in a future Collibra version.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Synonyms
This query retrieves the alternative names for the database objects.
Views This query retrieves the view definitions.
Other Queries This query retrieves other data that technical lineage needs, for example stored procedures, functions, and packages. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Important This field is mandatory, but the value you specify is not taken into consideration. We will remove this field in a future Collibra version.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Synonyms
This query retrieves the alternative names for the database objects.
Views This query retrieves the view definitions.
Other Queries This query retrieves other data that technical lineage needs, for example stored procedures, functions, and packages. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Azure Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Synonyms
This query retrieves the alternative names for the database objects.
Views This query retrieves the view definitions.
Other Queries This query retrieves other data that technical lineage needs, for example stored procedures, functions, and packages. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Synonyms
This query retrieves the alternative names for the database objects.
Views This query retrieves the view definitions.
Other Queries This query retrieves other data that technical lineage needs, for example stored procedures, functions, and packages. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Custom Technical Lineage Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
Databricks Connection The Databricks connection that you created.
Yes
Compute Resource HTTP Path The HTTP path of the compute resource in Databricks Unity Catalog that Collibra Data Lineage collects and processes to create technical lineage.
How to find the HTTP path?You can find the HTTP path in the connection details of your cluster as shown in the following graphic. For details, go to Get connection details for a cluster in Databricks documentation.
 Yes
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Time Frame
Specify the duration for data collection. The default value is 365, which means that Collibra Data Lineage collects the data of the past 365 days.
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Save Input Metadata This option determines whether you want to save the input metadata that is extracted from the data source in a file. The file can be useful for troubleshooting. Select this option only on request of Collibra Support.
No
Filters Use this section to include or exclude databases and schemas to be ingested. Enter the filters in JSON format. If you used filters when you integrated Databricks Unity Catalog, you can enter in this field the content from the Filters and Domain Mapping field in the Databricks Unity Catalog capability. Noted that Collibra Data Lineage ignores the UUIDs that are specified in the content.
Text in JSON format to include or exclude databases and schemas, and to configure domain mappings.
- The text must be in JSON format and can contain an include and an exclude block. You can use any JSON validator to verify the format. Collibra is not responsible for the privacy, confidentiality, or protection of the data you submit to such JSON validators, and has no liability for such use.
- In the include block, you can specify the domain in which specific catalogs or schemas must be ingested. The format is:
“Catalog/Database > schema ”: “domain ID”. For example,"HR > address-schema": "30000000-0000-0000-0000-000000000000". - In the exclude block, you can specify the catalogs or schemas that you don't want to ingest. For example,
"* > test". - The exclude block has priority over the include block.
- If the include block is not present, we ingest all assets into the same domain as the System asset.
- If there is no explicit domain mapping for a schema, we use the domain specified for the database.
- You can use the keyword
defaultas a domain ID. In that case, the catalog or schema will be ingested in the same domain as the System asset. - A match with a database has priority over a match with a schema.
- The integration fails before the synchronization starts, if one or more domain IDs specified in the include block don't exist.
- The integration fails before the synchronization starts if a domain ID is left empty in the include block.
- You can use the ? and * wildcards in the catalog and schema names. If a catalog or schema matches multiple lines, the most detailed match is taken into account.
Show exampleExample{"include": {"HR": "20000000-0000-0000-0000-000000000000",
"HR > address-schema": "30000000-0000-0000-0000-000000000000","Orders > fk*": "40000000-0000-0000-0000-000000000000",
"Orders > *": "50000000-0000-0000-0000-000000000000",
"* > profiling": "60000000-0000-0000-0000-000000000000",
"sales": "default"},"exclude": ["testDB",
" * > information_schema"]}In this example:
- Assets from the "HR" database will be ingested into the domain with ID "20000000-0000-0000-0000-000000000000". However, all assets from the "HR > address-schema" schema will be ingested into the domain with id "30000000-0000-0000-0000-000000000000".
- All assets from the "Orders” database with schemas starting with fk (fk*) will be ingested into the domain with ID "40000000-0000-0000-0000-000000000000", and all other assets from the "Orders” database will be ingested into the domain with ID "50000000-0000-0000-0000-000000000000".
- All assets from the "sales" database will be ingested in the same domain as the System asset.
- Assets from the "profiling" schema will be ingested into the domain with ID "60000000-0000-0000-0000-000000000000". However, the "profiling" schema in the database "Orders" will be ingested in the domain with ID "50000000-0000-0000-0000-000000000000" because a database match has priority over a schema match.
- All assets from the "testDB” database will be excluded.
- All assets from the “information_schema” schema in all databases will be excluded.
No
Logging configuration, Memory (MiB), and JVM arguments These fields contain configuration options that can help when investigating issues with the capability.
Important Only complete these fields on request of or together with Collibra Support. No
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
NameThe name of the Edge capability.
Yes
DescriptionThe description of the Edge capability.
Yes
Capability templateThe capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Databricks Unity Catalog Yes
Main Properties
This section contains the information for creating a technical lineage.
Databricks ConnectionThe Databricks connection that you created.
Yes
Compute Resource HTTP PathThe HTTP path of the compute resource in Databricks Unity Catalog that Collibra Data Lineage collects and processes to create technical lineage.
How to find the HTTP path?You can find the HTTP path in the connection details of your cluster as shown in the following graphic. For details, go to Get connection details for a cluster in Databricks documentation.
Yes
Source IDThe name of the data source. Specify a name that is unique.
Yes
Time FrameSpecify the duration for data collection. The default value is 365, which means that Collibra Data Lineage collects the data of the past 365 days.
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Save Input MetadataThis option determines whether you want to save the input metadata that is extracted from the data source in a file. The file can be useful for troubleshooting. Select this option only on request of Collibra Support.
No
FiltersUse this section to include or exclude databases and schemas to be ingested. Enter the filters in JSON format. If you used filters when you integrated Databricks Unity Catalog, you can enter in this field the content from the Filters and Domain Mapping field in the Databricks Unity Catalog capability. Noted that Collibra Data Lineage ignores the UUIDs that are specified in the content.
Text in JSON format to include or exclude databases and schemas, and to configure domain mappings.
- The text must be in JSON format and can contain an include and an exclude block. You can use any JSON validator to verify the format. Collibra is not responsible for the privacy, confidentiality, or protection of the data you submit to such JSON validators, and has no liability for such use.
- In the include block, you can specify the domain in which specific catalogs or schemas must be ingested. The format is:
“Catalog/Database > schema ”: “domain ID”. For example,"HR > address-schema": "30000000-0000-0000-0000-000000000000". - In the exclude block, you can specify the catalogs or schemas that you don't want to ingest. For example,
"* > test". - The exclude block has priority over the include block.
- If the include block is not present, we ingest all assets into the same domain as the System asset.
- If there is no explicit domain mapping for a schema, we use the domain specified for the database.
- You can use the keyword
defaultas a domain ID. In that case, the catalog or schema will be ingested in the same domain as the System asset. - A match with a database has priority over a match with a schema.
- The integration fails before the synchronization starts, if one or more domain IDs specified in the include block don't exist.
- The integration fails before the synchronization starts if a domain ID is left empty in the include block.
- You can use the ? and * wildcards in the catalog and schema names. If a catalog or schema matches multiple lines, the most detailed match is taken into account.
Show exampleExample{"include": {"HR": "20000000-0000-0000-0000-000000000000",
"HR > address-schema": "30000000-0000-0000-0000-000000000000","Orders > fk*": "40000000-0000-0000-0000-000000000000",
"Orders > *": "50000000-0000-0000-0000-000000000000",
"* > profiling": "60000000-0000-0000-0000-000000000000",
"sales": "default"},"exclude": ["testDB",
" * > information_schema"]}In this example:
- Assets from the "HR" database will be ingested into the domain with ID "20000000-0000-0000-0000-000000000000". However, all assets from the "HR > address-schema" schema will be ingested into the domain with id "30000000-0000-0000-0000-000000000000".
- All assets from the "Orders” database with schemas starting with fk (fk*) will be ingested into the domain with ID "40000000-0000-0000-0000-000000000000", and all other assets from the "Orders” database will be ingested into the domain with ID "50000000-0000-0000-0000-000000000000".
- All assets from the "sales" database will be ingested in the same domain as the System asset.
- Assets from the "profiling" schema will be ingested into the domain with ID "60000000-0000-0000-0000-000000000000". However, the "profiling" schema in the database "Orders" will be ingested in the domain with ID "50000000-0000-0000-0000-000000000000" because a database match has priority over a schema match.
- All assets from the "testDB” database will be excluded.
- All assets from the “information_schema” schema in all databases will be excluded.
No
Logging configuration, Memory (MiB), and JVM argumentsThese fields contain configuration options that can help when investigating issues with the capability.
Important Only complete these fields on request of or together with Collibra Support. No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
Yes
Mask The pattern of the file names in the directory. By default, the value is
*. No
Source Configuration
The connection definitions, where you specify relevant translations for each data source. Specify the following properties in JSON format and enter the content in this field.
If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the <sourceId>.conf file in this field.Connection definition propertiesProperty
Description OdbcDataSources
Open Database Connectivity data sources in IBM InfoSphere DataStage for which you want to create a technical lineage.
<data-source-name>The ODBC data source name that you use in your DataStage projects.
This section contains the properties to translate the database, schema and dialect.
dbnameThe name of your database, to which the ODBC data source connection refers. schemaThe name of your schema, to which the ODBC data source connection refers.
dialectThe dialect of the referenced database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
collibraSystemNameThe system or server name of the data source.
Specify this property when you set the value of the Collibra system name setting to
True to override the default Collibra System asset name for this data source. Specify this property with the same name as the name of the System asset that you created when you registered the data source.
This property is optional.
NonOdbcConnectors
Other data source connectors in IBM InfoSphere DataStage for which you want to create a technical lineage. For example, DB2, Oracle or Netezza.
Note This section is optional.
<data-source-connector-ID>The data source username and database of the connector that you use in your DataStage projects. This usually looks like for example admin@database-name. The combination of the username and database name should be unique.
The following section contains the properties to translate the database, schema and dialect.
dbnameThe name of your database, to which the data source connection refers. schemaThe name of your schema, to which the data source connection refers.
dialectThe dialect of the referenced database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
collibraSystemNameThe system or server name of the data source.
Specify this property when you set the value of the Collibra system name setting to
True to override the default Collibra System asset name for this data source. Specify this property with the same name as the name of the System asset that you created when you registered the data source.
This property is optional.
Jobs
This section is optional. The following rules apply when you specify this section:
- Specify jobs that are executed so that the technical lineage graph does not include any job parameters with undefined values.
- Specify only the first and parent jobs in a sequence of executed jobs. For example, if you have the a sequence of jobs that include job1, job2, job3, job4, and job5, where job1 calls job2, job2 calls job3, job3 calls job5, and job4 calls job3. Specify only job1 and job4, and
If you do not specify this section,
JobParametersThe runtime parameters that are not in the DSX and ENV files. You can specify multiple job parameters. nameThe name of the job parameter. valueThe value of the job parameter. perJobParameters The parameters of a specific job. For example, you ingest multiple jobs where the parameters have the same name, but different values. Note This value takes precedence over the values specified in the JobParameters property. Otherwise, the original jobParameters field is used as the “default” option.jobIDThe ID of the job. nameThe name of the job parameter. valueThe value of the job parameter. Show me an example <source ID> configuration file{ "OdbcDataSources": { "oracle-data-source": { "dbname": "my-oracle-database", "schema": "my-oracle-schema", "dialect": "oracle", "collibraSystemName": "my-system" }, "mssql-data-source": { "dbname": "my-mssql-database", "schema": "my-mssql-schema", "dialect": "mssql", "collibraSystemName": "my-system" } }, "NonOdbcConnectors": { "admin@database-name": { "dbname": "my-netezza-database", "schema": "my-netezza-schema", "dialect": "netezza", "collibraSystemName": "my-system" }, "admin@second-database-name": { "dbname": "my-second-netezza-database", "schema": "my-second-netezza-schema", "dialect": "netezza", "collibraSystemName": "my-system" } }, "jobs": [ "my_job_1", "my_job_2" ], "jobParameters": [ { "value": "parameter_value_1" "value": "parameter_value_1" }, { "name": "parameter_name_2", "value": "parameter_value_2" } ] "perJobParameters": { "jobId1": [ { "name": "parameter_name_1", "value": "parameter_value_3" } ], "jobId2": [ { "name": "parameter_name_1", "value": "parameter_value_4" } ] } } No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
NameThe name of the Edge capability.
Yes
DescriptionThe description of the Edge capability.
Yes
Capability templateThe capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for DataStage Yes
Main Properties This section contains the information for creating a technical lineage.
Source IDThe name of the data source. Specify a name that is unique.
Yes
Shared Storage ConnectionThe Shared Storage connection that you created.
Yes
MaskThe pattern of the file names in the directory. By default, the value is
*. No
Source ConfigurationThe connection definitions, where you specify relevant translations for each data source. Specify the following properties in JSON format and enter the content in this field.
If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the connection_definitions.conf file in this field.Connection definition propertiesProperty
Description OdbcDataSources
Open Database Connectivity data sources in IBM InfoSphere DataStage for which you want to create a technical lineage.
<data-source-name>The ODBC data source name that you use in your DataStage projects.
This section contains the properties to translate the database, schema and dialect.
dbnameThe name of your database, to which the ODBC data source connection refers. schemaThe name of your schema, to which the ODBC data source connection refers.
dialectThe dialect of the referenced database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
collibraSystemNameThe system or server name of the data source.
Specify this property when you set the value of the Collibra system name setting to
True to override the default Collibra System asset name for this data source. Specify this property with the same name as the name of the System asset that you created when you registered the data source.
This property is optional.
NonOdbcConnectors
Other data source connectors in IBM InfoSphere DataStage for which you want to create a technical lineage. For example, DB2, Oracle or Netezza.
Note This section is optional.
<data-source-connector-ID>The data source username and database of the connector that you use in your DataStage projects. This usually looks like for example admin@database-name. The combination of the username and database name should be unique.
The following section contains the properties to translate the database, schema and dialect.
dbnameThe name of your database, to which the data source connection refers. schemaThe name of your schema, to which the data source connection refers.
dialectThe dialect of the referenced database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
collibraSystemNameThe system or server name of the data source.
Specify this property when you set the value of the Collibra system name setting to
True to override the default Collibra System asset name for this data source. Specify this property with the same name as the name of the System asset that you created when you registered the data source.
This property is optional.
Jobs
This section is optional. The following rules apply when you specify this section:
- Specify jobs that are executed so that the technical lineage graph does not include any job parameters with undefined values.
- Specify only the first and parent jobs in a sequence of executed jobs. For example, if you have the a sequence of jobs that include job1, job2, job3, job4, and job5, where job1 calls job2, job2 calls job3, job3 calls job5, and job4 calls job3. Specify only job1 and job4, and
If you do not specify this section,
JobParametersThe runtime parameters that are not in the DSX and ENV files. You can specify multiple job parameters. nameThe name of the job parameter. valueThe value of the job parameter. perJobParameters The parameters of a specific job. For example, you ingest multiple jobs where the parameters have the same name, but different values. Note This value takes precedence over the values specified in the JobParameters property. Otherwise, the original jobParameters field is used as the “default” option.jobIDThe ID of the job. nameThe name of the job parameter. valueThe value of the job parameter. Show me an example <source ID> configuration file{ "OdbcDataSources": { "oracle-data-source": { "dbname": "my-oracle-database", "schema": "my-oracle-schema", "dialect": "oracle", "collibraSystemName": "my-system" }, "mssql-data-source": { "dbname": "my-mssql-database", "schema": "my-mssql-schema", "dialect": "mssql", "collibraSystemName": "my-system" } }, "NonOdbcConnectors": { "admin@database-name": { "dbname": "my-netezza-database", "schema": "my-netezza-schema", "dialect": "netezza", "collibraSystemName": "my-system" }, "admin@second-database-name": { "dbname": "my-second-netezza-database", "schema": "my-second-netezza-schema", "dialect": "netezza", "collibraSystemName": "my-system" } }, "jobs": [ "my_job_1", "my_job_2" ], "jobParameters": [ { "value": "parameter_value_1" "value": "parameter_value_1" }, { "name": "parameter_name_2", "value": "parameter_value_2" } ] "perJobParameters": { "jobId1": [ { "name": "parameter_name_1", "value": "parameter_value_3" } ], "jobId2": [ { "name": "parameter_name_1", "value": "parameter_value_4" } ] } } No
PropertyThis section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On SourcesThis option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After ProcessingTechnical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze OnlyThis option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
ActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Db2 Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Important This field is mandatory, but the value you specify is not taken into consideration. We will remove this field in a future Collibra version.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Important This field is mandatory, but the value you specify is not taken into consideration. We will remove this field in a future Collibra version.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
Source ID
The name of the data source. Specify a name that is unique.
Yes
dbt Connection The dbt connection that you created.
Yes
Environment Ids The IDs of the environments that Collibra Data Lineage uses to download job artifacts.
Enter an array of environment IDs, for example
[123456, 987654]. This field is required if you do not enter a value for theAdmin URLfield in the dbt connection.If you enter values for both the Admin URL and Environment Ids fields, the Environment Ids field takes precedence.
No
Source Configuration
The source configuration to reduce the amount of data objects to be downloaded and enhance the performance of CollibraData Lineage in the following ways:
- Filter the projects and jobs to be downloaded. Include projects and jobs to be downloaded by specifying the
filterproperty. - Specify different Collibra system names for different projects by specifying the
collibraSystemNamesproperty . - Map a materialization as a view instead of a table by specifying the
materializedMappingproperty.
Specify the following properties in JSON format and enter the content in this field.
Example{ "collibraSystemNames":{ "projects":[ {"project_id":"654321","collibraSystemName":"SystemName"} ] }, "filter":{ "jobIds":[1234], "projectIds":[654321] }, "materializedMapping":{ "ELS_MATERIALIZE_MULTIPLE_EXTERNAL_TABLES":"VIEW" } }Connection definition propertiesProperty
Description Required?
collibraSystemNamesYou can use this section to specify the Collibra System Name for each project.
No
projectsThis section contains the project names and the Collibra system names.
No
project_idYour project ID. You can find the project ID in the dbt URL right after
projects. For example, if your dbt URL ishttps://cloud.getdbt.com/develop/54321/projects/12345, your project_id is12345.No
collibraSystemNameThe system or server name of the data source. This is also the name of your System asset in Data Catalog:
Specify this property with the same name as the name of the System asset that you created when you registered the data source.See an example.In this code example, the project with the
12345project ID is stitched to thesystemname1System asset in Data Catalog.{ "collibraSystemNames":{ "projects":[ {"project_id":"12345","collibraSystemName":"systemname1"} ] }, }No filterYou can use this section to include projects and jobs to be downloaded. Collibra Data Lineage downloads and processes only the specified jobs and projects.
See an example.In this code example, the job with the 1234 job ID and the projects with the 98 and 5678 project IDs are downloaded.
{ "filter": { "jobIds": [ 1234 ], "projectIds": [ 98, 5678 ] } }No
jobIdsThe job IDs of the jobs that you want to include.
Specify an integer. Do not specify a string.
To get your job ID, in your dbt, select Deploy and then Jobs. Select a job and you can find your job ID in the URL. For example, if your URL is
cloud.getdbt.com/deploy/65432/projects/23456/jobs/123456,123456is your job ID.No
projectIdsThe project IDs of the projects that you want to include.
Specify an integer. Do not specify a string.
You can find the project ID in the dbt URL right after
projects. For example, if your dbt URL ishttps://cloud.getdbt.com/develop/54321/projects/12345, your project_id is12345.No materializedMappingIndicates how materializations in dbt are mapped. If you do not specify this property, CollibraData Lineage maps materializations to tables by default. You can change the mapping of a materialization to view.
In the following example, the ELS_MATERIALIZE_MULTIPLE_EXTERNAL_TABLES materialization is mapped to a view.
"materializedMapping":{ "ELS_MATERIALIZE_MULTIPLE_EXTERNAL_TABLES":"VIEW" }No Tip If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the <sourceId>.conf file in this field. No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
NameThe name of the Edge capability.
Yes
DescriptionThe description of the Edge capability.
Yes
Capability templateThe capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for dbt Cloud Yes
Main Properties This section contains the information for creating a technical lineage.
Source IDThe name of the data source. Specify a name that is unique.
Yes
dbt ConnectionThe dbt connection that you created.
Yes
Environment IdsThe IDs of the environments that Collibra Data Lineage uses to download job artifacts.
Enter an array of environment IDs, for example
[123456, 987654]. This field is required if you do not enter a value for theAdmin URLfield in the dbt connection.If you enter values for both the Admin URL and Environment Ids fields, the Environment Ids field takes precedence.
No
Source ConfigurationThe source configuration to reduce the amount of data objects to be downloaded and enhance the performance of Collibra Data Lineage in the following ways:
- Filter the projects and jobs to be downloaded. Include projects and jobs to be downloaded by specifying the
filterproperty. - Specify different Collibra system names for different projects by specifying the
collibraSystemNamesproperty . - Map a materialization as a view instead of a table by specifying the
materializedMappingproperty.
Specify the following properties in JSON format and enter the content in this field.
Example{ "collibraSystemNames":{ "projects":[ {"project_id":"654321","collibraSystemName":"SystemName"} ] }, "filter":{ "jobIds":[1234], "projectIds":[654321] }, "materializedMapping":{ "ELS_MATERIALIZE_MULTIPLE_EXTERNAL_TABLES":"VIEW" } }Connection definition propertiesProperty
Description Required?
collibraSystemNamesYou can use this section to specify the Collibra System Name for each project.
No
projectsThis section contains the project names and the Collibra system names.
No
project_idYour project ID. You can find the project ID in the dbt URL right after
projects. For example, if your dbt URL ishttps://cloud.getdbt.com/develop/54321/projects/12345, your project_id is12345.No
collibraSystemNameThe system or server name of the data source. This is also the name of your System asset in Data Catalog:
Specify this property with the same name as the name of the System asset that you created when you registered the data source.See an example.In this code example, the project with the
12345project ID is stitched to thesystemname1System asset in Data Catalog.{ "collibraSystemNames":{ "projects":[ {"project_id":"12345","collibraSystemName":"systemname1"} ] }, }No filterYou can use this section to include projects and jobs to be downloaded. Collibra Data Lineage downloads and processes only the specified jobs and projects.
See an example.In this code example, the job with the 1234 job ID and the projects with the 98 and 5678 project IDs are downloaded.
{ "filter": { "jobIds": [ 1234 ], "projectIds": [ 98, 5678 ] } }No
jobIdsThe job IDs of the jobs that you want to include.
Specify an integer. Do not specify a string.
To get your job ID, in your dbt, select Deploy and then Jobs. Select a job and you can find your job ID in the URL. For example, if your URL is
cloud.getdbt.com/deploy/65432/projects/23456/jobs/123456,123456is your job ID.No
projectIdsThe project IDs of the projects that you want to include.
Specify an integer. Do not specify a string.
You can find the project ID in the dbt URL right after
projects. For example, if your dbt URL ishttps://cloud.getdbt.com/develop/54321/projects/12345, your project_id is12345.No materializedMappingIndicates how materializations in dbt are mapped. If you do not specify this property, CollibraData Lineage maps materializations to tables by default. You can change the mapping of a materialization to view.
In the following example, the ELS_MATERIALIZE_MULTIPLE_EXTERNAL_TABLES materialization is mapped to a view.
"materializedMapping":{ "ELS_MATERIALIZE_MULTIPLE_EXTERNAL_TABLES":"VIEW" }No Tip If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the <sourceId>.conf file in this field. No
PropertyThis section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced PropertiesThis section contains the advanced properties for creating a technical lineage.
Dependent On SourcesThis option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After ProcessingTechnical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze OnlyThis option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
ActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
Yes
Mask The pattern of the file names in the directory. By default, the value is
*. No
Source Configuration
The source configuration to reduce the amount of data objects to be processed and enhance the performance of Collibra Data Lineage.
Specify the following properties in JSON format and enter the content in this field.
Example{ "collibraSystemNames":{ "projects":[ {"collibraSystemName":"SystemName"} ] }, "materializedMapping":{ "ELS_MATERIALIZE_MULTIPLE_EXTERNAL_TABLES":"VIEW" } }Connection definition propertiesProperty
Description Required?
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
No
projectsThis section contains the Collibra system names.
No
collibraSystemNameThe system or server name of the data source. This is also the name of your System asset in Data Catalog:
Specify this property with the same name as the name of the System asset that you created when you registered the data source.See an example.In this code example, the project is stitched to the
systemname1System asset in Data Catalog.{ "collibraSystemNames":{ "projects":[ {"collibraSystemName":"systemname1"} ] }, }No materializedMappingIndicates how materializations in dbt are mapped. If you do not specify this property, CollibraData Lineage maps materializations to tables by default. You can change the mapping of a materialization to view.
In the following example, the ELS_MATERIALIZE_MULTIPLE_EXTERNAL_TABLES materialization is mapped to a view.
"materializedMapping":{ "ELS_MATERIALIZE_MULTIPLE_EXTERNAL_TABLES":"VIEW" }No No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
NameThe name of the Edge capability.
Yes
DescriptionThe description of the Edge capability.
Yes
Capability templateThe capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for dbt Yes
Main Properties This section contains the information for creating a technical lineage.
Source IDThe name of the data source. Specify a name that is unique.
Yes
Shared Storage ConnectionThe Shared Storage connection that you created.
Yes
MaskThe pattern of the file names in the directory. By default, the value is
*. No
Source ConfigurationThe source configuration to reduce the amount of data objects to be processed and enhance the performance of Collibra Data Lineage.
Specify the following properties in JSON format and enter the content in this field.
Example{ "collibraSystemNames":{ "projects":[ {"collibraSystemName":"SystemName"} ] }, "materializedMapping":{ "ELS_MATERIALIZE_MULTIPLE_EXTERNAL_TABLES":"VIEW" } }Connection definition propertiesProperty
Description Required?
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
No
projectsThis section contains the Collibra system names.
No
collibraSystemNameThe system or server name of the data source. This is also the name of your System asset in Data Catalog:
Specify this property with the same name as the name of the System asset that you created when you registered the data source.See an example.In this code example, the project is stitched to the
systemname1System asset in Data Catalog.{ "collibraSystemNames":{ "projects":[ {"collibraSystemName":"systemname1"} ] }, }No materializedMappingIndicates how materializations in dbt are mapped. If you do not specify this property, CollibraData Lineage maps materializations to tables by default. You can change the mapping of a materialization to view.
In the following example, the ELS_MATERIALIZE_MULTIPLE_EXTERNAL_TABLES materialization is mapped to a view.
"materializedMapping":{ "ELS_MATERIALIZE_MULTIPLE_EXTERNAL_TABLES":"VIEW" }No No
PropertyThis section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On SourcesThis option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After ProcessingTechnical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze OnlyThis option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
ActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for BigQuery Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Billing IDImportant This field is currently optional. In a future version of Collibra it will become mandatory.
The billing ID is a JDBC connection parameter that is required to execute the SQL statements to harvest the metadata. Enter the project ID of any single project for which you want to harvest metadata.
Tip You can then use the Project ID field to specify all of the other projects from which you want to harvest metadata.
No
Project IDUse this field to specify (by project ID) the project or projects from which you want to harvest metadata. Leave this field empty if you want to harvest the metadata from all projects for which the service account has permissions.
Tip Each field can only contain a single project ID. To list mutiple project IDs, click Add property, and then add the next project ID.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns
This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column.
Columns Tail
This query retrieves all columns tails.
Views
This query retrieves the view definitions.
Dataset names
This query retrieves all logical units in the project.
Other Queries
This query retrieves other data that technical lineage needs, for example stored procedures, functions, and packages.
Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Billing ID Important This field is currently optional. In a future version of Collibra it will become mandatory.
The billing ID is a JDBC connection parameter that is required to execute the SQL statements to harvest the metadata. Enter the project ID of any single project for which you want to harvest metadata.
Tip You can then use the Project ID field to specify all of the other projects from which you want to harvest metadata.
No
Project ID
Use this field to specify (by project ID) the project or projects from which you want to harvest metadata. Leave this field empty if you want to harvest the metadata from all projects for which the service account has permissions.
Tip Each field can only contain a single project ID. To list mutiple project IDs, click Add property, and then add the next project ID.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns
This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column.
Columns Tail
This query retrieves all columns tails.
Views
This query retrieves the view definitions.
Dataset names
This query retrieves all logical units in the project.
Other Queries
This query retrieves other data that technical lineage needs, for example stored procedures, functions, and packages.
Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Greenplum Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Important This field is mandatory, but the value you specify is not taken into consideration. We will remove this field in a future Collibra version.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Important This field is mandatory, but the value you specify is not taken into consideration. We will remove this field in a future Collibra version.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Hive Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
External Database Name
The database value to be used as the database name in the full path (system -> database -> schema -> table). Use this field to ensure successful stitching for a database-less data source. You can specify one of the following values:
CData, which CDATA drivers returned as a placeholder. Use this value if you did not create a custom database name by using theCustomizedDefaultCatalogNameproperty when you registered your data source.- The custom database name that you specified for the
CustomizedDefaultCatalogNameproperty when you registered your data source.
See an exampleWhen you registered a HiveQL data source on Edge and did not specify the
CustomizedDefaultCatalogNameproperty, the following full path to a column in Data Catalog is created and CData is used as the database name:Hive_123(system) >CData(database) >Hive_ABC(schema) >Table>ColumnWhen Collibra Data Lineage collects metadata from the HiveQL data source, the value of the Database Name field is used as the schema name because HiveQL is database-less.
If you do not enter a value for the External Database Name field, the value of the Collibra System Name field is used as the database name. If you set the Collibra system name setting to
true, the value of the Collibra System Name field is also used as the system name. In this case, the full path is shown as follows and does not match the full path in Data Catalog:Hive_123(system) >Hive_123(database) >Hive_ABC(schema) >Table>ColumnIn this case, the stitching is missing because of the mismatch of the full paths. To match the full path and preserve stitching, you must specify
CDatafor the External Database Name field. No
Database Name
The name of the database or schema (these terms are synonymous for Hive) from which you want to harvest metadata.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns
This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column.
Object Names
This query retrieves a list of object names from which technical lineage can be created. The objects can include stored procedures, views, macros, and so on. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
External Database Name
The database value to be used as the database name in the full path (system -> database -> schema -> table). Use this field to ensure successful stitching for a database-less data source. You can specify one of the following values:
CData, which CDATA drivers returned as a placeholder. Use this value if you did not create a custom database name by using theCustomizedDefaultCatalogNameproperty when you registered your data source.- The custom database name that you specified for the
CustomizedDefaultCatalogNameproperty when you registered your data source.
See an exampleWhen you registered a HiveQL data source on Edge and did not specify the
CustomizedDefaultCatalogNameproperty, the following full path to a column in Data Catalog is created and CData is used as the database name:Hive_123(system) >CData(database) >Hive_ABC(schema) >Table>ColumnWhen Collibra Data Lineage collects metadata from the HiveQL data source, the value of the Database Name field is used as the schema name because HiveQL is database-less.
If you do not enter a value for the External Database Name field, the value of the Collibra System Name field is used as the database name. If you set the Collibra system name setting to
true, the value of the Collibra System Name field is also used as the system name. In this case, the full path is shown as follows and does not match the full path in Data Catalog:Hive_123(system) >Hive_123(database) >Hive_ABC(schema) >Table>ColumnIn this case, the stitching is missing because of the mismatch of the full paths. To match the full path and preserve stitching, you must specify
CDatafor the External Database Name field. No
Database Name
The name of the database or schema (these terms are synonymous for Hive) from which you want to harvest metadata.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns
This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column.
Object Names
This query retrieves a list of object names from which technical lineage can be created. The objects can include stored procedures, views, macros, and so on. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
Source ID
The name of the data source. Specify a name that is unique.
Yes
IICS connection The Informatica Intelligent Cloud Services (IICS) connection that you created.
Note Collibra Data Intelligence Platform 2023.03 or newer is required to use the Informatica Intelligent Cloud Services (IICS) connection.
Yes
Objects The objects that you want to retrieve.
Each object requires a path and a type as shown in the following example, where,
path- The path to the object, which is relative to the Explore directory in IICS, for example,
Sales. typeThe type of the object, for example, Taskflow.
IICS scanner's starting point is a Taskflow or Linear Taskflow (Workflow). Therefore the only meaningful types to retrieve are: Taskflow, Workflow, Project and Folder.
The types are not case sensitive.
ExampleThe following example retrieves the Project, Folder, Taskflow, and Workflow objects.
[ { "path" : "Sales", "type" : "Project" }, { "path" : "Finance/Task_Flows", "type" : "Folder" }, { "path" : "Common/Task_Flows/tf_CalendarDimension", "type" : "Taskflow" }, { "path" : "Common/Linear_Task_Flows/wf_StateProvinceDimension", "type" : "Workflow" } ]Tip For more information about the objects that you can retrieve and the required information, go to the Informatica documentation.
Yes
Parameter Files Upload a ZIP file that contains Informatica Intelligent Cloud Services parameter files. You can name the ZIP file as you prefer. Ensure that the ZIP file contains all parameter files that you want CollibraData Lineage to collect.
No
Source Configuration
The connection definitions and system names. Specify the following properties in JSON format and enter the content in this field.
Connection definitionsProperty
Description Required? collibraSystemNames
This section contains the system information for Informatica Intelligent Cloud Services.
connectionsThis section contains the system connection information. This is required to reference to the system or server of the connection.
connectionNameThe name of the connection. The name must match the System asset name in Data Catalog for stitching.
Yes collibraSystemNameThe system or server name of the data source.
Use this property with the
useCollibraSystemNameproperty in the lineage harvester configuration file to override the default Collibra System asset name for this data source.Specify this property with the same name as the name of the System asset that you create when you prepare the physical data layer in Data Catalog. If you don't prepare the physical data layer, Collibra Data Lineage cannot stitch the data objects in your technical lineage to the assets in Data Catalog.
Specify this property with the same name as the name of the System asset that you created when you registered the data source.
No connectionDefinitions
This section contains the database, schema and dialect information for each connection in Informatica Intelligent Cloud Services.
Note You can add connection information for each connection in the
connectionssection.connectionNameThe name of the connection. The name must match with the name in a connection name in the
connectionssection.This property is required.
Yes databaseNameThe name of your database. The name must match the Database asset name in Data Catalog for stitching.
Yes schemaNameThe name of your schema. The name must match the Schema asset name in Data Catalog for stitching.
Yes dialectThe dialect of the connection. Specify this property for Collibra Data Lineage to properly extract and parse queries that are related to this connection.
You can enter one of the following values:
bigquerydb2hanahivegreenplummssqlmysqlnetezzaoraclepostgresredshiftsnowflakesparkteradata
No Example{ "collibraSystemNames": { "connections": [ { "connectionName": "DG_con_standby_cmdm_clientors", "collibraSystemName": "PUBLIC" }, { "connectionName": "DG_con_dev_dg_dgiauser_su", "collibraSystemName": "PUBLIC" } ] }, "connectionDefinitions": [ { "connectionName": "DG_con_standby_cmdm_clientors", "databaseName": "main", "schemaName": "dbo", "dialect": "oracle" }, { "connectionName": "DG_con_dev_dg_dgiauser_su", "databaseName": "main", "schemaName": "dbo", "dialect": "oracle" } ] }Tip If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the source ID configuration file in this field. No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
NameThe name of the Edge capability.
Yes
DescriptionThe description of the Edge capability.
Yes
Capability templateThe capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical lineage for Informatica Intelligent Cloud Services (IICS) Yes
Main Properties This section contains the information for creating a technical lineage.
Source IDThe name of the data source. Specify a name that is unique.
Yes
IICS connectionThe Informatica Intelligent Cloud Services (IICS) connection that you created.
Note Collibra Data Intelligence Platform 2023.03 or newer is required to use the Informatica Intelligent Cloud Services (IICS) connection.
No
ObjectsThe objects that you want to retrieve.
Each object requires a path and a type as shown in the following example, where,
path- The path to the object, which is relative to the Explore directory in IICS, for example,
Sales. typeThe type of the object, for example, Taskflow.
IICS scanner's starting point is a Taskflow or Linear Taskflow (Workflow). Therefore the only meaningful types to retrieve are: Taskflow, Workflow, Project and Folder.
The types are not case sensitive.
ExampleThe following example retrieves the Project, Folder, Taskflow, and Workflow objects.
[ { "path" : "Sales", "type" : "Project" }, { "path" : "Finance/Task_Flows", "type" : "Folder" }, { "path" : "Common/Task_Flows/tf_CalendarDimension", "type" : "Taskflow" }, { "path" : "Common/Linear_Task_Flows/wf_StateProvinceDimension", "type" : "Workflow" } ]Tip For more information about the objects that you can retrieve and the required information, go to the Informatica documentation.
Yes
Parameter FilesUpload a ZIP file that contains Informatica Intelligent Cloud Services parameter files. You can name the ZIP file as you prefer. Ensure that the ZIP file contains all parameter files that you want Collibra Data Lineage to collect.
No
Source ConfigurationThe connection definitions and system names. Specify the following properties in JSON format and enter the content in this field.
Connection definitionsProperty
Description Required? collibraSystemNames
This section contains the system information for Informatica Intelligent Cloud Services.
connectionsThis section contains the system connection information. This is required to reference to the system or server of the connection.
connectionNameThe name of the connection. The name must match the System asset name in Data Catalog for stitching.
Yes collibraSystemNameThe system or server name of the data source.
Use this property with the
useCollibraSystemNameproperty in the lineage harvester configuration file to override the default Collibra System asset name for this data source.Specify this property with the same name as the name of the System asset that you create when you prepare the physical data layer in Data Catalog. If you don't prepare the physical data layer, Collibra Data Lineage cannot stitch the data objects in your technical lineage to the assets in Data Catalog.
Specify this property with the same name as the name of the System asset that you created when you registered the data source.
No connectionDefinitions
This section contains the database, schema and dialect information for each connection in Informatica Intelligent Cloud Services.
Note You can add connection information for each connection in the
connectionssection.connectionNameThe name of the connection. The name must match with the name in a connection name in the
connectionssection.This property is required.
Yes databaseNameThe name of your database. The name must match the Database asset name in Data Catalog for stitching.
Yes schemaNameThe name of your schema. The name must match the Schema asset name in Data Catalog for stitching.
Yes dialectThe dialect of the connection. Specify this property for Collibra Data Lineage to properly extract and parse queries that are related to this connection.
You can enter one of the following values:
bigquerydb2hanahivegreenplummssqlmysqlnetezzaoraclepostgresredshiftsnowflakesparkteradata
No Example{ "collibraSystemNames": { "connections": [ { "connectionName": "DG_con_standby_cmdm_clientors", "collibraSystemName": "PUBLIC" }, { "connectionName": "DG_con_dev_dg_dgiauser_su", "collibraSystemName": "PUBLIC" } ] }, "connectionDefinitions": [ { "connectionName": "DG_con_standby_cmdm_clientors", "databaseName": "main", "schemaName": "dbo", "dialect": "oracle" }, { "connectionName": "DG_con_dev_dg_dgiauser_su", "databaseName": "main", "schemaName": "dbo", "dialect": "oracle" } ] }Tip If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the source ID configuration file in this field. No
PropertyThis section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On SourcesThis option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After ProcessingTechnical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze OnlyThis option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
ActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging
This section contains the properties for debug logging. This setting is not valid for this integration.
NoDebug
This setting is not valid for this integration. It should be set to false. NoField Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
Yes
Mask The pattern of the file names in the directory. By default, the value is
*. No
Source Configuration
The connection definitions and system names. Specify the following properties in JSON format and enter the content in this field.
If the connection definitions are provided but certain properties are not specified, an analyze error called CONFIGURATION is displayed in the transformations table on the Sources tab page when the technical lineage is created. The unspecified properties are marked as
UNDEFINEDin the analyze error. For more information about the analyze errors, go to Analyze errors and possible solutions in Technical lineage Sources tab page.Connection definitionsProperty
Description connectionDefinitions
This section contains the connection properties to a source in Informatica PowerCenter.
<connectionName>The type of your source or target data source.
This section contains the connection properties to a source or target in Informatica PowerCenter.
Note Define a connection in the connection definitions only once; specifically, define a data source with the<connectionName>property specified only once in the connection definitions. If you define a connection multiple times, unexpected lineage and stitching issues might occur.dbnameThe name of your source or target database. schemaThe name of your source or target schema.
dialectThe dialect of the referenced database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
collibraSystemNames
The system or server name of the data source.
Specify this property when you set the value of the Collibra system name setting to
True to override the default Collibra System asset name for this data source. Specify this property with the same name as the name of the System asset that you created when you registered the data source.
This property is optional.
databasesThis section contains the database information. This is required to connect directly to the system or server of the database.
dbnameThe name of the database. The database name is the same as the name you entered in the <connectionName> section. collibraSystemNameThe system or server name of the database.
connectionsThis section contains the connection information. This is required to reference to the system or server of the connection.
connectionNameThe name of the connection.
collibraSystemNameThe system or server name of the connection.
Important If you are using variables in Informatica PowerCenter, add the value of the variable instead of the name in the connection definitions. For example, if the parameter file contains$DBConnection_dwh=DWH_EXPORTthen you add the following connection definitions:{ "DWH_EXPORT": { "dbname": "DWH", "schema": "DBO" } }Example{ "connectionDefinitions": { "oracle_source": { "dbname": "oracle-source-database-name1", "schema": "my Oracle source schema", "dialect": "oracle" }, "oracle_target": { "dbname": "oracle-target-database-name2", "schema": "my other oracle target schema", "dialect": "oracle" } }, "collibraSystemNames": { "databases": [ { "dbname": "oracle-source-database-name1", "collibraSystemName": "oracle-system-name1" }, { "dbname": "oracle-target-database-name2", "collibraSystemName": "oracle-system-name2" } ], "connections": [ { "connectionName": "oracle-connection-name1", "collibraSystemName": "oracle-system-name1" }, { "connectionName": "oracle-connection-name2", "collibraSystemName": "oracle-system-name2" } ] } }Tip If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the source ID configuration file in this field. No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
NameThe name of the Edge capability.
Yes
DescriptionThe description of the Edge capability.
Yes
Capability templateThe capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Informatica PowerCenter Yes
Main Properties This section contains the information for creating a technical lineage.
Source IDThe name of the data source. Specify a name that is unique.
Yes
Shared Storage ConnectionThe Shared Storage connection that you created.
Yes
MaskThe pattern of the file names in the directory. By default, the value is
*. No
Source ConfigurationThe connection definitions and system names. Specify the following properties in JSON format and enter the content in this field.
If the connection definitions are provided but certain properties are not specified, an analyze error called CONFIGURATION is displayed in the transformations table on the Sources tab page when the technical lineage is created. The unspecified properties are marked as
UNDEFINEDin the analyze error. For more information about the analyze errors, go to Analyze errors and possible solutions in Technical lineage Sources tab page.Connection definitionsProperty
Description connectionDefinitions
This section contains the connection properties to a source in Informatica PowerCenter.
<connectionName>The type of your source or target data source.
This section contains the connection properties to a source or target in Informatica PowerCenter.
Note Define a connection in the connection definitions only once; specifically, define a data source with the<connectionName>property specified only once in the connection definitions. If you define a connection multiple times, unexpected lineage and stitching issues might occur.dbnameThe name of your source or target database. schemaThe name of your source or target schema.
dialectThe dialect of the referenced database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
collibraSystemNames
The system or server name of the data source.
Specify this property when you set the value of the Collibra system name setting to
True to override the default Collibra System asset name for this data source. Specify this property with the same name as the name of the System asset that you created when you registered the data source.
This property is optional.
databasesThis section contains the database information. This is required to connect directly to the system or server of the database.
dbnameThe name of the database. The database name is the same as the name you entered in the <connectionName> section. collibraSystemNameThe system or server name of the database.
connectionsThis section contains the connection information. This is required to reference to the system or server of the connection.
connectionNameThe name of the connection.
collibraSystemNameThe system or server name of the connection.
Important If you are using variables in Informatica PowerCenter, add the value of the variable instead of the name in the connection definitions. For example, if the parameter file contains$DBConnection_dwh=DWH_EXPORTthen you add the following connection definitions:{ "DWH_EXPORT": { "dbname": "DWH", "schema": "DBO" } }Example{ "connectionDefinitions": { "oracle_source": { "dbname": "oracle-source-database-name1", "schema": "my Oracle source schema", "dialect": "oracle" }, "oracle_target": { "dbname": "oracle-target-database-name2", "schema": "my other oracle target schema", "dialect": "oracle" } }, "collibraSystemNames": { "databases": [ { "dbname": "oracle-source-database-name1", "collibraSystemName": "oracle-system-name1" }, { "dbname": "oracle-target-database-name2", "collibraSystemName": "oracle-system-name2" } ], "connections": [ { "connectionName": "oracle-connection-name1", "collibraSystemName": "oracle-system-name1" }, { "connectionName": "oracle-connection-name2", "collibraSystemName": "oracle-system-name2" } ] } }Tip If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the source ID configuration file in this field. No
PropertyThis section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On SourcesThis option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After ProcessingTechnical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze OnlyThis option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
ActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging
This section contains the properties for debug logging. This setting is not valid for this integration.
NoDebug
This setting is not valid for this integration. It should be set to false. NoField Description Required Capability
This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
NoCapability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical lineage for Looker Yes
Main Properties
The required information for creating a technical lineage.
Source IDThe name of the data source. You can give this any name, as long as it is unique.
Warning You can only specify one source ID in this field, meaning you can only specify one source ID per
Warning If you are switching between the lineage harvester and Edge, the value in this field must exactly match the value of the
idproperty in your lineage harvester configuration file. Yes
Looker connectionThe Looker connection that you created for ingestion in Data Catalog.
Tip Select the name that you provided in the Name field when you created a connection to Looker.
Yes
Domain IDThe unique reference ID of the domain in Collibra Data Intelligence Platform in which you want to ingest the Looker assets.
How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Yes
Paging limitOptional property for customizing the Looker API pagination settings. The default value of "50" is sufficient in most cases; however, you can decrease it to help mitigate node limit errors, or increase it to speed up API calls. NoConcurrency levelThis optional property is intended to help if you are experiencing HTTP 401 Unauthorized errors due to too many concurrent HTTP calls, using the same token. It allows you to specify the internal sizing, meaning the amount of tasks that can be executed at the same time.
The default value is "15", meaning as many as 15 HTTP requests can take place in parallel. Consider reducing the value if you are experiencing HTTP 401 Unauthorized errors. Setting the value to "1" effectively disables the concurrency level, so that HTTP requests will be run in a synchronous manner, instead of in parallel.
NoConnection timeoutThis optional property is intended to help avoid timeout errors, when Edge attempts to connect to your Looker instance. The default value is "30", meaning a timeout error is thrown if a connection is not established within 30 seconds.
If timeout errors persist, try setting the value to "60" or "90".
NoSource configurationThis field allows you to provide JSON code, to:
- Filter on the Looker folders from which you want to ingest metadata.
- If
useCollibraSystemNamein the lineage harvester configuration file is set totrue, use thecollibraSystemNameproperty to specify the system name of databases in Looker.
Collibra Data Lineage uses the system names to match the structure of databases in Looker to assets in Data Catalog.
If you previously integrated Looker via the lineage harvester, you can copy and paste in this field the JSON code from your Looker <source ID> configuration file.
Property
Description Mandatory?
Connections
This section contains all Looker connections for which you want to create a technical lineage.
Yes
<connection name>The name of a connection object in Looker.
Yes
schemaThe name of the default schema of a supported data source in Looker.
If the lineage harvester fails to find a specific schema, it uses the default schema.
No
dbnameThe name of the database of a supported data source in Looker. No
collibraSystemNameThe system or server name of a database.
If you set the
useCollibraSystemNameproperty totruein your lineage harvester configuration file, but you either don't create a <source ID> configuration file, or don't specify a value for thecollibraSystemNameproperty in your <source ID> configuration file, the system name in the technical lineage is "DEFAULT".How do I configure this property if I have two databases with the same name?Let's assume you have two databases named Customers. When you prepare the physical data layer in Data Catalog, you create a System asset for each of these databases. Let's say you named them Customers-Europe and Customers-USA. You can then configure this property as follows.
"connection-object1": { "dialect": "mssql", "schema": "mssql-schema-name", "dbname": "Customers", "collibraSystemName": "Customers-Europe" }, "connection-object2": { "dialect": "oracle", "schema": "oracle-schema-name", "dbname": "Customers", "collibraSystemName": "Customers-USA" }Yes
filters Optionally, use this section to specify the Looker folders from which you want to ingest metadata.
Note You can filter on Looker folders, but not on Looker data sets. That's because Looker data sets are linked directly to the server, instead of a folder, as shown in the Looker metadata overview. Looker data sets are ingested in the default domain, regardless of any filtering.
Let’s say, for example, you filter on folder B. A Looker Folder asset is created in the specified domain in Collibra, and all of the metadata in folder B is ingested. If folder B has a parent folder A, then a Looker Folder asset is created (in the domain specified for folder B) to preserve the hierarchy, but no metadata from folder A is ingested.
You can specify more than one Looker folder for ingestion into a single domain in Collibra.
Warning If you don't want to filter on Looker Folders, you must completely remove this filters section.
Tip There are significant benefits to filtering by folder ID. For information, see the
filters>folderIdsproperty description.TipYou can use wildcards to capture multiple connection string combinations:
Show me the supported wildcardsPattern Description * Matches everything. ? Matches any single character. [seq] Matches any character in "seq". [!seq] Matches any character not in "seq". No domainIdThe unique resource ID of the domain (or domains), in Collibra, in which you want to ingest data objects from one or more Looker Folders.
Tip You can find the domain ID by clicking the domain type. Then look in the URL of your browser to find the ID. The URL looks like https://<yourcollibrainstance>/domain/<domain ID>?<view>.
descriptionAny description, as you see fit. folderNamesThe name (or names) of the Looker Folders from which you want to ingest.
Note You must specify either a folder name, a folder ID, or both.
The ID (or IDs) of the Looker Folder you want to ingest.
Note You must specify either a folder ID, a folder name, or both.
Tip If you filter by folder ID, filtering is carried out via the API, instead of on the Collibra Data Lineage service instances.
When you filter by folder ID, the lineage harvester accesses only the folders you specify via this property, and sends only that metadata to the Collibra Data Lineage service instance for processing and ingestion in Data Catalog. Conversely, if you filter by folder name (via thefolderNamesproperty), metadata from all Looker folders is sent to the Collibra Data Lineage service instance. Only then is filtering applied.What are the advantages?- Faster integration testing, as you can filter on a single folder.
- Enhanced data security and privacy by not harvesting folders that contain sensitive information.
- Improved processing times by not including folders dedicated to, for example, development and testing. This is especially beneficial for organizations with a lot of data in Looker.
Example{ "Connections":{ "connection-object1":{ "schema":"mssql-schema-name", "dbname":"mssql-database-name", "collibraSystemName":"mssql-system-name" }, "connection-object2":{ "schema":"oracle-schema-name", "dbname":"oracle-database-name", "collibraSystemName":"oracle-system-name" } }, "filters":[ { "domainId":"605fa8ae-f8c6-4261-938b-8326e2806f3d", "description":"Databricks_folder", "folderIds":[ "abc-123", "def-456" ] }, { "domainId":"245bc5a4-4c30-44b5-8356-ddbe708b56d6", "description":"personal", "folderIds":[ "hij-789*", "jkl-101112" ] } ] } NoCustom Properties
This section identifies to which Collibra Data Lineage service instance you want to upload the Looker metadata.
Warning This applies only for Collibra Cloud for Government customers.
techlinKeyThe unique API key to connect to the Collibra Data Lineage service instance.
A unique user key is needed for each Collibra environment. If you're not sure what your user key is, please contact your Collibra Customer Success Manager.
Warning This applies only for Collibra Cloud for Government customers.
NotechlinHostThe URL of he Collibra Data Lineage service instance to which you want to upload Tableau metadata, for example "techlin-gcp-eu.collibra.com".
Warning This applies only for Collibra Cloud for Government customers.
NoAdvanced Properties
This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
NoDelete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
NoAnalyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
NoActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
NoLogging
This section contains the properties for debug logging. This setting is not valid for this integration.
NoDebug
This setting is not valid for this integration. It should be set to false. NoField Description Required Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
NoSource ID
The name of the data source. You can give this any name, as long as it is unique.
Warning You can only specify one source ID in this field, meaning you can only specify one source ID per
Warning If you are switching between the lineage harvester and Edge, the value in this field must exactly match the value of the
idproperty in your lineage harvester configuration file.We highly recommend that you specify only one source ID per Looker service account.
Yes
Looker connection
The Looker connection that you created for ingestion in Data Catalog.
Tip Select the name that you provided in the Name field when you created a connection to Looker.
Yes
Domain ID
The unique reference ID of the domain in Collibra Data Intelligence Platform in which you want to ingest the Looker assets.
This is the default domain.
If you want to ingest the contents of specific Looker Folders into specific domains in Collibra, you specify the domain reference IDs in the filters section of your source configuration. See the Source Configuration field below.
How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Yes
Paging limit Optional property for customizing the Looker API pagination settings. The default value of "50" is sufficient in most cases; however, you can decrease it to help mitigate node limit errors, or increase it to speed up API calls. NoConcurrency level This optional property is intended to help if you are experiencing HTTP 401 Unauthorized errors due to too many concurrent HTTP calls, using the same token. It allows you to specify the internal sizing, meaning the amount of tasks that can be executed at the same time.
The default value is "15", meaning as many as 15 HTTP requests can take place in parallel. Consider reducing the value if you are experiencing HTTP 401 Unauthorized errors. Setting the value to "1" effectively disables the concurrency level, so that HTTP requests will be run in a synchronous manner, instead of in parallel.
NoConnection timeout This optional property is intended to help avoid timeout errors, when Edge attempts to connect to your Looker instance. The default value is "30", meaning a timeout error is thrown if a connection is not established within 30 seconds.
If timeout errors persist, try setting the value to "60" or "90".
NoSource configuration
This field allows you to provide JSON code, to:
- Filter on the Looker folders from which you want to ingest metadata.
- If
useCollibraSystemNamein the lineage harvester configuration file is set totrue, use thecollibraSystemNameproperty to specify the system name of databases in Looker.
Collibra Data Lineage uses the system names to match the structure of databases in Looker to assets in Data Catalog.
If you previously integrated Looker via the lineage harvester, you can copy and paste in this field the JSON code from your Looker <source ID> configuration file.
Property
Description Mandatory?
Connections
This section contains all Looker connections for which you want to create a technical lineage.
Yes
<connection name>The name of a connection object in Looker.
Yes
schemaThe name of the default schema of a supported data source in Looker.
If the lineage harvester fails to find a specific schema, it uses the default schema.
No
dbnameThe name of the database of a supported data source in Looker. No
collibraSystemNameThe system or server name of a database.
If you set the
useCollibraSystemNameproperty totruein your lineage harvester configuration file, but you either don't create a <source ID> configuration file, or don't specify a value for thecollibraSystemNameproperty in your <source ID> configuration file, the system name in the technical lineage is "DEFAULT".How do I configure this property if I have two databases with the same name?Let's assume you have two databases named Customers. When you prepare the physical data layer in Data Catalog, you create a System asset for each of these databases. Let's say you named them Customers-Europe and Customers-USA. You can then configure this property as follows.
"connection-object1": { "dialect": "mssql", "schema": "mssql-schema-name", "dbname": "Customers", "collibraSystemName": "Customers-Europe" }, "connection-object2": { "dialect": "oracle", "schema": "oracle-schema-name", "dbname": "Customers", "collibraSystemName": "Customers-USA" }Yes
filters Optionally, use this section to specify the Looker folders from which you want to ingest metadata.
Note You can filter on Looker folders, but not on Looker data sets. That's because Looker data sets are linked directly to the server, instead of a folder, as shown in the Looker metadata overview. Looker data sets are ingested in the default domain, regardless of any filtering.
Let’s say, for example, you filter on folder B. A Looker Folder asset is created in the specified domain in Collibra, and all of the metadata in folder B is ingested. If folder B has a parent folder A, then a Looker Folder asset is created (in the domain specified for folder B) to preserve the hierarchy, but no metadata from folder A is ingested.
You can specify more than one Looker folder for ingestion into a single domain in Collibra.
Warning If you don't want to filter on Looker Folders, you must completely remove this filters section.
Tip There are significant benefits to filtering by folder ID. For information, see the
filters>folderIdsproperty description.TipYou can use wildcards to capture multiple connection string combinations:
Show me the supported wildcardsPattern Description * Matches everything. ? Matches any single character. [seq] Matches any character in "seq". [!seq] Matches any character not in "seq". No domainIdThe unique resource ID of the domain (or domains), in Collibra, in which you want to ingest data objects from one or more Looker Folders.
Tip You can find the domain ID by clicking the domain type. Then look in the URL of your browser to find the ID. The URL looks like https://<yourcollibrainstance>/domain/<domain ID>?<view>.
descriptionAny description, as you see fit. folderNamesThe name (or names) of the Looker Folders from which you want to ingest.
Note You must specify either a folder name, a folder ID, or both.
The ID (or IDs) of the Looker Folder you want to ingest.
Note You must specify either a folder ID, a folder name, or both.
Tip If you filter by folder ID, filtering is carried out via the API, instead of on the Collibra Data Lineage service instances.
When you filter by folder ID, the lineage harvester accesses only the folders you specify via this property, and sends only that metadata to the Collibra Data Lineage service instance for processing and ingestion in Data Catalog. Conversely, if you filter by folder name (via thefolderNamesproperty), metadata from all Looker folders is sent to the Collibra Data Lineage service instance. Only then is filtering applied.What are the advantages?- Faster integration testing, as you can filter on a single folder.
- Enhanced data security and privacy by not harvesting folders that contain sensitive information.
- Improved processing times by not including folders dedicated to, for example, development and testing. This is especially beneficial for organizations with a lot of data in Looker.
Example{ "Connections":{ "connection-object1":{ "schema":"mssql-schema-name", "dbname":"mssql-database-name", "collibraSystemName":"mssql-system-name" }, "connection-object2":{ "schema":"oracle-schema-name", "dbname":"oracle-database-name", "collibraSystemName":"oracle-system-name" } }, "filters":[ { "domainId":"605fa8ae-f8c6-4261-938b-8326e2806f3d", "description":"Databricks_folder", "folderIds":[ "abc-123", "def-456" ] }, { "domainId":"245bc5a4-4c30-44b5-8356-ddbe708b56d6", "description":"personal", "folderIds":[ "hij-789*", "jkl-101112" ] } ] } NoProperty This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
NoAnalyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
NoActive
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
NoDebug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required Capability
This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
NoCapability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical lineage for SAP Analytics Cloud Yes
Main Properties
The required information for creating a technical lineage.
Source IDThe name of the data source. You can give this any name, as long as it is unique.
Warning You can only specify one source ID in this field, meaning you can only specify one source ID per
Yes
SAP Datasphere connectionThe SAP Datasphere Catalog connection that you created for ingestion in CollibraData Catalog.
Tip Select the name that you provided in the Name field when you created a connection to SAP Datasphere Catalog.
Yes
Domain IDThe unique reference ID of the domain in Collibra Data Intelligence Platform in which you want to ingest the SAP Analytics Cloud assets.
This is the default domain.
How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Yes
SAP Analytics Cloud tenant IDIf you have multiple SAP Analytics Cloud systems, but you only want to ingest metadata from one of them, this optional field allows you to specific from which system you want to integrate. If you leave this field empty, Edge ingests the metadata from all SAP Analytics Cloud systems.
Note Collibra Data Lineage can only ingest assets in SAP Datasphere that are published. For information on how to publish SAP Analytics Cloud assets in SAP Datasphere Catalog, see Set up SAP Analytics Cloud.
Show me how to find a tenant ID- In SAP, on the SAP Datasphere homepage, click Catalog > Monitoring.
The Remote Systems page opens. - Click the system name of your SAP Analytics Cloud. In this example, "88F0E".
- On the system details page, you'll find the tenant ID.
NoSource ConfigurationThis field allows you to provide JSON code to specify the SAP Analytics Cloud containers and folders from which you want to ingest metadata.
Property
Description Mandatory?
filters You can use this section to specify the SAP Analytics Cloud containers and folders from which you want to ingest metadata.
You can specify one domain in Collibra to which assets will be ingested.
The container and folder names in your filter are not case-sensitive.
TipYou can use wildcards to capture multiple connection string combinations:
Show me the supported wildcardsPattern Description * Matches everything. ? Matches any single character. [seq] Matches any character in "seq". [!seq] Matches any character not in "seq". Yes domainIdThe unique resource ID of the domain (or domains), in Collibra, in which you want to ingest data objects from one or more SAP Analytics Cloud containers and folders.
Tip You can find the domain ID by clicking the domain type. Then look in the URL of your browser to find the ID. The URL looks like https://<yourcollibrainstance>/domain/<domain ID>?<view>.
Yes folderPathThe name (or names) of the containers or folders from which you want to ingest.
Yes ExampleIn the following examples, we refer to an SAP Analytics Cloud container named "Container_A", which contains folders named "Folder_1", "Folder_2", and "Folder_3".
With the following configuration, everything in "Container_A" is ingested.
"filters": [ { "domainId": "018eeb60-f6cf-7ad0-bc7f-80ba0bb57464", "folderPath": ["Container_A"], } ]With the following configuration, everything in "Folder_1" and "Folder_2" are ingested, including any folders that are in those folder.
"filters": [ { "domainId": "018eeb60-f6cf-7ad0-bc7f-80ba0bb57464", "folderPath": [ "Container_A/Folder_1", "Container_A/Folder_2" ] } ] NoCustom Properties
This section identifies to which Collibra Data Lineage service instance you want to upload the Looker metadata.
Warning This applies only for Collibra Cloud for Government customers.
techlinKeyThe unique API key to connect to the Collibra Data Lineage service instance.
A unique user key is needed for each Collibra environment. If you're not sure what your user key is, please contact your Collibra Customer Success Manager.
Warning This applies only for Collibra Cloud for Government customers.
NotechlinHostThe URL of he Collibra Data Lineage service instance to which you want to upload Tableau metadata, for example "techlin-gcp-eu.collibra.com".
Warning This applies only for Collibra Cloud for Government customers.
NoAdvanced Properties
This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
NoDelete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
NoAnalyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
NoActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
NoLogging
This section contains the properties for debug logging. This setting is not valid for this integration.
NoDebug
This setting is not valid for this integration. It should be set to false. NoField Description Required Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
NoSource ID
The name of the data source. You can give this any name, as long as it is unique.
Warning You can only specify one source ID in this field, meaning you can only specify one source ID per
We highly recommend that you specify only one source ID per SAP Analytics Cloud system.
Yes
SAP Datasphere connection
The SAP Datasphere Catalog connection that you created for ingestion in Collibra Data Catalog.
Tip Select the name that you provided in the Name field when you created a connection to SAP Datasphere Catalog.
Yes
Domain ID
The unique reference ID of the domain in Collibra Data Intelligence Platform in which you want to ingest the SAP Analytics Cloud assets.
This is the default domain.
How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Yes
SAP Analytics Cloudtenant ID
If you have multiple SAP Analytics Cloud systems, but you only want to ingest metadata from one of them, this optional field allows you to specific from which system you want to integrate. If you leave this field empty, Edge ingests the metadata from all SAP Analytics Cloud systems.
Note Collibra Data Lineage can only ingest assets in SAP Datasphere that are published. For information on how to publish SAP Analytics Cloud assets in SAP Datasphere Catalog, see Set up SAP Analytics Cloud.
Show me how to find a tenant ID- In SAP, on the SAP Datasphere homepage, click Catalog > Monitoring.
The Remote Systems page opens. - Click the system name of your SAP Analytics Cloud. In this example, "88F0E".
- On the system details page, you'll find the tenant ID.
NoSource configuration
This field allows you to provide JSON code to specify the SAP Analytics Cloud containers and folders from which you want to ingest metadata.
Property
Description Mandatory?
filters You can use this section to specify the SAP Analytics Cloud containers and folders from which you want to ingest metadata.
You can specify one domain in Collibra to which assets will be ingested.
The container and folder names in your filter are not case-sensitive.
TipYou can use wildcards to capture multiple connection string combinations:
Show me the supported wildcardsPattern Description * Matches everything. ? Matches any single character. [seq] Matches any character in "seq". [!seq] Matches any character not in "seq". Yes domainIdThe unique resource ID of the domain (or domains), in Collibra, in which you want to ingest data objects from one or more SAP Analytics Cloud containers and folders.
Tip You can find the domain ID by clicking the domain type. Then look in the URL of your browser to find the ID. The URL looks like https://<yourcollibrainstance>/domain/<domain ID>?<view>.
Yes folderPathThe name (or names) of the containers or folders from which you want to ingest.
Yes ExampleIn the following examples, we refer to an SAP Analytics Cloud container named "Container_A", which contains folders named "Folder_1", "Folder_2", and "Folder_3".
With the following configuration, everything in "Container_A" is ingested.
"filters": [ { "domainId": "018eeb60-f6cf-7ad0-bc7f-80ba0bb57464", "folderPath": ["Container_A"], } ]With the following configuration, everything in "Folder_1" and "Folder_2" are ingested, including any folders that are in those folder.
"filters": [ { "domainId": "018eeb60-f6cf-7ad0-bc7f-80ba0bb57464", "folderPath": [ "Container_A/Folder_1", "Container_A/Folder_2" ] } ] NoProperty This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
NoAnalyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
NoActive
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
NoDebug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required Capability
This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
NoCapability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical lineage for SSRS/PBRS Yes
Main Properties
The required information for creating a technical lineage.
Source IDThe name of the data source. You can give this any name, as long as it is unique.
Warning You can only specify one source ID in this field, meaning you can only specify one source ID per
Warning If you are switching between the lineage harvester and Edge, the value in this field must exactly match the value of the
idproperty in your lineage harvester configuration file. Yes
Microsoft SSRS/PBRS connectionThe Microsoft SSRS/PBRS connection that you created for ingestion in Data Catalog.
Tip Select the name that you provided in the Name field when you created a connection to SSRS-PBRS.
Yes
Domain IDThe unique reference ID of the domain in Collibra Data Intelligence Platform in which you want to ingest the SSRS assets.
How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Yes
Folder FilterThis
Important This field is mandatory. If you want to ingest all folders, enter
*.You can filter on multiple folders by:
- Specifying folder names.
- Specifying the full path to folders.
- Using a wildcard.
- Using a combination of these approaches.
folder1, /database/folder2, /folder3/*
Show me some examplesScenario Configuration Ingest all folders with the name Folder3, anywhere in the folder hierarchy.
Folder3Note Reports in child folders of Folder3 are not included in the ingestion. As such:- Reports in
/Folder1/Folder2/Folder3are included in the ingestion. - Reports in
/Folder3/ChildFolderare not included in the ingestion.
Ingest Folder1 and Folder2.
Folder1, Folder2Ingest two folders that are both named Folder1.
In this case, specify the full paths to the folders, for example:
/Database1/Folder1, /Database2/Database3/Folder1Use a wildcard to ingest all child folders of Folder1.
/Folder1/*Note The reports in all child folders of Folder1 are ingested, but the reports in Folder1 itself are not ingested.Ingest all reports from Folder1 and all of the reports in the child folders of Folder1.
/Folder1/*, /Folder1Tip For more information about connecting to a SSRS or PBRS folder, see the Microsoft documentation.
Yes
Source configurationThis field allows you to provide JSON code, to:
The <source ID> configuration file allows you to:-
If
useCollibraSystemNamein the lineage harvester configuration file is set totrue, use thecollibraSystemNameproperty to specify the system name of databases in SSRS and PBRS. - Provide additional information about databases in SSRS and PBRS, which is necessary if the databases do not contain all information to process the SQL source code correctly.
If you previously integrated SSRS-PBRS via the lineage harvester, you can copy and paste in this field the JSON code from your SSRS-PBRS <source ID> configuration file.
Property
Description Required?
DataSources
This section contains all connections for which you want to create a technical lineage.
The
DataSourcessection refers to shared data sources in SSRS and PBRS. For more information about shared data sources, see the Microsoft documentation.Yes
<data source type>The path of a connection object in SSRS and PBRS.
Yes
dbnameThe name of the database of a supported data source in SSRS and PBRS. No
schemaThe name of the default schema of a supported data source in SSRS and PBRS.
No
dialectThe dialect of the supported data source in SSRS and PBRS.
No
collibraSystemNameThe system or server name of the database.
If you set the
useCollibraSystemNameproperty totruein your lineage harvester configuration file, but you either don't create a <source ID> configuration file, or don't specify a value for thecollibraSystemNameproperty in your <source ID> configuration file, the system name in the technical lineage is "DEFAULT".How do I configure this property if I have two databases with the same name?Let's assume you have two databases named Customers. When you prepare the physical data layer in Data Catalog, you create a System asset for each of these databases. Let's say you named them Customers-Europe and Customers-USA. You can then configure this property as follows.
"Redshift": { "dbname": "Customer", "schema": "redshift-schema-name", "dialect": "redshift", "collibraSystemName": "Customers-Europe" }, "Oracle": { "dbname": "Customer", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "Customers-USA" }Yes
CustomDataSources
You can use custom data processing extensions that are used to support embedded data sources of which the data source definition is specified locally in a report or embedded data set.
The
CustomDataSourcessection refers to embedded data sources in SSRS and PBRS. For more information about embedded data sources, see the Microsoft documentation.No
<path to report>/<custom data source name>The full path to the report and the custom data source name.
You can use wildcards to match multiple folders, reports or data sets. The connection information is this section is used to add missing information or to overwrite parsed information.
No
dbnameThe name of the database of a custom data source in SSRS and PBRS. No
schemaThe name of the schema of a custom data source in power. If you don't provide the schema name, the default schema is used.
No
dialectThe dialect of the custom data source in SSRS and PBRS.
Click for possible values:- azure, for an Azure SQL Server data source.
- bigquery, for a Google BigQuery data source.
- db2, for an IBM DB2 data source.
- hana, for a SAP Hana data source.
- hive, for a HiveQL data source.
- greenplum, for a Greenplum data source.
- mssql, for a Microsoft SQL Server data source.
- mysql, for a MySQL data source.
- netezza, for a Netezza data source.
- oracle, for an Oracle data source.
- postgres, for a PostgreSQL data source.
- redshift, for an Amazon Redshift data source.
- snowflake, for a Snowflake data source.
- spark, for a Spark SQL data source.
- sybase, for a Sybase data source.
- teradata, for a Teradata data source.
No
Example{ "DataSources": { "Redshift": { "dbname": "redshift-database-name", "schema": "redshift-schema-name", "dialect": "redshift", "collibraSystemName": "redshift-system-name" }, "Oracle": { "dbname": "oracle-database-name", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "oracle-system-name" } }, "CustomDataSources": { "/path to report/custom data souce name": { "dbname": "mssql-database-name", "dialect": "mssql" } } } NoCustom Properties
This section identifies to which Collibra Data Lineage service instance you want to upload the SSRS-PBRS metadata.
Warning This applies only for Collibra Cloud for Government customers.
techlinKeyThe unique API key to connect to the Collibra Data Lineage service instance.
A unique user key is needed for each Collibra environment. If you're not sure what your user key is, please contact your Collibra Customer Success Manager.
Warning This applies only for Collibra Cloud for Government customers.
NotechlinHostThe URL of he Collibra Data Lineage service instance to which you want to upload Tableau metadata, for example
techlin-gcp-eu.collibra.com.Warning This applies only for Collibra Cloud for Government customers.
NoAdvanced Properties
This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
NoAnalyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
NoActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
NoLogging
This section contains the properties for debug logging. This setting is not valid for this integration.
NoDebug
This setting is not valid for this integration. It should be set to false. NoField Description Required Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
NoSource ID
The name of the data source. You can give this any name, as long as it is unique.
Warning You can only specify one source ID in this field, meaning you can only specify one source ID per
Warning If you are switching between the lineage harvester and Edge, the value in this field must exactly match the value of the
idproperty in your lineage harvester configuration file.We highly recommend that you specify only one source ID per SSRS or PBRS service account.
Yes
Microsoft SSRS/PBRS connection
The Microsoft SSRS/PBRS connection that you created for ingestion in Data Catalog.
Tip Select the name that you provided in the Name field when you created a connection to SSRS-PBRS.
Yes
Domain ID
The unique reference ID of the domain in Collibra Data Intelligence Platform in which you want to ingest the SSRS assets.
How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Yes
Folder Filter This
Important This field is mandatory. If you want to ingest all folders, enter
*.You can filter on multiple folders by:
- Specifying folder names.
- Specifying the full path to folders.
- Using a wildcard.
- Using a combination of these approaches.
folder1, /database/folder2, /folder3/*
Show me some examplesScenario Configuration Ingest all folders with the name Folder3, anywhere in the folder hierarchy.
Folder3Note Reports in child folders of Folder3 are not included in the ingestion. As such:- Reports in
/Folder1/Folder2/Folder3are included in the ingestion. - Reports in
/Folder3/ChildFolderare not included in the ingestion.
Ingest Folder1 and Folder2.
Folder1, Folder2Ingest two folders that are both named Folder1.
In this case, specify the full paths to the folders, for example:
/Database1/Folder1, /Database2/Database3/Folder1Use a wildcard to ingest all child folders of Folder1.
/Folder1/*Note The reports in all child folders of Folder1 are ingested, but the reports in Folder1 itself are not ingested.Ingest all reports from Folder1 and all of the reports in the child folders of Folder1.
/Folder1/*, /Folder1Tip For more information about connecting to a SSRS or PBRS folder, see the Microsoft documentation.
Yes
Source configuration
This field allows you to provide <source ID> configuration file JSON code.
The <source ID> configuration file allows you to:-
If
useCollibraSystemNamein the lineage harvester configuration file is set totrue, use thecollibraSystemNameproperty to specify the system name of databases in SSRS and PBRS. - Provide additional information about databases in SSRS and PBRS, which is necessary if the databases do not contain all information to process the SQL source code correctly.
If you previously integrated SSRS-PBRS via the lineage harvester, you can copy and paste in this field the JSON code from your SSRS-PBRS <source ID> configuration file.
Property
Description Required?
DataSources
This section contains all connections for which you want to create a technical lineage.
The
DataSourcessection refers to shared data sources in SSRS and PBRS. For more information about shared data sources, see the Microsoft documentation.Yes
<data source type>The path of a connection object in SSRS and PBRS.
Yes
dbnameThe name of the database of a supported data source in SSRS and PBRS. No
schemaThe name of the default schema of a supported data source in SSRS and PBRS.
No
dialectThe dialect of the supported data source in SSRS and PBRS.
No
collibraSystemNameThe system or server name of the database.
If you set the
useCollibraSystemNameproperty totruein your lineage harvester configuration file, but you either don't create a <source ID> configuration file, or don't specify a value for thecollibraSystemNameproperty in your <source ID> configuration file, the system name in the technical lineage is "DEFAULT".How do I configure this property if I have two databases with the same name?Let's assume you have two databases named Customers. When you prepare the physical data layer in Data Catalog, you create a System asset for each of these databases. Let's say you named them Customers-Europe and Customers-USA. You can then configure this property as follows.
"Redshift": { "dbname": "Customer", "schema": "redshift-schema-name", "dialect": "redshift", "collibraSystemName": "Customers-Europe" }, "Oracle": { "dbname": "Customer", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "Customers-USA" }Yes
CustomDataSources
You can use custom data processing extensions that are used to support embedded data sources of which the data source definition is specified locally in a report or embedded data set.
The
CustomDataSourcessection refers to embedded data sources in SSRS and PBRS. For more information about embedded data sources, see the Microsoft documentation.No
<path to report>/<custom data source name>The full path to the report and the custom data source name.
You can use wildcards to match multiple folders, reports or data sets. The connection information is this section is used to add missing information or to overwrite parsed information.
No
dbnameThe name of the database of a custom data source in SSRS and PBRS. No
schemaThe name of the schema of a custom data source in power. If you don't provide the schema name, the default schema is used.
No
dialectThe dialect of the custom data source in SSRS and PBRS.
Click for possible values:- azure, for an Azure SQL Server data source.
- bigquery, for a Google BigQuery data source.
- db2, for an IBM DB2 data source.
- hana, for a SAP Hana data source.
- hive, for a HiveQL data source.
- greenplum, for a Greenplum data source.
- mssql, for a Microsoft SQL Server data source.
- mysql, for a MySQL data source.
- netezza, for a Netezza data source.
- oracle, for an Oracle data source.
- postgres, for a PostgreSQL data source.
- redshift, for an Amazon Redshift data source.
- snowflake, for a Snowflake data source.
- spark, for a Spark SQL data source.
- sybase, for a Sybase data source.
- teradata, for a Teradata data source.
No
Example{ "DataSources": { "Redshift": { "dbname": "redshift-database-name", "schema": "redshift-schema-name", "dialect": "redshift", "collibraSystemName": "redshift-system-name" }, "Oracle": { "dbname": "oracle-database-name", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "oracle-system-name" } }, "CustomDataSources": { "/path to report/custom data souce name": { "dbname": "mssql-database-name", "dialect": "mssql" } } } NoProperty This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
NoAnalyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
NoActive
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
NoDebug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
Source ID
The name of the data source. Specify a name that is unique.
Yes
Matillion connection The Matillion connection that you created.
Note Collibra Data Intelligence Platform 2023.03 or newer is required to use the Matillion connection.
No
Group Name The name of your group in Matillion. Yes
Project Name The name of your project in Matillion.
You can only add the name of one project. If you want to create a technical lineage for other projects, add a technical lineage for Matillion capability for each project.
Yes
Environment Name The name of your environment in Matillion.
You can only add the name of one environment. If you want to create a technical lineage for other environments, add a technical lineage for Matillion capability for each environment.
Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Start timestamp The timestamp of tasks in Matillion, which indicates the amount of metadata that technical lineage via Edge collects.
Specify this field with a UNIX timestamp in milliseconds. The default value is
1, which gets as much history as Matillion provides. Matillion provides 7 days of history by default. Yes
Source Configuration
The connection definitions and system names. Specify the following properties in JSON format and enter the content in this field.
Connection definitionsProperty
Description Mandatory?
found_dbname=<database name>;found_hostname=<server name>
The information of the supported data sources in Matillion to be collected by Collibra Data Lineage.
<database name>- The database name in Matillion.
<server name>- The name of the server that the database is running on. You can specify
found_hostname=*to include all servers.
TipYou can use wildcards to capture multiple connection string combinations:
Show me the supported wildcardsPattern Description * Matches everything. ? Matches any single character. [seq] Matches any character in "seq". [!seq] Matches any character not in "seq". Yes
dbnameThe name of the database asset in Data Catalog.
If you leave this property blank, the database is stitched to the database of DEFAULT in Data Catalog.
No
schemaThe name of the schema asset in Data Catalog. Specify this property with the schema name that you created when you registered the data source.
If you leave this property blank, the schema is stitched to the schema of DEFAULT in Data Catalog.
No
dialectSelect one of the following dialects for your data source
Click here for a list of dialects of supported data sources in Matillion.- azure, for an Azure SQL Server data source.
- bigquery, for a Google BigQuery data source.
- db2, for a IBM Db2 data source.
- generic, for any data source.
- greenplum, for a Greenplum data source.
- hana, for a SAP HANA data source.
- hive, for a Hive data source.
- impala, for a Impala data source.
- mssql, for a Microsoft SQL Server data source.
- mysql, for a MySQL data source.
- netezza, for a Netezza data source.
- oracle, for an Oracle data source.
- postgres, for an PostgreSQL data source.
- redshift, for an Amazon Redshift data source.
- snowflake, for a Snowflake data source.
- spark, for a Spark SQL data source.
- sybase, for a Sybase data source.
- teradata, for a Teradata data source.
- vertica, for a Vertica data source.
No
collibraSystemNameThe system or server name of the data source. Specify this property when you set the value of the Collibra system name setting to
True to override the default Collibra System asset name for this data source. Specify this property with the same name as the name of the System asset that you created when you registered the data source.If you leave this property blank, the system is stitched to the system of DEFAULT in Data Catalog. If you are missing lineage or your lineage objects aren’t stitching to Catalog assets in Data Catalog as you expect, ensure this property is specified properly.
How do I configure this property if I have two databases with the same name?For example, if you have two databases named Customers.
{ "found_dbname=dbtest;found_hostname=test": { "dbname": "Customers", "dialect": "mssql", "collibraSystemName": "Customers-Europe" }, "found_dbname=testsid;found_hostname=*": { "dbname": "Customers", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "Customers-USA" } }Warning The value of this property must exactly match (including for case-sensitivity) the name of your System asset in Collibra.
No
Example{ "found_dbname=dbtest;found_hostname=test": { "collibraSystemName": "mssql-system-name" }, "found_dbname=testsid;found_hostname=*": { "dbname": "oracle-database-name", "schema": "oracle-schema-name", "collibraSystemName": "oracle-system-name" } }Tip If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the source ID configuration file in this field. No
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
NameThe name of the Edge capability.
Yes
DescriptionThe description of the Edge capability.
Yes
Capability templateThe capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Matillion Yes
Main Properties This section contains the information for creating a technical lineage.
Source IDThe name of the data source. Specify a name that is unique.
Yes
Matillion connectionThe Matillion connection that you created.
Note Collibra Data Intelligence Platform 2023.03 or newer is required to use the Matillion connection.
No
Group NameThe name of your group in Matillion. Yes
Project NameThe name of your project in Matillion.
You can only add the name of one project. If you want to create a technical lineage for other projects, add a technical lineage for Matillion capability for each project.
Yes
Environment NameThe name of your environment in Matillion.
You can only add the name of one environment. If you want to create a technical lineage for other environments, add a technical lineage for Matillion capability for each environment.
Yes
DialectThe dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Start timestampThe timestamp of tasks in Matillion, which indicates the amount of metadata that technical lineage via Edge collects.
Specify this field with a UNIX timestamp in milliseconds. The default value is
1, which gets as much history as Matillion provides. Matillion provides 7 days of history by default. Yes
Source ConfigurationThe connection definitions and system names. Specify the following properties in JSON format and enter the content in this field.
Connection definitionsProperty
Description Mandatory?
found_dbname=<database name>;found_hostname=<server name>
The information of the supported data sources in Matillion to be collected by Collibra Data Lineage.
<database name>- The database name in Matillion.
<server name>- The name of the server that the database is running on. You can specify
found_hostname=*to include all servers.
TipYou can use wildcards to capture multiple connection string combinations:
Show me the supported wildcardsPattern Description * Matches everything. ? Matches any single character. [seq] Matches any character in "seq". [!seq] Matches any character not in "seq". Yes
dbnameThe name of the database asset in Data Catalog.
If you leave this property blank, the database is stitched to the database of DEFAULT in Data Catalog.
No
schemaThe name of the schema asset in Data Catalog. Specify this property with the schema name that you created when you registered the data source.
If you leave this property blank, the schema is stitched to the schema of DEFAULT in Data Catalog.
No
dialectSelect one of the following dialects for your data source
Click here for a list of dialects of supported data sources in Matillion.- azure, for an Azure SQL Server data source.
- bigquery, for a Google BigQuery data source.
- db2, for a IBM Db2 data source.
- generic, for any data source.
- greenplum, for a Greenplum data source.
- hana, for a SAP HANA data source.
- hive, for a Hive data source.
- impala, for a Impala data source.
- mssql, for a Microsoft SQL Server data source.
- mysql, for a MySQL data source.
- netezza, for a Netezza data source.
- oracle, for an Oracle data source.
- postgres, for an PostgreSQL data source.
- redshift, for an Amazon Redshift data source.
- snowflake, for a Snowflake data source.
- spark, for a Spark SQL data source.
- sybase, for a Sybase data source.
- teradata, for a Teradata data source.
- vertica, for a Vertica data source.
No
collibraSystemNameThe system or server name of the data source. Specify this property when you set the value of the Collibra system name setting to
True to override the default Collibra System asset name for this data source. Specify this property with the same name as the name of the System asset that you created when you registered the data source.If you leave this property blank, the system is stitched to the system of DEFAULT in Data Catalog. If you are missing lineage or your lineage objects aren’t stitching to Catalog assets in Data Catalog as you expect, ensure this property is specified properly.
How do I configure this property if I have two databases with the same name?For example, if you have two databases named Customers.
{ "found_dbname=dbtest;found_hostname=test": { "dbname": "Customers", "dialect": "mssql", "collibraSystemName": "Customers-Europe" }, "found_dbname=testsid;found_hostname=*": { "dbname": "Customers", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "Customers-USA" } }Warning The value of this property must exactly match (including for case-sensitivity) the name of your System asset in Collibra.
No
Example{ "found_dbname=dbtest;found_hostname=test": { "collibraSystemName": "mssql-system-name" }, "found_dbname=testsid;found_hostname=*": { "dbname": "oracle-database-name", "schema": "oracle-schema-name", "collibraSystemName": "oracle-system-name" } }Tip If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the source ID configuration file in this field. No
Collibra System NameThe system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
PropertyThis section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On SourcesThis option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After ProcessingTechnical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze OnlyThis option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
ActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required Capability
This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
NoCapability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical lineage for MicroStrategy Yes
Main Properties
The required information for creating a technical lineage.
Source IDThe name of the data source. You can give this any name, as long as it is unique.
Warning You can only specify one source ID in this field, meaning you can only specify one source ID per
Warning If you are switching between the lineage harvester and Edge, the value in this field must exactly match the value of the
idproperty in your lineage harvester configuration file. Yes
MicroStrategy connectionThe MicroStrategy connection that you created for ingestion in Data Catalog.
Tip Select the name that you provided in the Name field when you created a connection to MicroStrategy.
Yes
Domain IDThe unique reference ID of the domain in Collibra Data Intelligence Platform in which you want to ingest the MicroStrategy assets.
How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Yes
URL for reportsThis optional property ensures that the correct URL to data objects in MicroStrategy is included on the asset pages of corresponding MicroStrategy assets. The required value depends on which platform you run MicroStrategy: - For J2EE, use:
"appUrlSuffix": "MicroStrategy/servlet/mstrWeb" -
For .NET, use:
"appUrlSuffix": "MicroStrategy/asp/Main.aspx"
NoMicroStrategy Library URLIf you are using a custom URL to connect to the MicroStrategy Library Server, use this
Important You only need to specify the URL if both of the following are true:- You are connecting to a proxy server.
-
You are not using the default, hardcoded URL to the MicroStrategy Library Server.
Example If the URL to your MicroStrategy Library is https://collibra.microstrategy.com/MicroStrategyLibrary/api, you don't need to use this
"microStrategyLibraryUrl": "MicroStrategyLibraryProd"
NoSource configurationThis field allows you to provide JSON code, to:
- Specify the default domain, meaning the domain in Collibra in which the corresponding assets of MicroStrategy metadata will be ingested if domain mapping is not configured.Note If you do configure domain mapping, the default domain is still the destination domain of the MicroStrategy Server asset.
- Optionally, specify from which MicroStrategy projects you want to ingest metadata, and into which domains you want to ingest the corresponding assets.
-
Optionally, configure data source mapping, to map the name of a data source returned by the lineage harvester to the true name of the data source.Note Mapping doesn't work for custom SQL.
If you previously integrated MicroStrategy via the lineage harvester, you can copy and paste in this field the JSON code from your MicroStrategy <source ID> configuration file.
Property
Description
Mandatory
default_domain_id
The domain in which you want the corresponding assets of MicroStrategy metadata to be ingested.
Note If you configure filtering, only the MicroStrategy Server asset is ingested into this default domain.
Yes
This section allows you to specify:
- From which MicroStrategy projects you want to harvest metadata.
- Into which domains in Collibra you want to ingest the corresponding assets.
If you don't want to filter on projects, don't include this section in your <source ID> configuration file.
No
domainIdThe unique resource ID of the domain (or domains) in Collibra in which you want to ingest the MicroStrategy assets.
Tip If you use afilterssection, you must include thedomainIdproperty in the section. If, by chance, you want to filter on certain projects, but you want to ingest all assets into the default domain, then the value of thedomainIdproperty must match the value of thedefault_domain_idproperty.Show me an example"default_domain_id": "1234567890", "filters": [ { "domainId": "1234567890", "projectNames": ["MicroStrategy Tutorial","Testing_MSTR"] },How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
No
projectIdsThe IDs of the MicroStrategy projects from which you want to ingest metadata. No
projectNamesThe project names of the MicroStrategy projects from which you want to ingest metadata. No
datasourceMapping
This optional section allows you to configure data source mapping. Include this section only if you need to differentiate between multiple data sources that have the same name.
Note Mapping doesn't work for custom SQL.No
found_datasourceThe name of the data source that was returned by the lineage harvester, as shown in the technical lineage.
Note The data source name is case-sensitive.Yes
found_projectThe name of the project in which the data source information resides. You can specify an asterisk (*) to search for data source information across all projects.
Yes
mappingUse this section to map the data source name that was returned by the lineage harvester to the true name of the data source.
Example You have a Redshift data source named "RD_pearl", but the lineage harvester has returned the name "Redshift_connection". You can configure thedatasourceMappingsection as follows:{ "datasourceMapping": [ { "found_datasource": "REDSHIFT", "found_project": "*", "mapping": { "dbname": "RD_pearl", "collibraSystemName": "TV_dev" } } ] }Yes
dbnameThe name of the database to which you want to map the found data source.
Yes
schemaThe name of the schema in MicroStrategy.
No
dialectThe dialect of the data source in MicroStrategy.
No
collibraSystemNameThe system or server name of a database.
If you set the
useCollibraSystemNameproperty totruein your lineage harvester configuration file, but you either don't create a <source ID> configuration file, or don't specify a value for thecollibraSystemNameproperty in your <source ID> configuration file, the system name in the technical lineage is "DEFAULT".If you set the
useCollibraSystemNameproperty tofalsein your lineage harvester configuration file, leave this property empty as follows:"collibraSystemName": "".How do I configure this property if I have two databases with the same name?Let's assume that you have a data source named Customers. You use this data source connection in two different projects, Project_A and Project_B, but they are actually two different databases. When you prepare the physical data layer in Data Catalog, you create a System asset for each of these databases. Let's say you named them Customers-North and Customers-South. You can then configure this property as follows.
"datasourceMapping": [ { "found_datasource": "Customers", "found_project": "Project_A", "mapping": { "dbname": "Customers", "collibraSystemName": "Customers_North" } }, { "found_datasource": "Customers", "found_project": "Project_B", "mapping": { "dbname": "Customers", "collibraSystemName": "Customers_South" } } ]Warning The values of this property must exactly match the name of your System asset in Collibra.
Yes
Example{ "default_domain_id": "66ab7911-d84a-43d6-b9f7-40130jd84ds98", "filters": [ { "domainId": "3ae946ec-9030-46b8-ad86-a217b8f99bab", "projectIDs": ["3FF7CF7D4C5A2AEBF14D8B9802698B27"] }, { "domainId": "21cfb3ae-0616-478e-9060-114130540be5", "projectNames": ["Human Resources Analysis Module"] } ], "datasourceMapping": [ { "found_datasource": "REDSHIFT", "found_project": "*", "mapping": { "dbname": "RD_pearl", "schema": "Default_North", "dialect": "spark", "collibraSystemName": "TV_dev" } } ] } NoCustom Properties
This section identifies to which Collibra Data Lineage service instance you want to upload the MicroStrategy metadata.
Warning This applies only for Collibra Cloud for Government customers.
techlinKeyThe unique API key to connect to the Collibra Data Lineage service instance.
A unique user key is needed for each Collibra environment. If you're not sure what your user key is, please contact your Collibra Customer Success Manager.
Warning This applies only for Collibra Cloud for Government customers.
NotechlinHostThe URL of he Collibra Data Lineage service instance to which you want to upload Tableau metadata, for example "techlin-gcp-eu.collibra.com".
Warning This applies only for Collibra Cloud for Government customers.
NoAdvanced Properties
This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
NoAnalyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
NoActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
NoMaximum parallel requestsThis optional property allows you to specify the internal sizing, meaning the amount of tasks that can be executed at the same time.
The default value is "1", which means that HTTP requests are run in a synchronous manner, instead of in parallel. As value of "5", for example, means that as many as 5 HTTP requests can take place in parallel.
A lower value reduces the chances of experiencing HTTP 401 Unauthorized errors.
NoLogging
This section contains the properties for debug logging. This setting is not valid for this integration.
Debug
This setting is not valid for this integration. It should be set to false. NoField Description Required Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
NoSource ID
The name of the data source. You can give this any name, as long as it is unique.
Warning You can only specify one source ID in this field, meaning you can only specify one source ID per
Warning If you are switching between the lineage harvester and Edge, the value in this field must exactly match the value of the
idproperty in your lineage harvester configuration file.We highly recommend that you specify only one source ID per MicroStrategy Intelligence Server.
Yes
MicroStrategy connection
The MicroStrategy connection that you created for ingestion in Data Catalog.
Tip Select the name that you provided in the Name field when you created a connection to MicroStrategy.
Yes
Domain ID
The unique reference ID of the domain in Collibra Data Intelligence Platform in which you want to ingest the MicroStrategy assets.
How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Yes
URL for reports
This optional property ensures that the correct URL to data objects in MicroStrategy is included on the asset pages of corresponding MicroStrategy assets. The required value depends on which platform you run MicroStrategy: - For J2EE, use:
"appUrlSuffix": "MicroStrategy/servlet/mstrWeb" -
For .NET, use:
"appUrlSuffix": "MicroStrategy/asp/Main.aspx"
Yes
MicroStrategy Library URL
If you are using a custom URL to connect to the MicroStrategy Library Server, use this
Important You only need to specify the URL if both of the following are true:- You are connecting to a proxy server.
-
You are not using the default, hardcoded URL to the MicroStrategy Library Server.
Example If the URL to your MicroStrategy Library is https://collibra.microstrategy.com/MicroStrategyLibrary/api, you don't need to use this
"microStrategyLibraryUrl": "MicroStrategyLibraryProd"
NoSource configuration
This field allows you to provide JSON code, to:
- Specify the default domain, meaning the domain in Collibra in which the corresponding assets of MicroStrategy metadata will be ingested if domain mapping is not configured.Note If you do configure domain mapping, the default domain is still the destination domain of the MicroStrategy Server asset.
- Optionally, specify from which MicroStrategy projects you want to ingest metadata, and into which domains you want to ingest the corresponding assets.
-
Optionally, configure data source mapping, to map the name of a data source returned by the lineage harvester to the true name of the data source.Note Mapping doesn't work for custom SQL.
If you previously integrated MicroStrategy via the lineage harvester, you can copy and paste in this field the JSON code from your MicroStrategy<source ID> configuration file.
Property
Description
Mandatory
default_domain_id
The domain in which you want the corresponding assets of MicroStrategy metadata to be ingested.
Note If you configure filtering, only the MicroStrategy Server asset is ingested into this default domain.
Yes
This section allows you to specify:
- From which MicroStrategy projects you want to harvest metadata.
- Into which domains in Collibra you want to ingest the corresponding assets.
If you don't want to filter on projects, don't include this section in your <source ID> configuration file.
No
domainIdThe unique resource ID of the domain (or domains) in Collibra in which you want to ingest the MicroStrategy assets.
Tip If you use afilterssection, you must include thedomainIdproperty in the section. If, by chance, you want to filter on certain projects, but you want to ingest all assets into the default domain, then the value of thedomainIdproperty must match the value of thedefault_domain_idproperty.Show me an example"default_domain_id": "1234567890", "filters": [ { "domainId": "1234567890", "projectNames": ["MicroStrategy Tutorial","Testing_MSTR"] },How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
No
projectIdsThe IDs of the MicroStrategy projects from which you want to ingest metadata. No
projectNamesThe project names of the MicroStrategy projects from which you want to ingest metadata. No
datasourceMapping
This optional section allows you to configure data source mapping. Include this section only if you need to differentiate between multiple data sources that have the same name.
Note Mapping doesn't work for custom SQL.No
found_datasourceThe name of the data source that was returned by the lineage harvester, as shown in the technical lineage.
Note The data source name is case-sensitive.Yes
found_projectThe name of the project in which the data source information resides. You can specify an asterisk (*) to search for data source information across all projects.
Yes
mappingUse this section to map the data source name that was returned by the lineage harvester to the true name of the data source.
Example You have a Redshift data source named "RD_pearl", but the lineage harvester has returned the name "Redshift_connection". You can configure thedatasourceMappingsection as follows:{ "datasourceMapping": [ { "found_datasource": "REDSHIFT", "found_project": "*", "mapping": { "dbname": "RD_pearl", "collibraSystemName": "TV_dev" } } ] }Yes
dbnameThe name of the database to which you want to map the found data source.
Yes
schemaThe name of the schema in MicroStrategy.
No
dialectThe dialect of the data source in MicroStrategy.
No
collibraSystemNameThe system or server name of a database.
If you set the
useCollibraSystemNameproperty totruein your lineage harvester configuration file, but you either don't create a <source ID> configuration file, or don't specify a value for thecollibraSystemNameproperty in your <source ID> configuration file, the system name in the technical lineage is "DEFAULT".If you set the
useCollibraSystemNameproperty tofalsein your lineage harvester configuration file, leave this property empty as follows:"collibraSystemName": "".How do I configure this property if I have two databases with the same name?Let's assume that you have a data source named Customers. You use this data source connection in two different projects, Project_A and Project_B, but they are actually two different databases. When you prepare the physical data layer in Data Catalog, you create a System asset for each of these databases. Let's say you named them Customers-North and Customers-South. You can then configure this property as follows.
"datasourceMapping": [ { "found_datasource": "Customers", "found_project": "Project_A", "mapping": { "dbname": "Customers", "collibraSystemName": "Customers_North" } }, { "found_datasource": "Customers", "found_project": "Project_B", "mapping": { "dbname": "Customers", "collibraSystemName": "Customers_South" } } ]Warning The values of this property must exactly match the name of your System asset in Collibra.
Yes
Example{ "default_domain_id": "66ab7911-d84a-43d6-b9f7-40130jd84ds98", "filters": [ { "domainId": "3ae946ec-9030-46b8-ad86-a217b8f99bab", "projectIDs": ["3FF7CF7D4C5A2AEBF14D8B9802698B27"] }, { "domainId": "21cfb3ae-0616-478e-9060-114130540be5", "projectNames": ["Human Resources Analysis Module"] } ], "datasourceMapping": [ { "found_datasource": "REDSHIFT", "found_project": "*", "mapping": { "dbname": "RD_pearl", "schema": "Default_North", "dialect": "spark", "collibraSystemName": "TV_dev" } } ] } NoProperty This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
NoAnalyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
NoActive
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
NoMaximum parallel requests
This optional property allows you to specify the internal sizing, meaning the amount of tasks that can be executed at the same time.
The default value is "1", which means that HTTP requests are run in a synchronous manner, instead of in parallel. As value of "5", for example, means that as many as 5 HTTP requests can take place in parallel.
A lower value reduces the chances of experiencing HTTP 401 Unauthorized errors.
NoDebug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for MySQL Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Netezza Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Oracle Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Important This field is mandatory, but the value you specify is not taken into consideration. We will remove this field in a future Collibra version.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Database Links This query retrieves links to other databases. Synonyms This query retrieves the alternative names for the database objects. Views This query retrieves the view definitions. Materialized Views This query retrieves materialized view definitions. Other Queries This query retrieves other data that technical lineage needs, for example stored procedures, functions, and packages. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Important This field is mandatory, but the value you specify is not taken into consideration. We will remove this field in a future Collibra version.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Database Links This query retrieves links to other databases. Synonyms This query retrieves the alternative names for the database objects. Views This query retrieves the view definitions. Materialized Views This query retrieves materialized view definitions. Other Queries This query retrieves other data that technical lineage needs, for example stored procedures, functions, and packages. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Database Link Mapping If you are using DBLinks, this optional
The configuration format is as follows:
{"<database whatlink>": {"database":"<database>","schema":"<schema>"}, ...}Tip If you’re using a DBLink to target another source, you need to share the database model between the targeted (independent) source and the dependent source. Use the
Show me an exampleLet's say that you have two Oracle data sources, A and B.
Source A
You have the following database configuration:
- Database_A > Schema_A1 > Table_1 > Column_1, Column_2
- Database_A > Schema_A2 > Table_2 > Column_x, Column_y
Source B
You have DBLinks with names
dblink.example.com,dblink2.example.com, anddblink3.example.com, all of which point to Source A.Tip Configure the
You want your DBLink aliases configured as follows:
- dblink.example.com → Database_A > Schema_A1
- dblink2.example.com → Database_A > Schema_A1
- dblink3.example.com → Database_A > Schema_A2
You specify this in the Database Link Mapping field as follows:
{ "dblink.example.com": {"database":"Database_A","schema":"Schema_A1"}, "dblink2.example.com": {"database":"Database_A","schema":"Schema_A1"}, "dblink3.example.com": {"database":"Database_A","schema":"Schema_A2"} }With this done, the following examples queries on Source B are successfully analyzed by the Collibra Data Lineage service instance:
- select * from [email protected]
- select * from [email protected]
- select * from [email protected]
No
Database-System Mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for PostgreSQL Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Important This field is mandatory, but the value you specify is not taken into consideration. We will remove this field in a future Collibra version.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Important This field is mandatory, but the value you specify is not taken into consideration. We will remove this field in a future Collibra version.
Yes
Database Name Override We strongly recommend that you not edit the full name of your System, Database and Schema assets in Data Catalog. Doing so can lead to errors during the technical lineage creation process. If stitching is missing specifically because you edited the full name of your Database asset, you can use this field to specify the current name of your Database asset in Data Catalog.
No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required Capability
This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical lineage for Power BI Yes
Main Properties
The required custom properties are based on the selected capability template.
Source IDThe name of the data source. You can give this any name, as long as it is unique.
Warning You can only specify one source ID in this field, meaning you can only specify one source ID per
Warning If you are switching between the lineage harvester and Edge, the value in this field must exactly match the value of the
idproperty in your lineage harvester configuration file. Yes
Power BI connectionThe Power BI connection that you created for ingestion in Data Catalog.
Tip Select the name that you provided in the Name field when you created a connection to Power BI.
Yes
API URLThe API URL of your Power BI service.
The default value is
https://api.powerbi.com.Important This property is only relevant for US government or national cloud Power BI customers, in which case you must include and specify values for both this property and the
scopeproperty. For complete information, consult Microsoft's documentation on Power BI for US government customers. No
ScopeOptional property that is intended only for customers with a different scope, such as Chinese tenants.
Example https://analysis.chinacloudapi.cn/powerbi/api/.default
Important If you are a US government or national cloud Power BI customer, you must include and specify values for both this property and the
apiUrlproperty. For complete information, consult Microsoft's documentation on Power BI for US government customers. No
Domain IDThe unique reference ID of the domain in Collibra Data Intelligence Platform in which you want to ingest the Power BI assets.
How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Yes
Source configurationThis field allows you to provide JSON code for database mapping, workspace filtering and specifying the name of a System asset in Collibra.
-
Map the names of the server, database and schema that were collected by the lineage harvester to their true names.Note Mapping doesn't work for custom SQL.
-
Configure workspace filtering.Tip We highly recommend that you read through Filtering Power BI workspaces for important information and guidance before configuring your filters.
-
If
useCollibraSystemNamein the lineage harvester configuration file is set totrue, use thecollibraSystemNameproperty to specify the system name of databases in Power BI. Collibra Data Lineage uses the system names to match the structure of databases in Power BI to assets in Data Catalog.
If you previously integrated Power BI via the lineage harvester, you can copy and paste in this field the JSON code from your Power BI <source ID> configuration file.
Property
Description Mandatory?
found_dbname=<database name>;found_hostname=<server name>;found_schema=<schema name>
The database information of supported data sources in Power BI that is typically collected by the lineage harvester. Specify the name of the database (
found_dbname), on which server a database is running (found_hostname), and optionally, the name of the schema (found_schema). You then use the child properties to map the names collected by the lineage harvester to the true names.Important Schema mapping is available for schemas that come from Power Query connections. It is not available, however, if a Power Query connection is created with SQL (or MDX) statements and the schema is specified in those statements.
Important The keys that you specify must be unique.Show me an example of a duplicate key that would result in an errorThe following configuration would result in an error, becausee the keyfound_dbname=databasename1;found_hostname=*;found_schema=schema1is specified twice.{ "found_dbname=databasename1;found_hostname=*;found_schema=schema1": { "dbname": "mssql-database-name", "schema": "mssql-schema-name", "dialect": "mssql", "collibraSystemName": "mssql-system-name" }, "found_dbname=databasename1;found_hostname=*;found_schema=schema1": { "dbname": "oracle-database-name", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "oracle-system-name" }, "filters":[ { "domainId": "<domain-ref-id>", "description": "FirstFilter", "workspaceNames": ["*"], "excludeWorkspaceIds": ["workspaceC", "workspaceD"] }, { "domainId": "<domain-ref-id>", "description": "SecondFilter", "workspaceNames": ["workspace3", "workspace4"], "capacityIds": ["id1","id2"] } ] }TipYou can use wildcards to capture multiple connection string combinations:
Show me the supported wildcardsPattern Description * Matches everything. ? Matches any single character. [seq] Matches any character in "seq". [!seq] Matches any character not in "seq". Yes
dbnameThe true name (display name) of the database collected by the lineage harvester. No
schemaThe true name (display name) of the schema collected by the lineage harvester.
If the lineage harvester fails to find a specific schema, it uses the schema you specify in this property.
Important Schema mapping is available for schemas that come from Power Query connections. It is not available, however, if a Power Query connection is created with SQL (or MDX) statements and the schema is specified in those statements.
No
dialectThe dialect of the supported data source in Power BI.
Click here for a list of dialects of supported data sources in Power BI.- azure, for an Azure SQL Server data source.
- bigquery, for a Google BigQuery data source.
- mssql, for a Microsoft SQL Server data source.
- oracle, for an Oracle data source.
- redshift, for an Amazon Redshift data source.
- snowflake, for a Snowflake data source.
- sybase, for a Sybase data source.
No
collibraSystemNameThe system or server name of a database.
If you set the
useCollibraSystemNameproperty totruein your lineage harvester configuration file, but you either don't create a <source ID> configuration file, or don't specify a value for thecollibraSystemNameproperty in your <source ID> configuration file, the system name in the technical lineage is "DEFAULT".How do I configure this property if I have two databases with the same name?Let's assume you have two databases named Customers. When you prepare the physical data layer in Data Catalog, you create a System asset for each of these databases. Let's say you named them Customers-Europe and Customers-USA. You can then configure this property as follows.
"found_dbname=databasename1;found_hostname=*;found_schema=schema1": { "dbname": "Customers", "schema": "mssql-schema-name", "dialect": "mssql", "collibraSystemName": "Customers-Europe" }, "found_dbname=databasename2;found_hostname=server-name.onmicrosoft.com;found_schema=schema2": { "dbname": "Customers", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "Customers-USA" },Warning The value of this property must exactly match (including for case-sensitivity) the name of your System asset in Collibra.
Important If you are using a <source ID> configuration file for the purpose of providing the true system name of an ODBC database in Power BI, you are not required to:- Set the
useCollibraSystemNameproperty in the lineage harvester configuration file totrue. - Specify a Collibra system name in the <source ID> configuration file.
useCollibraSystemNameproperty is set totruein the lineage harvester configuration file, then you must specify a Collibra system name in the <source ID> configuration file.Yes (unless you are using the <source ID> file to provide the true system names of ODBC databases in Power BI.)
This section allows you to specify the Power BI workspaces from which you want to ingest metadata.
The filters work as "workspace AND workspace AND capacity AND capacity", meaning that if you specify a capacity, all of the workspaces in that capacity are also ingested.
Warning If you don't want to specify the Power BI workspaces from which to ingest, you must completely remove this filters section.
TipYou can use wildcards to capture multiple connection string combinations:
Show me the supported wildcardsPattern Description * Matches everything. ? Matches any single character. [seq] Matches any character in "seq". [!seq] Matches any character not in "seq". No
The unique resource ID of the domain (or domains), in Collibra Data Intelligence Platform, in which you want to ingest the Power BI assets.
Tip You can find the domain ID by clicking the domain type. Then look in the URL of your browser to find the ID. The URL looks like https://<yourcollibrainstance>/domain/<domain ID>?<view>.
Yes
descriptionAny description, as you see fit.
Yes
workspaceNamesThe names of Power BI workspaces from which you want to ingest metadata.
Important Any meta-characters in the name of a workspace must be enclosed in square brackets "[ ]". For example, a workspace with the name "Sale and Marketing [automobiles]" should be formatted as follows:
Sale and Marketing [[]automobiles[]]No
workspaceIdsThe IDs of Power BI workspaces from which you want to ingest metadata.
Tip We highly recommend that you read through Filtering Power BI workspaces for important information and guidance before configuring your filters.
No capacityNamesThe names of capacities on which you want to filter.
No capacityIdsThe IDs of capacities on which you want to filter.
Warning Any letters in a capacity ID must be in upper case.
No excludeWorkspaceNamesThe names of Power BI workspaces that you want to exclude from the ingestion job.
This is useful if you want to exclude, for example, dedicated development and testing workspaces.
Note The metadata of inactive and personal workspaces is not harvested or uploaded to the Collibra Data Lineage service instance. An inactive workspace is one for which no reports or dashboards have been viewed in the past 60 days. My workspace is the personal workspace for any Power BI customer to work with their own, personal content.
For complete details on the advantages, limitations and configuration considerations of this property, see Filtering Power BI workspaces.
No excludeWorkspaceIdsThe IDs of Power BI workspaces that you want to exclude from the ingestion job.
This is useful if you want to exclude, for example, dedicated development and testing workspaces.
For complete details on the advantages, limitations and configuration considerations of this property, see Filtering Power BI workspaces.
No ExampleShow me an example <source ID> configuration file{ "found_dbname=databasename1;found_hostname=*;found_schema=schema1": { "dbname": "mssql-database-name", "schema": "mssql-schema-name", "dialect": "mssql", "collibraSystemName": "mssql-system-name" }, "found_dbname=databasename2;found_hostname=server-name.onmicrosoft.com;found_schema=schema2": { "dbname": "oracle-database-name", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "oracle-system-name" }, "filters":[ { "domainId": "<domain-ref-id>", "description": "FirstFilter", "workspaceNames": ["*"], "excludeWorkspaceIds": ["workspaceC", "workspaceD"] }, { "domainId": "<domain-ref-id>", "description": "SecondFilter", "workspaceNames": ["workspace3", "workspace4"], "capacityIds": ["id1","id2"] } ] } NoCustom Properties
This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Advanced Properties
This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Metadata is harvested and uploaded in a ZIP file to a Collibra Data Lineage service instance, for processing.
Use this optional property to specify whether or not the raw metadata should be deleted after it has been processed.
If you select this option, the raw metadata is deleted after processing. If you don't select this option, it is stored in an Amazon S3 bucket.
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
ActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
No
Use HTTP/1.1 protocolOption to use HTTP/1.1 streams, in case file-size limitations are resulting in timeout errors when using the default HTTP/2 streams. No
Enable lineage for DAX queries
Note This feature is not available on Collibra Cloud for Government.
Option to enable DAX analysis via Collibra AI. This feature:
- Creates column-level lineage that includes your calculated columns and measures in Power BI.
- Enables stitching between calculated columns in the technical lineage and the corresponding Power BI Column assets in Data Catalog.
Select this option to enable DAX analysis.
Clear the checkbox to disable DAX analysis.
For complete information on this feature, go to DAX analysis via Collibra AI.
Logging
This section contains the properties for debug logging. This setting is not valid for this integration.
Debug
This setting is not valid for this integration. It should be set to false. NoField Description Required Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
Source ID
The name of the data source. You can give this any name, as long as it is unique.
Warning You can only specify one source ID in this field, meaning you can only specify one source ID per
Warning If you are switching between the lineage harvester and Edge, the value in this field must exactly match the value of the
idproperty in your lineage harvester configuration file.We highly recommend that you specify only one source ID per tenant.
Yes
Power BI Connection
The Power BI connection that you created for ingestion in Data Catalog.
Tip Select the name that you provided in the Name field when you created a connection to Power BI.
Yes
API URL
The API URL of your Power BI service.
The default value is
https://api.powerbi.com.Important This property is only relevant for US government or national cloud Power BI customers, in which case you must include and specify values for both this property and the
scopeproperty. For complete information, consult Microsoft's documentation on Power BI for US government customers. No
Scope
Optional property that is intended only for customers with a different scope, such as Chinese tenants.
Example https://analysis.chinacloudapi.cn/powerbi/api/.default
Important If you are a US government or national cloud Power BI customer, you must include and specify values for both this property and the
apiUrlproperty. For complete information, consult Microsoft's documentation on Power BI for US government customers. No
Domain ID
The unique reference ID of the domain in Collibra Data Intelligence Platform in which you want to ingest the Power BI assets.
How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Yes
Source Configuration
This field allows you to provide JSON code for database mapping, workspace filtering and specifying the name of a System asset in Collibra.
-
Map the names of the server, database and schema that were collected by the lineage harvester to their true names.Note Mapping doesn't work for custom SQL.
-
Configure workspace filtering.Tip We highly recommend that you read through Filtering Power BI workspaces for important information and guidance before configuring your filters.
-
If
useCollibraSystemNamein the lineage harvester configuration file is set totrue, use thecollibraSystemNameproperty to specify the system name of databases in Power BI. Collibra Data Lineage uses the system names to match the structure of databases in Power BI to assets in Data Catalog.
If you previously integrated Power BI via the lineage harvester, you can copy and paste in this field the JSON code from your Power BI <source ID> configuration file.
Property
Description Mandatory?
found_dbname=<database name>;found_hostname=<server name>;found_schema=<schema name>
The database information of supported data sources in Power BI that is typically collected by the lineage harvester. Specify the name of the database (
found_dbname), on which server a database is running (found_hostname), and optionally, the name of the schema (found_schema). You then use the child properties to map the names collected by the lineage harvester to the true names.Important Schema mapping is available for schemas that come from Power Query connections. It is not available, however, if a Power Query connection is created with SQL (or MDX) statements and the schema is specified in those statements.
Important The keys that you specify must be unique.Show me an example of a duplicate key that would result in an errorThe following configuration would result in an error, becausee the keyfound_dbname=databasename1;found_hostname=*;found_schema=schema1is specified twice.{ "found_dbname=databasename1;found_hostname=*;found_schema=schema1": { "dbname": "mssql-database-name", "schema": "mssql-schema-name", "dialect": "mssql", "collibraSystemName": "mssql-system-name" }, "found_dbname=databasename1;found_hostname=*;found_schema=schema1": { "dbname": "oracle-database-name", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "oracle-system-name" }, "filters":[ { "domainId": "<domain-ref-id>", "description": "FirstFilter", "workspaceNames": ["*"], "excludeWorkspaceIds": ["workspaceC", "workspaceD"] }, { "domainId": "<domain-ref-id>", "description": "SecondFilter", "workspaceNames": ["workspace3", "workspace4"], "capacityIds": ["id1","id2"] } ] }TipYou can use wildcards to capture multiple connection string combinations:
Show me the supported wildcardsPattern Description * Matches everything. ? Matches any single character. [seq] Matches any character in "seq". [!seq] Matches any character not in "seq". Yes
dbnameThe true name (display name) of the database collected by the lineage harvester. No
schemaThe true name (display name) of the schema collected by the lineage harvester.
If the lineage harvester fails to find a specific schema, it uses the schema you specify in this property.
Important Schema mapping is available for schemas that come from Power Query connections. It is not available, however, if a Power Query connection is created with SQL (or MDX) statements and the schema is specified in those statements.
No
dialectThe dialect of the supported data source in Power BI.
Click here for a list of dialects of supported data sources in Power BI.- azure, for an Azure SQL Server data source.
- bigquery, for a Google BigQuery data source.
- mssql, for a Microsoft SQL Server data source.
- oracle, for an Oracle data source.
- redshift, for an Amazon Redshift data source.
- snowflake, for a Snowflake data source.
- sybase, for a Sybase data source.
No
collibraSystemNameThe system or server name of a database.
If you set the
useCollibraSystemNameproperty totruein your lineage harvester configuration file, but you either don't create a <source ID> configuration file, or don't specify a value for thecollibraSystemNameproperty in your <source ID> configuration file, the system name in the technical lineage is "DEFAULT".How do I configure this property if I have two databases with the same name?Let's assume you have two databases named Customers. When you prepare the physical data layer in Data Catalog, you create a System asset for each of these databases. Let's say you named them Customers-Europe and Customers-USA. You can then configure this property as follows.
"found_dbname=databasename1;found_hostname=*;found_schema=schema1": { "dbname": "Customers", "schema": "mssql-schema-name", "dialect": "mssql", "collibraSystemName": "Customers-Europe" }, "found_dbname=databasename2;found_hostname=server-name.onmicrosoft.com;found_schema=schema2": { "dbname": "Customers", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "Customers-USA" },Warning The value of this property must exactly match (including for case-sensitivity) the name of your System asset in Collibra.
Important If you are using a <source ID> configuration file for the purpose of providing the true system name of an ODBC database in Power BI, you are not required to:- Set the
useCollibraSystemNameproperty in the lineage harvester configuration file totrue. - Specify a Collibra system name in the <source ID> configuration file.
useCollibraSystemNameproperty is set totruein the lineage harvester configuration file, then you must specify a Collibra system name in the <source ID> configuration file.Yes (unless you are using the <source ID> file to provide the true system names of ODBC databases in Power BI.)
This section allows you to specify the Power BI workspaces from which you want to ingest metadata.
The filters work as "workspace AND workspace AND capacity AND capacity", meaning that if you specify a capacity, all of the workspaces in that capacity are also ingested.
Warning If you don't want to specify the Power BI workspaces from which to ingest, you must completely remove this filters section.
TipYou can use wildcards to capture multiple connection string combinations:
Show me the supported wildcardsPattern Description * Matches everything. ? Matches any single character. [seq] Matches any character in "seq". [!seq] Matches any character not in "seq". No
The unique resource ID of the domain (or domains), in Collibra Data Intelligence Platform, in which you want to ingest the Power BI assets.
Tip You can find the domain ID by clicking the domain type. Then look in the URL of your browser to find the ID. The URL looks like https://<yourcollibrainstance>/domain/<domain ID>?<view>.
Yes
descriptionAny description, as you see fit.
Yes
workspaceNamesThe names of Power BI workspaces from which you want to ingest metadata.
Important Any meta-characters in the name of a workspace must be enclosed in square brackets "[ ]". For example, a workspace with the name "Sale and Marketing [automobiles]" should be formatted as follows:
Sale and Marketing [[]automobiles[]]No
workspaceIdsThe IDs of Power BI workspaces from which you want to ingest metadata.
Tip We highly recommend that you read through Filtering Power BI workspaces for important information and guidance before configuring your filters.
No capacityNamesThe names of capacities on which you want to filter.
No capacityIdsThe IDs of capacities on which you want to filter.
Warning Any letters in a capacity ID must be in upper case.
No excludeWorkspaceNamesThe names of Power BI workspaces that you want to exclude from the ingestion job.
This is useful if you want to exclude, for example, dedicated development and testing workspaces.
Note The metadata of inactive and personal workspaces is not harvested or uploaded to the Collibra Data Lineage service instance. An inactive workspace is one for which no reports or dashboards have been viewed in the past 60 days. My workspace is the personal workspace for any Power BI customer to work with their own, personal content.
For complete details on the advantages, limitations and configuration considerations of this property, see Filtering Power BI workspaces.
No excludeWorkspaceIdsThe IDs of Power BI workspaces that you want to exclude from the ingestion job.
This is useful if you want to exclude, for example, dedicated development and testing workspaces.
For complete details on the advantages, limitations and configuration considerations of this property, see Filtering Power BI workspaces.
No ExampleShow me an example <source ID> configuration file{ "found_dbname=databasename1;found_hostname=*;found_schema=schema1": { "dbname": "mssql-database-name", "schema": "mssql-schema-name", "dialect": "mssql", "collibraSystemName": "mssql-system-name" }, "found_dbname=databasename2;found_hostname=server-name.onmicrosoft.com;found_schema=schema2": { "dbname": "oracle-database-name", "schema": "oracle-schema-name", "dialect": "oracle", "collibraSystemName": "oracle-system-name" }, "filters":[ { "domainId": "<domain-ref-id>", "description": "FirstFilter", "workspaceNames": ["*"], "excludeWorkspaceIds": ["workspaceC", "workspaceD"] }, { "domainId": "<domain-ref-id>", "description": "SecondFilter", "workspaceNames": ["workspace3", "workspace4"], "capacityIds": ["id1","id2"] } ] } NoProperty This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Metadata is harvested and uploaded in a ZIP file to a Collibra Data Lineage service instance, for processing.
Use this optional property to specify whether or not the raw metadata should be deleted after it has been processed.
If you select this option, the raw metadata is deleted after processing. If you don't select this option, it is stored in an Amazon S3 bucket.
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
No
Use HTTP/1.1 protocol
Option to use HTTP/1.1 streams, in case file-size limitations are resulting in timeout errors when using the default HTTP/2 streams. No
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Enable lineage for DAX queries
Note This feature is not available on Collibra Cloud for Government.
Option to enable DAX analysis via Collibra AI. This feature:
- Creates column-level lineage that includes your calculated columns and measures in Power BI.
- Enables stitching between calculated columns in the technical lineage and the corresponding Power BI Column assets in Data Catalog.
Select this option to enable DAX analysis.
Clear the checkbox to disable DAX analysis.
For complete information on this feature, go to DAX analysis via Collibra AI.
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SAP HANA Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Note If you are migrating an SAP HANA data source from the lineage harvester, ensure that you run theignore-sourcecommand with the source ID from the lineage harvester configuration file. When you synchronize this capability, an error occurs if the source ID from the lineage harvester exists even if you use the same source ID for this field. For more information, go to Migrate the technical lineage of a data source. Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns
This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Calculated Views
This query retrieves calculated views.
Dependencies of Calculated Views
This query retrieves dependencies of calculated views.
Cross-references of Calculated Views
Cross-references of Calculated Views Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
SQL Active
An option to determine whether to include or remove the technical lineage of the data source with the SQL based input.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
If you have a capability with this option selected and the synchronization of the capability fails with the
Missing required parameter hanaUseCloudScannererror message, go to In Edge Harvester, previously configured/working SAP HANA Classic capabilities fail to submit to Edge in Collibra Support Portal for a solution. No
Calculated Views Active
An option to determine whether to include or remove the technical lineage from calculated views in an SAP HANA Classic on-premises data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
If you have a capability with this option selected and the synchronization of the capability fails with the
Missing required parameter hanaUseCloudScannererror message, go to In Edge Harvester, previously configured/working SAP HANA Classic capabilities fail to submit to Edge in Collibra Support Portal for a solution. No
Use Hana Cloud
An option to determine whether to include or remove the technical lineage from calculated views in an SAP HANA Cloud/Advanced data source.
To include technical lineage from the SAP HANA Cloud/Advanced data source, you must select this option and the Calculated Views Active option.
Clear the checkbox to exclude the technical lineage of this data source.
No
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Note If you are migrating an SAP HANA data source from the lineage harvester, ensure that you run theignore-sourcecommand with the source ID from the lineage harvester configuration file. When you synchronize this capability, an error occurs if the source ID from the lineage harvester exists even if you use the same source ID for this field. For more information, go to Migrate the technical lineage of a data source. Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns
This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Calculated Views
This query retrieves calculated views.
Dependencies of Calculated Views
This query retrieves dependencies of calculated views.
Cross-references of Calculated Views
Cross-references of Calculated Views Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
SQL Active
An option to determine whether to include or remove the technical lineage of the data source with the SQL based input.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
If you have a capability with this option selected and the synchronization of the capability fails with the
Missing required parameter hanaUseCloudScannererror message, go to In Edge Harvester, previously configured/working SAP HANA Classic capabilities fail to submit to Edge in Collibra Support Portal for a solution. No
Calculated Views Active
An option to determine whether to include or remove the technical lineage from calculated views in an SAP HANA Classic on-premises data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
If you have a capability with this option selected and the synchronization of the capability fails with the
Missing required parameter hanaUseCloudScannererror message, go to In Edge Harvester, previously configured/working SAP HANA Classic capabilities fail to submit to Edge in Collibra Support Portal for a solution. No
Use Hana Cloud
An option to determine whether to include or remove the technical lineage from calculated views in an SAP HANA Cloud/Advanced data source.
To include technical lineage from the SAP HANA Cloud/Advanced data source, you must select this option and the Calculated Views Active option.
Clear the checkbox to exclude the technical lineage of this data source.
No
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Snowflake Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Ingestion MethodThe Snowflake ingestion methods that Collibra Data Lineage uses to ingest metadata from Snowflake data sources. Select one of the following values:
- SQL
- The SQL Snowflake ingestion mode. Collibra Data Lineage creates a column-level technical lineage based on SQL statements.
- SQL-API
- The SQL-API Snowflake ingestion mode. Collibra Data Lineage creates a column-level technical lineage based on Snowflake schemas and the access history.
For more information, go to Technical lineage for Snowflake ingestion methods.
Yes
Days
The number of days of the user access history that Collibra Data Lineage collects and processes. For example, if you set the value to 20, Collibra Data Lineage collects the last 20 days of user access history.
You can use this
Specify a value in the range of 1 - 366. If you do not enter a value, all user access history is collected by default.
Note A higher value of this413 Payload Too Largeerror when Collibra Data Lineage analyzes the metadata to create the technical lineage. No
Extra Database Definitions
Tip You can add extra database definitions by clicking Add property. No
Schema Names
The schema name of your data source. This field takes effect only when you use the SQL-API Snowflake ingestion mode. You can use this field as a filter to include lineage for objects only in the specified schema.
Ensure that the schema name you specify matches the Schema asset name that you created when you registered the data source in Data Catalog.
Tip You can add extra schema names by clicking Add property. No
Source Configuration
The source configuration for the data source. Specify the following property in JSON format and enter the content in this field. This field applies only when you select the SQL-API Snowflake ingestion mode.
Property
Description Required?
displaySampleQueries Indicates whether to display transformations with a question mark (?) or with actual values from queries in the Source code pane in the technical lineage graph. For example, you can choose to display
WHERE amount < 100orWHERE amount < ?.Specify one of the following values:
true- Actual values from queries are displayed.
false- A question mark (?) is displayed. This is the default value.
No analyzeTemporaryTables Indicates whether to parse the CREATE TEMPORARY TABLE statement in the ingested queries. Specify one of the following values:
true- Collibra Data Lineage examines the queries and parses the CREATE TEMPORARY TABLE statement when the following conditions are met:
The query starts with the CREATE TEMPORARY TABLE statement.
Collibra Data Lineage did not encounter the CREATE TEMPORARY TABLE statement before this query.
false- Collibra Data Lineage does not examine or parse the CREATE TEMPORARY TABLE statement in the ingested queries. This is the default value.
No Example{ "displaySampleQueries": true|false "analyzeTemporaryTables": true|false } No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
If you select the SQL Snowflake ingestion mode, the following queries apply:
Query Description Columns This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Views
This query retrieves the view definitions.
If you select the SQL-API Snowflake ingestion mode, the following queries apply:
Query Description Object Dependencies
This query retrieves view definitions.
Columns Joined
This query retrieves table and column definition information.
If you have missing upstream lineage information, while creating technical lineage for Snowflake with the SQL-API ingestion mode, you can use this query as a workaround to fix the issue. For more information, go to the following article in the Collibra Support Portal: Snowflake SQL-API lineage missing due to frequent table replacement.
Access History
This query retrieves lineage and transformation details.
Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Ingestion Method
The Snowflake ingestion methods that Collibra Data Lineage uses to ingest metadata from Snowflake data sources. Select one of the following values:
- SQL
- The SQL Snowflake ingestion mode. Collibra Data Lineage creates a column-level technical lineage based on SQL statements.
- SQL-API
- The SQL-API Snowflake ingestion mode. Collibra Data Lineage creates a column-level technical lineage based on Snowflake schemas and the access history.
For more information, go to Technical lineage for Snowflake ingestion methods.
Yes
Days
The number of days of the user access history that Collibra Data Lineage collects and processes. For example, if you set the value to 20, Collibra Data Lineage collects the last 20 days of user access history.
You can use this
Specify a value in the range of 1 - 366. If you do not enter a value, all user access history is collected by default.
Note A higher value of this413 Payload Too Largeerror when Collibra Data Lineage analyzes the metadata to create the technical lineage. No
Extra Database Definitions
Tip You can add extra database definitions by clicking Add property. No
Schema Names
The schema name of your data source. This field takes effect only when you use the SQL-API Snowflake ingestion mode. You can use this field as a filter to include lineage for objects only in the specified schema.
Ensure that the schema name you specify matches the Schema asset name that you created when you registered the data source in Data Catalog.
Tip You can add extra schema names by clicking Add property. No
Source Configuration
The source configuration for the data source. Specify the following property in JSON format and enter the content in this field. This field applies only when you select the SQL-API Snowflake ingestion mode.
Property
Description Required?
displaySampleQueries Indicates whether to display transformations with a question mark (?) or with actual values from queries in the Source code pane in the technical lineage graph. For example, you can choose to display
WHERE amount < 100orWHERE amount < ?.Specify one of the following values:
true- Actual values from queries are displayed.
false- A question mark (?) is displayed. This is the default value.
No analyzeTemporaryTables Indicates whether to parse the CREATE TEMPORARY TABLE statement in the ingested queries. Specify one of the following values:
true- Collibra Data Lineage examines the queries and parses the CREATE TEMPORARY TABLE statement when the following conditions are met:
The query starts with the CREATE TEMPORARY TABLE statement.
Collibra Data Lineage did not encounter the CREATE TEMPORARY TABLE statement before this query.
false- Collibra Data Lineage does not examine or parse the CREATE TEMPORARY TABLE statement in the ingested queries. This is the default value.
No Example{ "displaySampleQueries": true|false "analyzeTemporaryTables": true|false } No
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
If you select the SQL Snowflake ingestion mode, the following queries apply:
Query Description Columns This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Views
This query retrieves the view definitions.
If you select the SQL-API Snowflake ingestion mode, the following queries apply:
Query Description Object Dependencies
This query retrieves view definitions.
Columns Joined
This query retrieves table and column definition information.
If you have missing upstream lineage information, while creating technical lineage for Snowflake with the SQL-API ingestion mode, you can use this query as a workaround to fix the issue. For more information, go to the following article in the Collibra Support Portal: Snowflake SQL-API lineage missing due to frequent table replacement.
Access History
This query retrieves lineage and transformation details.
Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Spark SQLName
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Select the Technical lineage capability template for your data source to create a technical lineage for the JDBC data source.
Important Technical lineage via Edge is only available in private beta. Please create a support ticket to get access.
Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
External Database Name
The database value to be used as the database name in the full path (system -> database -> schema -> table). Use this field to ensure successful stitching for a database-less data source. You can specify one of the following values:
CData, which CDATA drivers returned as a placeholder. Use this value if you did not create a custom database name by using theCustomizedDefaultCatalogNameproperty when you registered your data source.- The custom database name that you specified for the
CustomizedDefaultCatalogNameproperty when you registered your data source.
See an exampleWhen you registered a Spark SQL data source on Edge and did not specify the
CustomizedDefaultCatalogNameproperty, the following full path to a column in Data Catalog is created and CData is used as the database name:SparkSQL_123(system) >CData(database) >SparkSQL_ABC(schema) >Table>ColumnWhen Collibra Data Lineage collects metadata from the Spark SQL data source, the value of the Database Name field is used as the schema name because Spark SQL is database-less.
If you do not enter a value for the External Database Name field, the value of the Collibra System Name field is used as the database name. If you set the Collibra system name setting to
true, the value of the Collibra System Name field is also used as the system name. In this case, the full path is shown as follows and does not match the full path in Data Catalog:SparkSQL_123(system) >SparkSQL_123(database) >SparkSQL_ABC(schema) >Table>ColumnIn this case, the stitching is missing because of the mismatch of the full paths. To match the full path and preserve stitching, you must specify
CDatafor the External Database Name field. No
Database Name
The name of the database or schema (these terms are synonymous for Spark SQL) from which you want to harvest metadata.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Object names This query retrieves a list of object names from which technical lineage can be created. The objects can include stored procedures, views, macros, and so on. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
External Database Name
The database value to be used as the database name in the full path (system -> database -> schema -> table). Use this field to ensure successful stitching for a database-less data source. You can specify one of the following values:
CData, which CDATA drivers returned as a placeholder. Use this value if you did not create a custom database name by using theCustomizedDefaultCatalogNameproperty when you registered your data source.- The custom database name that you specified for the
CustomizedDefaultCatalogNameproperty when you registered your data source.
See an exampleWhen you registered a Spark SQL data source on Edge and did not specify the
CustomizedDefaultCatalogNameproperty, the following full path to a column in Data Catalog is created and CData is used as the database name:SparkSQL_123(system) >CData(database) >SparkSQL_ABC(schema) >Table>ColumnWhen Collibra Data Lineage collects metadata from the Spark SQL data source, the value of the Database Name field is used as the schema name because Spark SQL is database-less.
If you do not enter a value for the External Database Name field, the value of the Collibra System Name field is used as the database name. If you set the Collibra system name setting to
true, the value of the Collibra System Name field is also used as the system name. In this case, the full path is shown as follows and does not match the full path in Data Catalog:SparkSQL_123(system) >SparkSQL_123(database) >SparkSQL_ABC(schema) >Table>ColumnIn this case, the stitching is missing because of the mismatch of the full paths. To match the full path and preserve stitching, you must specify
CDatafor the External Database Name field. No
Database Name
The name of the database or schema (these terms are synonymous for Spark SQL) from which you want to harvest metadata.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Object names This query retrieves a list of object names from which technical lineage can be created. The objects can include stored procedures, views, macros, and so on. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SQL Server Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns
This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column.
Database Links This query retrieves links to other databases.
Synonyms This query retrieves the alternative names for the database objects. Views This query retrieves the view definitions. Other Queries This query retrieves other data that technical lineage needs, for example stored procedures, functions, and packages. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns
This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column.
Database Links This query retrieves links to other databases.
Synonyms This query retrieves the alternative names for the database objects. Views This query retrieves the view definitions. Other Queries This query retrieves other data that technical lineage needs, for example stored procedures, functions, and packages. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
Yes
Mask The pattern of the file names in the directory. By default, the value is
*. No
Source Configuration
The connection definitions, where you specify relevant translations for each data source. Specify the following properties in JSON format and enter the content in this field.
If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the <source ID>.conf file in this field.Connection definition propertiesProperty
Description Required? DataSources
The parent element that contains the connection definitions of your data sources in SQL Server Integration Services.
If you specify the properties in this section and also the ConnStringRegExTranslation property for a data source, the connection definitions in the ConnStringRegExTranslation property takes precedence.
No
DataSourceNameThe name of your data source.
No
dialectThe dialect of the referenced database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
No
collibraSystemNameThe system or server name of the data source.
Use this property with the
useCollibraSystemNameproperty in the lineage harvester configuration file to override the default Collibra System asset name for this data source.Specify this property with the same name as the name of the System asset that you create when you prepare the physical data layer in Data Catalog. If you don't prepare the physical data layer, Collibra Data Lineage cannot stitch the data objects in your technical lineage to the assets in Data Catalog.
No
ConnStringRegExTranslation
The parent element that opens the connection definitions.
If you specify this property and also the properties in the DataSources section for a data source, the connection definitions in this property takes precedence.
No
<regular expression>
A regular expression that must match one or more connection strings.
NoteImportant considerations:
- By default, the regular expression is not case sensitive. As a consequence, a regular expression can match with connection strings containing uppercase characters or lowercase characters.
- The connection string is part of the SSIS connection manager.
- SSIS connection managers are included in an SSIS package files (DTSX) or in connection manager files (CONMGR).
ExampleRegular expression:
Server=sb-dhub;User ID=SYB_USER2;Initial Catalog=STAGEDB;Port=6306.*
Explanation: The first section, up to .*, is a literal, but not case-sensitive, match of the characters. The dot (.) can match any single character. The asterisk (*) means zero or more of the previous, in this case any character.
Match: Any connection string that starts withServer=sb-dhub;User ID=SYB_USER2;Initial Catalog=STAGEDB;Port=6306.
Example:Server=sb-dhub;User ID=SYB_USER2;Initial Catalog=STAGEDB;Port=6306;Persist Security Info=True;Auto Translate=False;. No
dbnameThe name of your database, to which the data source connection refers. No
schemaThe name of your schema, to which the regular expression refers.
No
dialectThe dialect of the referenced database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
No
collibraSystemNameThe system or server name of the data source.
Specify this property when you set the value of the Collibra system name setting to
True to override the default Collibra System asset name for this data source. Specify this property with the same name as the name of the System asset that you created when you registered the data source.
No
See an example{ "DataSources": { "dhb-sql-prod": { "dialect": "mssql", "collibraSystemName": "my-system-name" } }, "ConnStringRegExTranslation": { "Data Source=dhb-sql-prod;Initial Catalog=SFG_repl_staging;Provider=SQLNCLI11;Integrated Security=SSPI.*": { "dbname": "DATAHUB", "schema": "DBO", "dialect": "mssql", "collibraSystemName" : "WAREHOUSE" }, "Server=sb-dhub;User ID=SYS_USER;Initial Catalog=STAGEDB;Port=6306.*": { "dbname": "STAGEDB", "schema": "STAGE_OWNER", "dialect": "sybase", "collibraSystemName" : "" } } } No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
NameThe name of the Edge capability.
Yes
DescriptionThe description of the Edge capability.
Yes
Capability templateThe capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SQL Server Integration Services (SSIS) Yes
Main Properties This section contains the information for creating a technical lineage.
Source IDThe name of the data source. Specify a name that is unique.
Yes
Shared Storage ConnectionThe Shared Storage connection that you created.
Yes
MaskThe pattern of the file names in the directory. By default, the value is
*. No
Source ConfigurationThe connection definitions, where you specify relevant translations for each data source. Specify the following properties in JSON format and enter the content in this field.
If you previously created a technical lineage for this data source with connection definitions by using the lineage harvester, you can enter the content from the <source ID>.conf file in this field.Connection definition propertiesProperty
Description ConnStringRegExTranslation
The parent element that opens the connection definitions.
<regular expression>
A regular expression that must match one or more connection strings.
NoteImportant considerations:
- By default, the regular expression is not case sensitive. As a consequence, a regular expression can match with connection strings containing uppercase characters or lowercase characters.
- The connection string is part of the SSIS connection manager.
- SSIS connection managers are included in an SSIS package files (DTSX) or in connection manager files (CONMGR).
ExampleRegular expression:
Server=sb-dhub;User ID=SYB_USER2;Initial Catalog=STAGEDB;Port=6306.*
Explanation: The first section, up to .*, is a literal, but not case-sensitive, match of the characters. The dot (.) can match any single character. The asterisk (*) means zero or more of the previous, in this case any character.
Match: Any connection string that starts withServer=sb-dhub;User ID=SYB_USER2;Initial Catalog=STAGEDB;Port=6306.
Example:Server=sb-dhub;User ID=SYB_USER2;Initial Catalog=STAGEDB;Port=6306;Persist Security Info=True;Auto Translate=False;.dbnameThe name of your database, to which the data source connection refers. schemaThe name of your schema, to which the regular expression refers.
dialectThe dialect of the referenced database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
collibraSystemNameThe system or server name of the data source.
Specify this property when you set the value of the Collibra system name setting to
True to override the default Collibra System asset name for this data source. Specify this property with the same name as the name of the System asset that you created when you registered the data source.
This property is optional.
See an example{ "DataSources": { "dhb-sql-prod": { "dialect": "mssql", "collibraSystemName": "my-system-name" } }, "ConnStringRegExTranslation": { "Data Source=dhb-sql-prod;Initial Catalog=SFG_repl_staging;Provider=SQLNCLI11;Integrated Security=SSPI.*": { "dbname": "DATAHUB", "schema": "DBO", "dialect": "mssql", "collibraSystemName" : "WAREHOUSE" }, "Server=sb-dhub;User ID=SYS_USER;Initial Catalog=STAGEDB;Port=6306.*": { "dbname": "STAGEDB", "schema": "STAGE_OWNER", "dialect": "sybase", "collibraSystemName" : "" } } } No
PropertyThis section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On SourcesThis option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After ProcessingTechnical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze OnlyThis option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
ActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging
This section contains the properties for debug logging. This setting is not valid for this integration.
NoDebug
This setting is not valid for this integration. It should be set to false. NoField Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Sybase Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database Name
The name of your database, which is also the name of your Database asset in Data Catalog.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves all columns, tables, schemas, databases or projects in the form: database or project > schema > table > column. Views This query retrieves the view definitions. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required Capability
This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
NoCapability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical lineage for Tableau Yes
Main Properties
The required information for creating a technical lineage.
Source IDThe name of the data source. You can give this any name, as long as it is unique.
Warning You can only specify one source ID in this field, meaning you can only specify one source ID per
Warning If you are switching between the lineage harvester and Edge, the value in this field must exactly match the value of the
idproperty in your lineage harvester configuration file. Yes
Tableau connectionThe Tableau connection that you created for ingestion in Data Catalog.
Tip Select the name that you provided in the Name field when you created a connection to Tableau.
Yes
Domain IDThe unique reference ID of the domain in Collibra Data Intelligence Platform in which you want to ingest the Tableau assets.
How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Yes
REST onlyIndication whether or not you want to use both the Tableau REST API and Tableau Metadata API to harvest Tableau metadata.
- Cleared (default): The lineage harvester will use the REST API and Metadata API to harvest Tableau metadata.
- Selected: The lineage harvester will only use the REST API to harvest Tableau metadata.
Note This filed must be cleared, to:- Enable technical lineage and the automatic stitching of Column assets to Tableau Data Attribute assets.
- Harvest owner information for Tableau projects, workbooks and data models.
NoExclude imagesIndication whether or not you want to excluding the downloading of images.
- Cleared: Images are downloaded.
- Selected (default): Images are not downloaded.
Note The maximum number of images that can be uploaded to Collibra per day is determined by the configuration of the file upload service, in Collibra Console. For complete details, see the Upload configuration settings in DGC service configuration: options.
NoSite IDThe site IDs of the Tableau sites that you want to include in the ingestion process.
To ingest from multiple Tableau sites, enter each site ID in a separate Site ID field.
To ingest the default Tableau site, enter "Default" or leave the field empty. This field is not case sensitive.
Warning If you enter "Default", you must include the double quotation marks. The site IDs of any other Tableau sites must not be enclosed in double quotation marks. If the formatting of the site IDs does not conform to this detail, ingestion will fail.ExampleSee an exampleLet's say that you want to ingest from the default Tableau site and a site named "ABC".
- In the Site ID field, enter "Default" for the default Tableau site.
- Click Add property.
An empty Site ID field is aded. - In the new Site ID field, enter the ID of the Tableau site ABC.
 Tip Ensure that you specify the correct value. The correct value is the URL of the site to which you want to sign in. When you manually sign in to Tableau Server or Tableau Online, the site ID is the value that appears after /site/ in the browser address bar. In the following example URLs, the site ID is
Tip Ensure that you specify the correct value. The correct value is the URL of the site to which you want to sign in. When you manually sign in to Tableau Server or Tableau Online, the site ID is the value that appears after /site/ in the browser address bar. In the following example URLs, the site ID isMarketingTeam:- Tableau Server: http://MyServer/#/site/MarketingTeam/projects
- Tableau Online: https://10ay.online.tableau.com/#/site/MarketingTeam/workbooks
On Tableau Server, however, the URL of the default site does not specify the site. For example, the URL for a view named Profits, on a site named Sales, is http://localhost/#/site/sales/views/profits. The URL for this same view on the default site is http://localhost/#/views/profits. The site name Sales does not figure in the URL. Yes
Site NameThe site name, or names, of the Tableau sites you specified in the Site ID field.
If you don't provide a site ID in the Site ID field, in which case the default Tableau site is ingested, leave this field blank.
NoConcurrency levelThis field is intended to help if you are experiencing HTTP 401 Unauthorized errors due to too many concurrent HTTP calls, using the same token. It allows you to specify the internal sizing, meaning the amount of tasks that can be executed at the same time.
The default value is
10, meaning as many as 10 HTTP requests can take place in parallel. Consider reducing the value if you are experiencing HTTP 401 Unauthorized errors. Setting the value to1effectively disables the concurrency level, so that HTTP requests will be run in a synchronous manner, instead of in parallel. NoSource configurationThis field allows you to provide JSON code for database mapping, domain mapping and filtering.
If you previously integrated Tableau via the lineage harvester, you can copy and paste in this field the JSON code from your Tableau <source ID> configuration file.
Property
Description collibraSystemNames This section contains the system information for different Tableau data sources. Depending on the kind of data source or connection, you have to specify how to connect to this data source.
Tip For more information, see the Tableau documentation. We also recommend to check the list of supported connectors in Tableau.
filesThis section contains connection information to one or more files in Tableau.
Tip If you do not have files in Tableau, you can remove this section.
filePathThe full path to the file. For example, the path to a JSON file. collibraSystemNameThe system name of the file. connectorsThis section contains connection information to one or more connectors in Tableau.
Tip- If you do not have connectors in Tableau, you can remove this section.
- The values that you specify for this property are not case-sensitive.
connectorUrlThe URL of the connector. For example, the URL to Google Analytics. collibraSystemNameThe system name of the connector. cloudFilesThis section contains connection information to one or more cloud files in Tableau's input data.
Tip If you do not have cloud files in Tableau, you can remove this section.
nameThe name of the file. For example, the name of a Zendesk file. collibraSystemNameThe system name of the cloud file. This section allows you to map Tableau technical database, server and schema names to the respective real names, to preserve stitching.
WarninghostnameMappingreplaces the following deprecated properties- The
databaseMappingproperty. - The
databasessub-section of thecollibraSystemNamessection.
- The
hostnameMappingmust not be used in combination with either of these properties.If you use the
hostnameMappingsection, you can still use thecollibraSystemNameproperty in conjunction with thefiles,connectorsorcloudfilessub-sections.Example configuration"hostnameMapping": { "found_dbname=databasename1;found_hostname=*;found_schema=test": { "dbname": "mssql-database-name", "schema": "mssql-schema-name", "dialect": "mssql", "collibraSystemName": "mssql-system-name" } }For more example configurations, go to Tableau hostname, schema, and system name mapping.
found_dbname=<database name>;found_hostname=<server name>;found_schema=<schema name>The database information of supported data sources in Tableau that is typically collected by the lineage harvester. It allows you to specify the name of the database (found_dbname), on which server a database is running (found_hostname), and optionally, the name of the schema (found_schema).
dbnameThe name of the database of a supported data source in Tableau.
schemaThe name of the default schema of a supported data source in Tableau.
If the lineage harvester fails to find a specific schema, it uses the default schema.
dialectThe dialect of the supported data source in Tableau.
You don't have to specify a dialect; it will automatically be detected. If, however, you are using a dialect that is not supported, you can use this property to specify a supported dialect that is a close comparison. That way, most of your queries will be detected and processed.
Show me a list of dialects of supported data sources in Tableau.- redshift, for an Amazon Redshift data source.
- azure, for an Azure SQL Server data source.
- bigquery, for a Google BigQuery data source.
- greenplum, for a Greenplum data source.
- hive, for a HiveQL data source.
- oracle, for an Oracle data source.
- postgres, for a PostgreSQL data source.
- mssql, for a Microsoft SQL Server data source.
- mysql, for a MySQL data source.
- netezza, for a Netezza data source.
- hana, for a SAP HANA data source.
- spark, for a Spark SQL data source.
- sybase, for a Sybase data source.
- teradata, for a Teradata data source.
This section defines:
- From which Tableau sites and projects you want to harvest metadata.
- Into which domains in Collibra you want to ingest the corresponding assets.
Filtering is transitive, which means that all resources in a specified project, such as Tableau workbooks and all sub-projects, are ingested.
Tableau assets that are not mapped to the specified domains, for example the Tableau Server assets and the parent projects (if you specify their sub-projects), are ingested in the default domain.
Important- Filtering does not affect the amount of raw metadata that is harvested from Tableau and sent to the Collibra Data Lineage service instance. Rather, it determines which metadata is ingested as assets in Data Catalog.
- The
domainMappingandfilterssections are mutually exclusive. Do not include bothdomainMappingandfilterssections in your JSON file.
Tip- If you want to ingest all of the projects in a Tableau site into multiple domains in Collibra, use
domainMappingsection. - If you want to ingest all of the projects in a Tableau site into the default domain, use only the
domainIDproperty in the lineage harvester configuration file. ThedomainIDproperty represents the default domain. - If you want to ingest all of the projects in a Tableau site into a single domain in Collibra, use site filtering.
- If you want to ingest metadata from only some of the projects in a Tableau site, use project filtering.
- You can use site filtering and project filtering together:
- If filtering on the same site, this "filtering" is actually domain mapping, because nothing is filtered out. The contents of the projects are ingested in the specified domains, and the rest of the contents of the site are ingested in a different, specified domain.
- If you are site filtering on a specific site and project filtering a different site, then site filtering is again a form of domain mapping, and the filtered projects are ingested in their specified domains.
- If your lineage harvester configuration file includes sites that are not mentioned in the
filterssection of your <source ID> configuration file, those sites are ingested in the default domain.
The Tableau sites to be ingested and the domain in which you want to ingest metadata from the Tableau sites.
Tip If you have only one Tableau site, do not include asitessection in your <source ID> file. Instead, use aprojectssection, to filter on Tableau projects. Include asitessection only if all of the following are true:- You have more than one Tableau site.
- You want to ingest all of the metadata from only one Tableau site into a single domain in Collibra.
- The domain into which you want to ingest is not the default domain, meaning the domain specified in the
domainIdproperty in your lineage harvester configuration file.
site_name: domain_idsite_name- The name of the site to be ingested. The site name is case-sensitive.
domain_id- The unique reference ID of the domain in Collibra in which you want to ingest metadata. The domain ID is case-sensitive.
siteIdsproperty in the lineage harvester configuration file for Tableau. If thesite_nameordomain_idproperty is not specified for a site, the metadata from the site is ingested in the default domain.How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Show me the example{ "filters":{ "sites":{ "Training":"ca60b822-781b-4b3a-b44d-f65bd107ff92" }, "projects":{ "Testing > Databricks":"e8f4e4a8-4062-4a33-9b44-3ce3e18e4e22", "Product Demo > Customer Insights":"a305e6f7-7a49-49aa-aa85-41b1e689121b" } } }The Tableau projects to be ingested and the domain in which you want to ingest metadata from the Tableau projects or sub-projects.
Tip Project filtering is not relevant for those who have an Explorer role in Tableau, because Explorers need to configure permissions for each data object in Tableau that they want to ingest. As the Administrator role has access to all data objects, project filtering allows Administrators to specify which projects to ingest.
site_name > project_name : domain_idThe
site_nameshould be the Tableau site name. Theproject_nameshould be the Tableau project name.The
domain_idshould be the unique reference ID of the domain in Collibra in which you want to ingest metadata.When you specify the site and project names, the following rules apply:
- Add spaces before and after >. The spaces are separators between the site and project.
- Specify the full exact site and project names.
- The values are case-sensitive.
When you specify a Tableau project, all assets in the project are ingested in the specified domain. If you want to ingest assets from different Tableau projects in one domain, you can specify the same value for
domain idfor different projects.Example
"Collibra_tab_partner_site > JB_Test_2812": "d224a1a5-43b4-43b2-8df0-ddf8f2726b82"site_name > project_name > sub-project_name : domain_idThe
site_nameshould be the Tableau site name. Theproject_nameshould be the Tableau project name. Optionally, usesub-project_nameto specify the Tableau sub-project name.The
domain_idproperty should be the unique reference ID of the domain in Collibra in which you want to ingest metadata.When you specify the site, project and sub-project names, the following rules apply:
- Add spaces before and after >. The spaces are separators between the site and project.
- Specify the full exact site and project names.
- The values are case-sensitive.
Example
"Collibra_tab_partner_site > JB_Test_2812 > ProjectJJ2": "d224a1a5-43b4-43b2-8df0-ddf8f2726b82"domainMapping This section defines in which domains in Collibra you want to ingest assets from your Tableau sites and Tableau projects.
Domain mapping is transitive, meaning that all resources, such as Tableau workbooks and data attributes in a parent Tableau site, project or sub-project, are ingested in the same domain as the parent.
Important The
domainMappingandfilterssections are mutually exclusive. Do not include bothdomainMappingandfilterssections in your JSON file.Tip- If you want to ingest all of the projects in a Tableau site into multiple domains in Collibra, use
domainMappingsection. - If you want to ingest all of the projects in a Tableau site into the default domain, use only the
domainIDproperty in the lineage harvester configuration file. ThedomainIDproperty represents the default domain.Note Tableau assets that are not mapped to specific domains via thisdomainMappingsection, for example Tableau Server assets, are ingested in that default domain. - If you want to ingest all of the projects in a Tableau site into a single domain in Collibra, use site filtering.
- If you want to ingest metadata from only some of the projects in a Tableau site, use project filtering.
Show me an exampleLet's say that you have a Tableau site named "Site-1". You want to ingest all Tableau projects in "Site-1" in a domain named "Domain-1" in Collibra, with the exception of one Tableau project named "Project-Default", which you want to ingest in "Domain-2". You should configure the
domainMappingsection as follows."domainMapping": { "<Site-1>": "reference-id-of-Domain-1", "<Site-1> > <Project-Default>": "reference-id-of-Domain-2" }If you want to specify a domain for a sub-project of "Project-Default", use the
<site name> > <project name> > <sub-project name>property, as described below.Tip For the properties in thisdomainMappingsection, ensure that you maintain the spaces before and after ">", for example"Site-1 > Project-Default". The spaces serve as a separator between the site and the projects.site nameThe Tableau site name, followed by the unique reference ID of the domain in Collibra in which you want to ingest resources from the Tableau site.
Important In the configuration file, use the actual site name, along with the domain reference ID, for example:"Collibra_tab_partner_site": "afc8cfb0-91f1-4075-a3e5-7ce6d1f9bcc9"site name > project nameThe Tableau project name, preceded by the name of the Tableau site to which it belongs, and followed by the unique reference ID of the domain in Collibra in which you want to ingest resources from the Tableau project.
Important In the configuration file, use the actual site and project names, along with the domain reference ID, for example:"Collibra_tab_partner_site > JB_Test_2812": "d224a1a5-43b4-43b2-8df0-ddf8f2726b82"site name > project name > sub-project nameThe Tableau sub-project name, preceded by the name of the Tableau site and project to which it belongs, and followed by the unique reference ID of the domain in Collibra in which you want to ingest resources from the Tableau sub-project.
Important In the configuration file, use the actual site, project and sub-project names, along with the domain reference ID, for example:"Collibra_tab_partner_site > JB_Test_2812 > ProjectJJ2": "d224a1a5-43b4-43b2-8df0-ddf8f2726b82"ExampleFor more
hostnameMappingconfiguration examples and results, go to Tableau hostname, schema, and system name mapping.{ "collibraSystemNames": { "files": [ {"filePath": "C:\\ProgramData\\Tableau\\Tableau Server\\data\\files\\sample.xls", "collibraSystemName": "sample-files" } ], "connectors": [ { "connectorUrl": "tableau-server-connector-url.com", "collibraSystemName": "Oracle-connector" } ], "cloudFiles": [ { "name": "file-name", "collibraSystemName": "FILE" } ] }, "hostnameMapping": { "found_dbname=*;found_hostname=abc.net;found_schema=DEFAULT": { "dbname": "CData", "schema": "Jan_1_2022", "dialect": "spark", "collibraSystemName": "TV_testing" } }, "filters": { "sites":{ "site_name":"domain_id" }, "projects":{ "site_name2 > project_name2": "domain-reference-id2", "site_name3 > project_name3 > subproject_name": "domain-reference-id2" } } }For more
hostnameMappingconfiguration examples and results, go to Tableau hostname, schema, and system name mapping.{ "collibraSystemNames": { "files": [ {"filePath": "C:\\ProgramData\\Tableau\\Tableau Server\\data\\files\\sample.xls", "collibraSystemName": "sample-files" } ], "connectors": [ { "connectorUrl": "tableau-server-connector-url.com", "collibraSystemName": "Oracle-connector" } ], "cloudFiles": [ { "name": "file-name", "collibraSystemName": "FILE" } ] }, "hostnameMapping": { "found_dbname=Test;found_hostname=*;found_schema=DEFAULT": { "dbname": "CData", "schema": "Jan_1_2022", "dialect": "spark", "collibraSystemName": "TV_testing" } }, "domainMapping": { "<Site-1>": "reference-id-of-Domain-1", "<Site-1> > <Project-Default>": "reference-id-of-Domain-2" } } NoCustom Properties
This section identifies to which Collibra Data Lineage service instance you want to upload the Tableau metadata.
Warning This applies only for Collibra Cloud for Government customers.
techlinKeyThe unique API key to connect to the Collibra Data Lineage service instance.
A unique user key is needed for each Collibra environment. If you're not sure what your user key is, please contact your Collibra Customer Success Manager.
Warning This applies only for Collibra Cloud for Government customers.
NotechlinHostThe URL of he Collibra Data Lineage service instance to which you want to upload Tableau metadata, for example "techlin-gcp-eu.collibra.com".
Warning This applies only for Collibra Cloud for Government customers.
NoAdvanced Properties
This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
ActiveThe option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
NoPagingThis section allows you to customize the Tableau API pagination settings.
The default values are sufficient in most cases; however, you can decrease them to help mitigate node limit errors, or increase them to speed up API calls.The complete list of pagination settings, descriptions and default values"paging": { "databasesPageSize": 100, "tablesPageSize": 100, "tablesColumnsPageSize": 100, "tableColumnsPageSize": 1000, "datasourcesPageSize": 50, "datasourcesFieldsPageSize": 50, "datasourceFieldsPageSize": 100, "worksheetsPageSize": 100, "worksheetsFieldsPageSize": 100, "worksheetFieldsPageSize": 1000, "usersPageSize": 100, "dashboardsPageSize": 100, "columnsLimit": 20, "fieldsLimit": 20 }Settings per metadata type and descriptions
Metadata type Setting and description Dashboard dashboardsPageSize: The number of dashboards per page.
Worksheet worksheetsPageSize: The number of worksheets per page.worksheetsFieldsPageSize: The number of worksheet fields per page.
Database databasesPageSize: The number of databases per page.
Table tablesPageSize: The number of tables per page.tablesColumnsPageSize: The number of table columns per page.
Table columns tableColumnsPageSize: The number of table columns per page.
Users usersPageSize: The number of users per page.
Data source datasourcesPageSize: The number of data sources per page.datasourcesFieldsPageSize: The number of data source fields per page.columnsLimit: The number of data source field columns per page.fieldsLimit: The number of referenced data source fields per page.
Data source field datasourceFieldsPageSize: The number of data source fields per page.columnsLimit: The number of data source field columns per page.fieldsLimit: The number of referenced data source fields per page.
NoLogging
This section contains the properties for debug logging. This setting is not valid for this integration.
NoDebug
This setting is not valid for this integration. It should be set to false. NoField Description Required Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
No
Source ID
The name of the data source. You can give this any name, as long as it is unique.
Warning You can only specify one source ID in this field, meaning you can only specify one source ID per
Warning If you are switching between the lineage harvester and Edge, the value in this field must exactly match the value of the
idproperty in your lineage harvester configuration file. Yes
Tableau connection
The Tableau connection that you created for ingestion in Data Catalog.
Tip Select the name that you provided in the Name field when you created a connection to Tableau.
Yes
Domain ID
The unique reference ID of the domain in Collibra Data Intelligence Platform in which you want to ingest the Tableau assets.
How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Yes
REST only
Indication whether or not you want to use both the Tableau REST API and Tableau Metadata API to harvest Tableau metadata.
- Cleared (default): The lineage harvester will use the REST API and Metadata API to harvest Tableau metadata.
- Selected: The lineage harvester will only use the REST API to harvest Tableau metadata.
Note This filed must be cleared, to:- Enable technical lineage and the automatic stitching of Column assets to Tableau Data Attribute assets.
- Harvest owner information for Tableau projects, workbooks and data models.
No
Exclude images
Indication whether or not you want to excluding the downloading of images.
- Cleared: Images are downloaded.
- Selected (default): Images are not downloaded.
Note The maximum number of images that can be uploaded to Collibra per day is determined by the configuration of the file upload service, in Collibra Console. For complete details, see the Upload configuration settings in DGC service configuration: options.
No
Site ID
The site IDs of the Tableau sites that you want to include in the ingestion process.
To ingest from multiple Tableau sites, enter each site ID in a separate Site ID field.
To ingest the default Tableau site, enter "Default" or leave the field empty. This field is not case sensitive.
Warning If you enter "Default", you must include the double quotation marks. The site IDs of any other Tableau sites must not be enclosed in double quotation marks. If the formatting of the site IDs does not conform to this detail, ingestion will fail.ExampleSee an exampleLet's say that you want to ingest from the default Tableau site and a site named ABC.
- In the Site ID field, enter "Default" for the default Tableau site.
- Click Add property.
An empty Site ID field is aded. - In the new Site ID field, enter the ID of the Tableau site ABC.

Tip Ensure that you specify the correct value. The correct value is the URL of the site to which you want to sign in. When you manually sign in to Tableau Server or Tableau Online, the site ID is the value that appears after /site/ in the browser address bar. In the following example URLs, the site ID isMarketingTeam:- Tableau Server: http://MyServer/#/site/MarketingTeam/projects
- Tableau Online: https://10ay.online.tableau.com/#/site/MarketingTeam/workbooks
On Tableau Server, however, the URL of the default site does not specify the site. For example, the URL for a view named Profits, on a site named Sales, is http://localhost/#/site/sales/views/profits. The URL for this same view on the default site is http://localhost/#/views/profits. The site name Sales does not figure in the URL. Yes
Site Name
The site name, or names, of the Tableau sites you specified in the Site ID field.
If you don't provide a site ID in the Site ID field, in which case the default Tableau site is ingested, leave this field blank.
No
Concurrency level
This field is intended to help if you are experiencing HTTP 401 Unauthorized errors due to too many concurrent HTTP calls, using the same token. It allows you to specify the internal sizing, meaning the amount of tasks that can be executed at the same time.
The default value is
10, meaning as many as 10 HTTP requests can take place in parallel. Consider reducing the value if you are experiencing HTTP 401 Unauthorized errors. Setting the value to1effectively disables the concurrency level, so that HTTP requests will be run in a synchronous manner, instead of in parallel. No
Source configuration
This field allows you to provide JSON code for database mapping, domain mapping and filtering.
If you previously integrated Tableau via the lineage harvester, you can copy and paste in this field the JSON code from your Tableau <source ID> configuration file.
Property
Description collibraSystemNames This section contains the system information for different Tableau data sources. Depending on the kind of data source or connection, you have to specify how to connect to this data source.
Tip For more information, see the Tableau documentation. We also recommend to check the list of supported connectors in Tableau.
filesThis section contains connection information to one or more files in Tableau.
Tip If you do not have files in Tableau, you can remove this section.
filePathThe full path to the file. For example, the path to a JSON file. collibraSystemNameThe system name of the file. connectorsThis section contains connection information to one or more connectors in Tableau.
Tip- If you do not have connectors in Tableau, you can remove this section.
- The values that you specify for this property are not case-sensitive.
connectorUrlThe URL of the connector. For example, the URL to Google Analytics. collibraSystemNameThe system name of the connector. cloudFilesThis section contains connection information to one or more cloud files in Tableau's input data.
Tip If you do not have cloud files in Tableau, you can remove this section.
nameThe name of the file. For example, the name of a Zendesk file. collibraSystemNameThe system name of the cloud file. This section allows you to map Tableau technical database, server and schema names to the respective real names, to preserve stitching.
WarninghostnameMappingreplaces the following deprecated properties- The
databaseMappingproperty. - The
databasessub-section of thecollibraSystemNamessection.
- The
hostnameMappingmust not be used in combination with either of these properties.If you use the
hostnameMappingsection, you can still use thecollibraSystemNameproperty in conjunction with thefiles,connectorsorcloudfilessub-sections.Example configuration"hostnameMapping": { "found_dbname=databasename1;found_hostname=*;found_schema=test": { "dbname": "mssql-database-name", "schema": "mssql-schema-name", "dialect": "mssql", "collibraSystemName": "mssql-system-name" } }For more example configurations, go to Tableau hostname, schema, and system name mapping.
found_dbname=<database name>;found_hostname=<server name>;found_schema=<schema name>The database information of supported data sources in Tableau that is typically collected by the lineage harvester. It allows you to specify the name of the database (found_dbname), on which server a database is running (found_hostname), and optionally, the name of the schema (found_schema).
dbnameThe name of the database of a supported data source in Tableau.
schemaThe name of the default schema of a supported data source in Tableau.
If the lineage harvester fails to find a specific schema, it uses the default schema.
dialectThe dialect of the supported data source in Tableau.
You don't have to specify a dialect; it will automatically be detected. If, however, you are using a dialect that is not supported, you can use this property to specify a supported dialect that is a close comparison. That way, most of your queries will be detected and processed.
Show me a list of dialects of supported data sources in Tableau.- redshift, for an Amazon Redshift data source.
- azure, for an Azure SQL Server data source.
- bigquery, for a Google BigQuery data source.
- greenplum, for a Greenplum data source.
- hive, for a HiveQL data source.
- oracle, for an Oracle data source.
- postgres, for a PostgreSQL data source.
- mssql, for a Microsoft SQL Server data source.
- mysql, for a MySQL data source.
- netezza, for a Netezza data source.
- hana, for a SAP HANA data source.
- spark, for a Spark SQL data source.
- sybase, for a Sybase data source.
- teradata, for a Teradata data source.
This section defines:
- From which Tableau sites and projects you want to harvest metadata.
- Into which domains in Collibra you want to ingest the corresponding assets.
Filtering is transitive, which means that all resources in a specified project, such as Tableau workbooks and all sub-projects, are ingested.
Tableau assets that are not mapped to the specified domains, for example the Tableau Server assets and the parent projects (if you specify their sub-projects), are ingested in the default domain.
Important- Filtering does not affect the amount of raw metadata that is harvested from Tableau and sent to the Collibra Data Lineage service instance. Rather, it determines which metadata is ingested as assets in Data Catalog.
- The
domainMappingandfilterssections are mutually exclusive. Do not include bothdomainMappingandfilterssections in your JSON file.
Tip- If you want to ingest all of the projects in a Tableau site into multiple domains in Collibra, use
domainMappingsection. - If you want to ingest all of the projects in a Tableau site into the default domain, use only the
domainIDproperty in the lineage harvester configuration file. ThedomainIDproperty represents the default domain. - If you want to ingest all of the projects in a Tableau site into a single domain in Collibra, use site filtering.
- If you want to ingest metadata from only some of the projects in a Tableau site, use project filtering.
- You can use site filtering and project filtering together:
- If filtering on the same site, this "filtering" is actually domain mapping, because nothing is filtered out. The contents of the projects are ingested in the specified domains, and the rest of the contents of the site are ingested in a different, specified domain.
- If you are site filtering on a specific site and project filtering a different site, then site filtering is again a form of domain mapping, and the filtered projects are ingested in their specified domains.
- If your lineage harvester configuration file includes sites that are not mentioned in the
filterssection of your <source ID> configuration file, those sites are ingested in the default domain.
The Tableau sites to be ingested and the domain in which you want to ingest metadata from the Tableau sites.
Tip If you have only one Tableau site, do not include asitessection in your <source ID> file. Instead, use aprojectssection, to filter on Tableau projects. Include asitessection only if all of the following are true:- You have more than one Tableau site.
- You want to ingest all of the metadata from only one Tableau site into a single domain in Collibra.
- The domain into which you want to ingest is not the default domain, meaning the domain specified in the
domainIdproperty in your lineage harvester configuration file.
site_name: domain_idsite_name- The name of the site to be ingested. The site name is case-sensitive.
domain_id- The unique reference ID of the domain in Collibra in which you want to ingest metadata. The domain ID is case-sensitive.
siteIdsproperty in the lineage harvester configuration file for Tableau. If thesite_nameordomain_idproperty is not specified for a site, the metadata from the site is ingested in the default domain.How do I find a domain reference ID?Open the relevant domain in Collibra. The URL looks like: https://<yourcollibrainstance>/domain/22258f64-40b6-4b16-9c08-c95f8ec0da26?view=00000000-0000-0000-0000-000000040001. In this example, the reference ID is in bold.
Show me the example{ "filters":{ "sites":{ "Training":"ca60b822-781b-4b3a-b44d-f65bd107ff92" }, "projects":{ "Testing > Databricks":"e8f4e4a8-4062-4a33-9b44-3ce3e18e4e22", "Product Demo > Customer Insights":"a305e6f7-7a49-49aa-aa85-41b1e689121b" } } }The Tableau projects to be ingested and the domain in which you want to ingest metadata from the Tableau projects or sub-projects.
Tip Project filtering is not relevant for those who have an Explorer role in Tableau, because Explorers need to configure permissions for each data object in Tableau that they want to ingest. As the Administrator role has access to all data objects, project filtering allows Administrators to specify which projects to ingest.
site_name > project_name : domain_idThe
site_nameshould be the Tableau site name. Theproject_nameshould be the Tableau project name.The
domain_idshould be the unique reference ID of the domain in Collibra in which you want to ingest metadata.When you specify the site and project names, the following rules apply:
- Add spaces before and after >. The spaces are separators between the site and project.
- Specify the full exact site and project names.
- The values are case-sensitive.
When you specify a Tableau project, all assets in the project are ingested in the specified domain. If you want to ingest assets from different Tableau projects in one domain, you can specify the same value for
domain idfor different projects.Example
"Collibra_tab_partner_site > JB_Test_2812": "d224a1a5-43b4-43b2-8df0-ddf8f2726b82"site_name > project_name > sub-project_name : domain_idThe
site_nameshould be the Tableau site name. Theproject_nameshould be the Tableau project name. Optionally, usesub-project_nameto specify the Tableau sub-project name.The
domain_idproperty should be the unique reference ID of the domain in Collibra in which you want to ingest metadata.When you specify the site, project and sub-project names, the following rules apply:
- Add spaces before and after >. The spaces are separators between the site and project.
- Specify the full exact site and project names.
- The values are case-sensitive.
Example
"Collibra_tab_partner_site > JB_Test_2812 > ProjectJJ2": "d224a1a5-43b4-43b2-8df0-ddf8f2726b82"domainMapping This section defines in which domains in Collibra you want to ingest assets from your Tableau sites and Tableau projects.
Domain mapping is transitive, meaning that all resources, such as Tableau workbooks and data attributes in a parent Tableau site, project or sub-project, are ingested in the same domain as the parent.
Important The
domainMappingandfilterssections are mutually exclusive. Do not include bothdomainMappingandfilterssections in your JSON file.Tip- If you want to ingest all of the projects in a Tableau site into multiple domains in Collibra, use
domainMappingsection. - If you want to ingest all of the projects in a Tableau site into the default domain, use only the
domainIDproperty in the lineage harvester configuration file. ThedomainIDproperty represents the default domain.Note Tableau assets that are not mapped to specific domains via thisdomainMappingsection, for example Tableau Server assets, are ingested in that default domain. - If you want to ingest all of the projects in a Tableau site into a single domain in Collibra, use site filtering.
- If you want to ingest metadata from only some of the projects in a Tableau site, use project filtering.
Show me an exampleLet's say that you have a Tableau site named "Site-1". You want to ingest all Tableau projects in "Site-1" in a domain named "Domain-1" in Collibra, with the exception of one Tableau project named "Project-Default", which you want to ingest in "Domain-2". You should configure the
domainMappingsection as follows."domainMapping": { "<Site-1>": "reference-id-of-Domain-1", "<Site-1> > <Project-Default>": "reference-id-of-Domain-2" }If you want to specify a domain for a sub-project of "Project-Default", use the
<site name> > <project name> > <sub-project name>property, as described below.Tip For the properties in thisdomainMappingsection, ensure that you maintain the spaces before and after ">", for example"Site-1 > Project-Default". The spaces serve as a separator between the site and the projects.site nameThe Tableau site name, followed by the unique reference ID of the domain in Collibra in which you want to ingest resources from the Tableau site.
Important In the configuration file, use the actual site name, along with the domain reference ID, for example:"Collibra_tab_partner_site": "afc8cfb0-91f1-4075-a3e5-7ce6d1f9bcc9"site name > project nameThe Tableau project name, preceded by the name of the Tableau site to which it belongs, and followed by the unique reference ID of the domain in Collibra in which you want to ingest resources from the Tableau project.
Important In the configuration file, use the actual site and project names, along with the domain reference ID, for example:"Collibra_tab_partner_site > JB_Test_2812": "d224a1a5-43b4-43b2-8df0-ddf8f2726b82"site name > project name > sub-project nameThe Tableau sub-project name, preceded by the name of the Tableau site and project to which it belongs, and followed by the unique reference ID of the domain in Collibra in which you want to ingest resources from the Tableau sub-project.
Important In the configuration file, use the actual site, project and sub-project names, along with the domain reference ID, for example:"Collibra_tab_partner_site > JB_Test_2812 > ProjectJJ2": "d224a1a5-43b4-43b2-8df0-ddf8f2726b82"ExampleFor more
hostnameMappingconfiguration examples and results, go to Tableau hostname, schema, and system name mapping.{ "collibraSystemNames": { "files": [ {"filePath": "C:\\ProgramData\\Tableau\\Tableau Server\\data\\files\\sample.xls", "collibraSystemName": "sample-files" } ], "connectors": [ { "connectorUrl": "tableau-server-connector-url.com", "collibraSystemName": "Oracle-connector" } ], "cloudFiles": [ { "name": "file-name", "collibraSystemName": "FILE" } ] }, "hostnameMapping": { "found_dbname=*;found_hostname=abc.net;found_schema=DEFAULT": { "dbname": "CData", "schema": "Jan_1_2022", "dialect": "spark", "collibraSystemName": "TV_testing" } }, "filters": { "sites":{ "site_name":"domain_id" }, "projects":{ "site_name2 > project_name2": "domain-reference-id2", "site_name3 > project_name3 > subproject_name": "domain-reference-id2" } } }For more
hostnameMappingconfiguration examples and results, go to Tableau hostname, schema, and system name mapping.{ "collibraSystemNames": { "files": [ {"filePath": "C:\\ProgramData\\Tableau\\Tableau Server\\data\\files\\sample.xls", "collibraSystemName": "sample-files" } ], "connectors": [ { "connectorUrl": "tableau-server-connector-url.com", "collibraSystemName": "Oracle-connector" } ], "cloudFiles": [ { "name": "file-name", "collibraSystemName": "FILE" } ] }, "hostnameMapping": { "found_dbname=Test;found_hostname=*;found_schema=DEFAULT": { "dbname": "CData", "schema": "Jan_1_2022", "dialect": "spark", "collibraSystemName": "TV_testing" } }, "domainMapping": { "<Site-1>": "reference-id-of-Domain-1", "<Site-1> > <Project-Default>": "reference-id-of-Domain-2" } } No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
No
Paging
This section allows you to customize the Tableau API pagination settings.
The default values are sufficient in most cases; however, you can decrease them to help mitigate node limit errors, or increase them to speed up API calls.The complete list of pagination settings, descriptions and default values"paging": { "databasesPageSize": 100, "tablesPageSize": 100, "tablesColumnsPageSize": 100, "tableColumnsPageSize": 1000, "datasourcesPageSize": 50, "datasourcesFieldsPageSize": 50, "datasourceFieldsPageSize": 100, "worksheetsPageSize": 100, "worksheetsFieldsPageSize": 100, "worksheetFieldsPageSize": 1000, "usersPageSize": 100, "dashboardsPageSize": 100, "columnsLimit": 20, "fieldsLimit": 20 }Settings per metadata type and descriptions
Metadata type Setting and description Dashboard dashboardsPageSize: The number of dashboards per page.
Worksheet worksheetsPageSize: The number of worksheets per page.worksheetsFieldsPageSize: The number of worksheet fields per page.
Database databasesPageSize: The number of databases per page.
Table tablesPageSize: The number of tables per page.tablesColumnsPageSize: The number of table columns per page.
Table columns tableColumnsPageSize: The number of table columns per page.
Users usersPageSize: The number of users per page.
Data source datasourcesPageSize: The number of data sources per page.datasourcesFieldsPageSize: The number of data source fields per page.columnsLimit: The number of data source field columns per page.fieldsLimit: The number of referenced data source fields per page.
Data source field datasourceFieldsPageSize: The number of data source fields per page.columnsLimit: The number of data source field columns per page.fieldsLimit: The number of referenced data source fields per page.
No
Debug
This setting is not valid for this integration. It should be set to false.
No
Log level
This setting is not valid for this integration. It should be set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for Teradata Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
External Database Name
The database value to be used as the database name in the full path (system -> database -> schema -> table). Use this field to ensure successful stitching for a database-less data source. You can specify one of the following values:
CData, which CDATA drivers returned as a placeholder. Use this value if you did not create a custom database name by using theCustomizedDefaultCatalogNameproperty when you registered your data source.- The custom database name that you specified for the
CustomizedDefaultCatalogNameproperty when you registered your data source.
See an exampleWhen you registered a Teradata data source on Edge and did not specify the
CustomizedDefaultCatalogNameproperty, the following full path to a column in Data Catalog is created and CData is used as the database name:Teredata_123(system) >CData(database) >Teredata_ABC(schema) >Table>ColumnWhen Collibra Data Lineage collects metadata from the Teradata data source, the value of the Database Name field is used as the schema name because Teradata is database-less.
If you do not enter a value for the External Database Name field, the value of the Collibra System Name field is used as the database name. If you set the Collibra system name setting to
true, the value of the Collibra System Name field is also used as the system name. In this case, the full path is shown as follows and does not match the full path in Data Catalog:Teredata_123(system) >Teredata_123(database) >Teredata_ABC(schema) >Table>ColumnIn this case, the stitching is missing because of the mismatch of the full paths. To match the full path and preserve stitching, you must specify
CDatafor the External Database Name field. No
Database Name
The name of the database or schema (these terms are synonymous for Teradata) from which you want to harvest metadata.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Object Names
This query retrieves a list of object names from which technical lineage can be created. The objects can include stored procedures, views, macros, and so on. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Logging This section contains general information about logging.
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
JDBC Connection
The JDBC connection that you created for Catalog JDBC ingestion.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
External Database Name
The database value to be used as the database name in the full path (system -> database -> schema -> table). Use this field to ensure successful stitching for a database-less data source. You can specify one of the following values:
CData, which CDATA drivers returned as a placeholder. Use this value if you did not create a custom database name by using theCustomizedDefaultCatalogNameproperty when you registered your data source.- The custom database name that you specified for the
CustomizedDefaultCatalogNameproperty when you registered your data source.
See an exampleWhen you registered a Teradata data source on Edge and did not specify the
CustomizedDefaultCatalogNameproperty, the following full path to a column in Data Catalog is created and CData is used as the database name:Teredata_123(system) >CData(database) >Teredata_ABC(schema) >Table>ColumnWhen Collibra Data Lineage collects metadata from the Teradata data source, the value of the Database Name field is used as the schema name because Teradata is database-less.
If you do not enter a value for the External Database Name field, the value of the Collibra System Name field is used as the database name. If you set the Collibra system name setting to
true, the value of the Collibra System Name field is also used as the system name. In this case, the full path is shown as follows and does not match the full path in Data Catalog:Teredata_123(system) >Teredata_123(database) >Teredata_ABC(schema) >Table>ColumnIn this case, the stitching is missing because of the mismatch of the full paths. To match the full path and preserve stitching, you must specify
CDatafor the External Database Name field. No
Database Name
The name of the database or schema (these terms are synonymous for Teradata) from which you want to harvest metadata.
Yes
Queries
The queries to download all the data that is required to create technical lineage. The queries vary depending on the data source you use. The query code is automatically available. However, you can modify the query code if needed.
Example Enter the following filter in a Views query:
where v.table_schema not in ('pg_catalog', 'information_schema');. This query excludes the pg_catalog and information_schema schemas, which don't contain customer data. If you want to exclude other schemas, adjust the query to, for examplewhere v.table_schema not in ('pg_catalog', 'information_schema', 'another_schema');.Note- If you change queries, you can only use supported SQL syntax.
- Collibra Support does not provide support for customized SQL files.
Query Description Columns This query retrieves the columns, tables, schemas, databases or projects fields in the form: database or project > schema > table > column. Object Names
This query retrieves a list of object names from which technical lineage can be created. The objects can include stored procedures, views, macros, and so on. Yes
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
No
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Debug
An option to enable logging of a JDBC job. If you enable logging, you can download the output file of the JDBC job in the Edge Jobs dashboard (beta). The output file contains the logs of the JDBC driver. For more information about downloading the output file, go to Download job output files.
Select one of the following values:
True- Enables logging of the JDBC job.
False- Disables logging of the JDBC job. This is the default value.
No
Log level
An option to determine the verbosity level of Catalog connector log files. By default, this option is set to No logging.
No
Field Description Required? Capability This section contains general information about the capability.
Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Main Properties This section contains the information for creating a technical lineage.
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Advanced Properties This section contains the advanced properties for creating a technical lineage.
Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
Field Description Required? Name
The name of the Edge capability.
Yes
Description
The description of the Edge capability.
Yes
Capability template
The capability template. The value that you select in this field determines which sections appear on the page.
Select the following Edge capability:
Technical Lineage for SqlDirectory Yes
Source ID
The name of the data source. Specify a name that is unique.
Yes
Shared Storage Connection
The Shared Storage connection that you created.
No
Mask The pattern of the file names in the directory. By default, the value is
*. Yes
Dialect The dialect of the database.
See the list of allowed values.You can enter one of the following values:
azure, for an Azure SQL Server data source.bigquery, for a Google BigQuery data source.db2, for an IBM DB2 data source.hana, for an SAP HANA data source.hana-cviews, for getting lineage from calculated views in an SAP HANA Classic on-premises data source.hana-cviews-v2, for getting lineage from calculated views in an SAP HANA Cloud/Advanced data source.ImportantTo get technical lineage including calculated views, you must harvest SAP HANA by adding two Technical Lineage for SqlDirectory capabilities with the Shared Storage connections. In one capability, specify the
hanadialect, and in the other, specify thehana-cviewsorhana-cviews-v2dialect.hive, for a HiveQL data source.greenplum, for a Greenplum data source.mssql, for a Microsoft SQL Server data source.mysql, for a MySQL data source.netezza, for a Netezza data source.oracle, for an Oracle data source.postgres, for a PostgreSQL data source.redshift, for an Amazon Redshift data source.snowflake, for a Snowflake data source.spark, for a Spark SQL data source.sybase, for a Sybase data source.teradata, for a Teradata data source.
Yes
Collibra System Name
The system or server name of the data source. This field is also the full name of your System asset in Data Catalog.
The value of this field must be the same as the full name of the System asset that you created when you registered the data source.
Yes
Database The name of your database, which is also the name of your Database asset in Data Catalog.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Schema The name of the default schema, if not specified in the data source itself. This corresponds to the name of your Schema asset.
Note The database and schema names in the SQL statements in your SQL files take precedence over the values that you provide for the Database and Schema fields in the technical lineage for SqlDirectory capability. If your SQL statements contain database and schema names, Collibra Data Lineage uses them for stitching. If your SQL statements do not contain database and schema names, Collibra Data Lineage uses the values of the Database and Schema fields in the capability for stitching. Fore more information, go to Prepare the SQL directory and Automatic stitching for technical lineage. Yes
Database-System mapping This optional
More information and example configurationLet’s say you use the
Now let’s say that you have a SQL statement that selects data from a database DB2 (which is in SystemB) and inserts the data in database DB3 (which is part of SystemC). Both of these databases will be associated with SystemA, and both will appear under SystemA in the Browse tab pane. Therefore, stitching fails and duplicate databases might appear.
To resolve this issue and obtain stitching, you can use this
No
Property This section contains the custom parameters you can specify to create technical lineage. Click Add property to add a property.
You can use this field to set the HTTP timeout duration by adding the httpTimeout property:
httpTimeoutName Description Type Encryption Example value httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
Text Not encrypted (plain text) 15 Type Value Type Name Example value Text
Plaintext
httpTimeoutSets the HTTP timeout duration, in seconds. You can enter a value in the range of 1 to 3599. The default value is 15.
15 Warning If you are a Collibra Cloud for Government customer, this field is required to connect to a Collibra Data Lineage service instance:Properties for Collibra Cloud for Government customersName Description Type Encryption Example value techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Text Not encrypted (plain text) https://techlin-gcp-dev.collibra.com techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
Text To be encrypted by Edge management server Value will be stored on Edge Type Value Type Name Value Text
Plaintext
techlinHostThis is the URL of the Collibra Data Lineage service instance to which you want to upload metadata, for example
techlin-gcp-eu.collibra.com.Example: https://techlin-gcp-dev.collibra.com Text
Secret
techlinKeyThis is the unique API key to connect to a Collibra Data Lineage service instance.
Specify a unique user key for each Collibra environment. If you're not sure what your user key is, contact your Collibra Customer Success Manager.
<your-techlin-key> Yes for US government customers.Dependent On Sources
This option allows you to provide table-definition details from an independent data source to a data source that is dependent on those details. This is needed to avoid analysis errors and to have a complete lineage that includes lineage from the SQL statements from dependent data sources.
To use this option, enter the source ID of the independent source.
Show me an exampleLet's consider an example. Let's say that you want to create a technical lineage for two data sources:
Database1 contains the DDL that specifies that the database has a table named "Table1", which has three columns: Col1, Col2, Col3, and Col4.
Database2 contains an SQL statement: SELECT * from Database1.Schema1.Table1.
The SQL statement in Database2 refers to the table in Database1. Therefore, to get lineage from the statement in Database2, the table definition from Database1 must be known. In this case, we say that Database2 is dependent on Database1. Database1 is considered the independent data source.
To configure this option, specify the Source ID of the independent data source, in this example, Database1, as shown in the following imagee
For complete information, go to Sharing database models across data sources.
Delete Raw Metadata After Processing
Technical lineage via Edge harvests raw metadata from specified data sources and uploads it in a ZIP file to a Collibra Data Lineage service instance. This option indicates whether the raw metadata should be deleted from the Collibra Data Lineage service instance after the metadata that is targeted for ingestion in Data Catalog is processed.
Select this option to indicate that the raw source metadata is deleted after processing.
Clear the checkbox to keep the raw source metadata after processing. In this case, it is stored in the Collibra infrastructure.
No
Analyze Only
This option determines whether to only load and analyze the source data on the Collibra Data Lineage service instances.
When you select this option, the technical lineage of the data source is not created during the synchronization of the capability. Selecting this option is equivalent to entering the
load-sourcesandanalyzecommand with a source specified when you use the lineage harvester.This option is not enabled by default.
Use caseYou can use this option to control when to start full synchronization of data sources. For example if you have three data sources, A, B, and C, you can synchronize the data sources as follows:
- During weekdays, synchronize data sources A and B with the Analyze Only checkbox selected in the capabilities. Collibra Data Lineage only loads and analyzes data sources A and B without synchronizing the technical lineage.
- On the weekend, synchronize data source C without selecting the Analyze Only checkbox in the capability. Collibra Data Lineage synchronizes the technical lineage for all data sources including A, B, and C.
No
Active
The option determines whether to include or remove the technical lineage of the data source.
Select this option to include the technical lineage of this data source.
Clear the checkbox to exclude the technical lineage of this data source.
Yes
- Click Save.
The capability is added to the Edge site.
The fields become read-only. - Click Create.
The capability is added to the Edge site.
The fields become read-only.
-
Synchronize your technical lineage.
You can synchronize your technical lineage manually or automatically by adding a synchronization schedule.
If you want to synchronize technical lineage by using the Collibra Catalog Cloud Ingestions API, use the

/technicalLineage/harvester/{assetId}API, where{assetId}is the UUID of the asset for which to generate the technical lineage.If you synchronize a capability without selecting the Analyze Only option in the capability, a full synchronization is run, which is equivalent to the
full-synccommand with the-sargument specified when you use the lineage harvester. You can synchronize as many technical lineage capabilities in parallel as you want. If a full synchronization is in progress, the other capabilities are put in a queue until the existing synchronization completes. Then, this new synchronization starts automatically.If you include multiple databases in your technical lineage capability template, you don't have to synchronize each database separately. One synchronization job will harvest the metadata from all relevant databases.
Note During the ingestion process, relations of the type "Data Element targets / sources Data Element" are automatically created between certain assets. Any relations of this type that you manually create between assets will be deleted during the synchronization process.Prerequisites
- A global role that has the following global permission:
- Catalog, for example Catalog Author
- View Edge connections and capabilities
- A resource role with Configure external system resource permission, for example Owner.
- Data source-specific permissions.
Steps
- Manually synchronize the technical lineage
- Add a synchronization schedule
- Open a Database asset page of a registered database.
-
In the tab
- On the Lineage Extraction tab pane, click Synchronize Lineage.A notification indicates synchronization has started.The synchronization job is started. The lineage is ingested based on the configuration provided.
- Open the Database asset page of a registered database.
-
In the tab
- On the Lineage Extraction tab pane, click Add Schedule.
- Enter the required information and click Save:
Field Description Repeat The interval when you want to synchronize automatically. The possible values are: Daily, Weekly, Monthly, and Cron expression. CronThe Quartz Cron expression that determines when the synchronization takes place.
This field is only visible if you select
Cron expressionin the Repeat field.EveryThe day on which you want to synchronize, for example, Sunday.
This field is only visible if you select
Weeklyin the Repeat field.Every firstThe day of the month on which you want to synchronize, for example, Tuesday.
This field is only visible if you select
Monthlyin the Repeat field.At
The time at which you want to synchronize automatically, for example, 14:00.
- You can only schedule on the hour. For example, you can add a synchronization schedule at 8:00, but not at 8:45. If you try to add it at 8:45, we will default it to 8:00. Use a cron expression if you don't want to schedule on the hour.
- This field is only visible if you select
Daily,Weekly, orMonthlyin the Repeat field.
Time zone The time zone for the schedule.
- A global role that has the following global permission:
-
Synchronize your technical lineage.
You can synchronize your technical lineage manually or automatically by adding a synchronization schedule.
If you want to synchronize technical lineage by using the Collibra Catalog Cloud Ingestions API, use the
/genericIntegration/{ingestibleId}/runAPI, where{ingestibleId}is the capability ID.If you synchronize a capability without selecting the Analyze Only option in the capability, a full synchronization is run, which is equivalent to the
full-synccommand with the-sargument specified when you use the lineage harvester. You can synchronize as many technical lineage capabilities in parallel as you want. If a full synchronization is in progress, the other capabilities are put in a queue until the existing synchronization completes. Then, this new synchronization starts automatically.If you include multiple databases in your technical lineage capability template, you don't have to synchronize each database separately. One synchronization job will harvest the metadata from all relevant databases.
Note During the ingestion process, relations of the type "Data Element targets / sources Data Element" are automatically created between certain assets. Any relations of this type that you manually create between assets will be deleted during the synchronization process.Prerequisites
- A global role that has the following global permission:
- Catalog, for example Catalog Author
- View Edge connections and capabilities
- A resource role with Configure external system resource permission, for example Owner.
- Data source-specific permissions.
- The permissions to retrieve the metadata of the following database components through the JDBC Driver Database Metadata methods:
- Schemas
- Tables
- Columns
Steps
- Manually synchronize the technical lineage
- Add a synchronization schedule
-
On the main toolbar, click
, and then click
 Catalog.
Catalog.
The Catalog Home opens. -
On the main toolbar, click
 .
.
The Create dialog box appears. - In the Register with Edge section of the Create dialog box, click Register a data source.
The Register content page opens. -
In the tab bar, click
Integrations.
The Integrations page opens. - Click the
Integration Configuration tab.
- Locate the connection that you used when you added the technical lineage capability, and click the link in the
The technical lineage capability configuration page opens. - On the A notification indicates synchronization has started.The synchronization job is started. The lineage is ingested based on the configuration provided.
-
On the main toolbar, click
, and then click
Catalog.
The Catalog Home opens. -
On the main toolbar, click .
The Create dialog box appears. - In the Register with Edge section of the Create dialog box, click Register a data source.
The Register content page opens. -
In the tab bar, click
Integrations.
The Integrations page opens. - Click the
Integration Configuration tab.
- Locate the connection that you used when you added the technical lineage capability, and click the link in the
The technical lineage capability configuration page opens. - On the
- Enter the required information and click Save:
Field Description Repeat The interval when you want to synchronize automatically. The possible values are: Daily, Weekly, Monthly, and Cron expression. CronThe Quartz Cron expression that determines when the synchronization takes place.
This field is only visible if you select
Cron expressionin the Repeat field.EveryThe day on which you want to synchronize, for example, Sunday.
This field is only visible if you select
Weeklyin the Repeat field.Every firstThe day of the month on which you want to synchronize, for example, Tuesday.
This field is only visible if you select
Monthlyin the Repeat field.At
The time at which you want to synchronize automatically, for example, 14:00.
- You can only schedule on the hour. For example, you can add a synchronization schedule at 8:00, but not at 8:45. If you try to add it at 8:45, we will default it to 8:00. Use a cron expression if you don't want to schedule on the hour.
- This field is only visible if you select
Daily,Weekly, orMonthlyin the Repeat field.
Time zone The time zone for the schedule.
- A global role that has the following global permission:
-
Synchronize your technical lineage.
You can synchronize your technical lineage manually or automatically by adding a synchronization schedule.
If you want to synchronize technical lineage by using the Collibra Catalog Cloud Ingestions API, use the
/genericIntegration/{ingestibleId}/runAPI, where{ingestibleId}is the capability ID.If you synchronize a capability without selecting the Analyze Only option in the capability, a full synchronization is run, which is equivalent to the
full-synccommand with the-sargument specified when you use the lineage harvester. You can synchronize as many technical lineage capabilities in parallel as you want. If a full synchronization is in progress, the other capabilities are put in a queue until the existing synchronization completes. Then, this new synchronization starts automatically.If you include multiple databases in your technical lineage capability template, you don't have to synchronize each database separately. One synchronization job will harvest the metadata from all relevant databases.
Note During the ingestion process, relations of the type "Data Element targets / sources Data Element" are automatically created between certain assets. Any relations of this type that you manually create between assets will be deleted during the synchronization process.Prerequisites
- A global role that has the following global permission:
- Catalog, for example Catalog Author
- View Edge connections and capabilities
- A resource role with Configure external system resource permission, for example Owner.
- Data source-specific permissions.
- The permissions to retrieve the metadata of the following database components through the JDBC Driver Database Metadata methods:
- Schemas
- Tables
- Columns
Steps
- Manually synchronize the technical lineage
- Add a synchronization schedule
-
On the main toolbar, click
, and then click
Catalog.
The Catalog Home opens. -
On the main toolbar, click .
The Create dialog box appears. - In the Register with Edge section of the Create dialog box, click Register a data source.
The Register content page opens. -
In the tab bar, click
Integrations.
The Integrations page opens. - Click the
Integration Configuration tab.
- Locate the connection that you used when you added the technical lineage capability, and click the link in the
The technical lineage capability configuration page opens. - On the A notification indicates synchronization has started.The synchronization job is started. The lineage is ingested based on the configuration provided.
-
On the main toolbar, click
, and then click
Catalog.
The Catalog Home opens. -
On the main toolbar, click .
The Create dialog box appears. - In the Register with Edge section of the Create dialog box, click Register a data source.
The Register content page opens. -
In the tab bar, click
Integrations.
The Integrations page opens. - Click the
Integration Configuration tab.
- Locate the connection that you used when you added the technical lineage capability, and click the link in the
The technical lineage capability configuration page opens. - On the
- Enter the required information and click Save:
Field Description Repeat The interval when you want to synchronize automatically. The possible values are: Daily, Weekly, Monthly, and Cron expression. CronThe Quartz Cron expression that determines when the synchronization takes place.
This field is only visible if you select
Cron expressionin the Repeat field.EveryThe day on which you want to synchronize, for example, Sunday.
This field is only visible if you select
Weeklyin the Repeat field.Every firstThe day of the month on which you want to synchronize, for example, Tuesday.
This field is only visible if you select
Monthlyin the Repeat field.At
The time at which you want to synchronize automatically, for example, 14:00.
- You can only schedule on the hour. For example, you can add a synchronization schedule at 8:00, but not at 8:45. If you try to add it at 8:45, we will default it to 8:00. Use a cron expression if you don't want to schedule on the hour.
- This field is only visible if you select
Daily,Weekly, orMonthlyin the Repeat field.
Time zone The time zone for the schedule.
- A global role that has the following global permission:
-
Synchronize your technical lineage.
You can synchronize your technical lineage manually or automatically by adding a synchronization schedule.
If you want to synchronize technical lineage by using the Collibra Catalog Cloud Ingestions API, use the
/genericIntegration/{ingestibleId}/runAPI, where{ingestibleId}is the capability ID.If you synchronize a capability without selecting the Analyze Only option in the capability, a full synchronization is run, which is equivalent to the
full-synccommand with the-sargument specified when you use the lineage harvester. You can synchronize as many technical lineage capabilities in parallel as you want. If a full synchronization is in progress, the other capabilities are put in a queue until the existing synchronization completes. Then, this new synchronization starts automatically.If you include multiple databases in your technical lineage capability template, you don't have to synchronize each database separately. One synchronization job will harvest the metadata from all relevant databases.
Note During the ingestion process, relations of the type "Data Element targets / sources Data Element" are automatically created between certain assets. Any relations of this type that you manually create between assets will be deleted during the synchronization process.Steps
- Manually synchronize technical lineage
- Add a synchronization schedule
-
On the main toolbar, click
, and then click
Catalog.
The Catalog Home opens. -
On the main toolbar, click .
The Create dialog box appears. - In the Register with Edge section of the Create dialog box, click Register a data source.
The Register content page opens. -
In the tab bar, click
Integrations.
The Integrations page opens. - Click the
Integration Configuration tab.
- Locate the Databricks connection that you used when you added the technical lineage capability, and click the link in the The technical lineage capability configuration page opens.
- In the Configuration Section section, click Add Configuration.
- Select the System asset in which the Databricks assets were ingested. Collibra Data Lineage stitches the ingested data objects to the selected assets when the synchronization of this capability starts.
- In the Configuration Section section, click Synchronize now.A notification indicates synchronization has started.The synchronization job is started. CollibraData Lineage ingests the metadata from Databricks Unity Catalog and processes the metadata to create technical lineage.
-
On the main toolbar, click
, and then click
Catalog.
The Catalog Home opens. -
On the main toolbar, click .
The Create dialog box appears. - In the Register with Edge section of the Create dialog box, click Register a data source.
The Register content page opens. -
In the tab bar, click
Integrations.
The Integrations page opens. - Click the
Integration Configuration tab.
- Locate the Databricks connection that you used when you added the technical lineage capability, and click the link in the The technical lineage capability configuration page opens.
- In the Configuration Section section, click Add Configuration.
- Select the System asset in which the Databricks assets were ingested. Collibra Data Lineage stitches the ingested data objects to the selected assets when the synchronization of this capability starts.
- On the
- Enter the required information and click Save:
Field Description Repeat The interval when you want to synchronize automatically. The possible values are: Daily, Weekly, Monthly, and Cron expression. CronThe Quartz Cron expression that determines when the synchronization takes place.
This field is only visible if you select
Cron expressionin the Repeat field.EveryThe day on which you want to synchronize, for example, Sunday.
This field is only visible if you select
Weeklyin the Repeat field.Every firstThe day of the month on which you want to synchronize, for example, Tuesday.
This field is only visible if you select
Monthlyin the Repeat field.At
The time at which you want to synchronize automatically, for example, 14:00.
- You can only schedule on the hour. For example, you can add a synchronization schedule at 8:00, but not at 8:45. If you try to add it at 8:45, we will default it to 8:00. Use a cron expression if you don't want to schedule on the hour.
- This field is only visible if you select
Daily,Weekly, orMonthlyin the Repeat field.
Time zone The time zone for the schedule.
-
View the summary of the results.
After you synchronize the technical lineage, you can view the ingestion report. This shows the impact of technical lineage synchronization on the assets in Collibra Data Intelligence Platform.
Steps
- Open the Activities list.
- In the row containing the synchronization job, click Result.The Lineage harvester synchronization results dialog box appears.
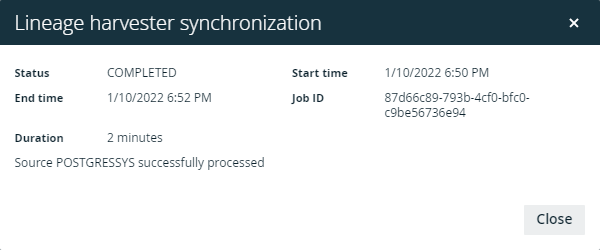
- In the row containing the synchronization job, click Result.The synchronization report summary appears.
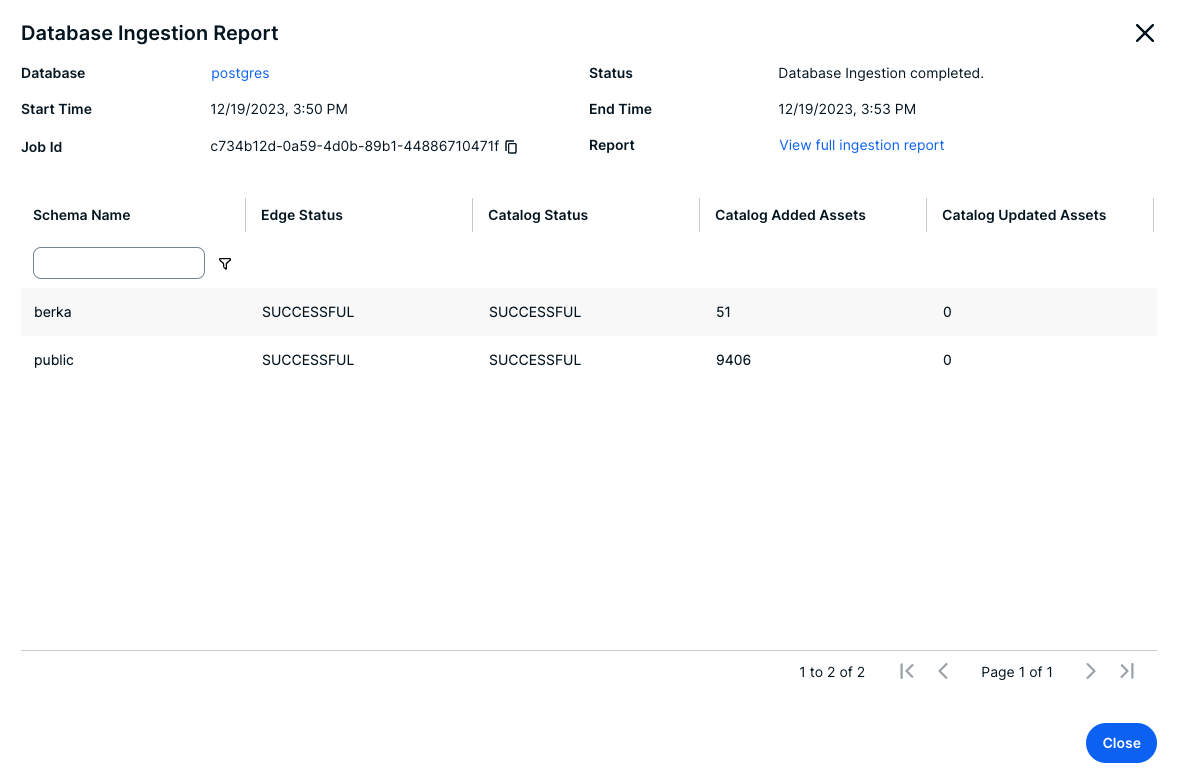
Tip The Job ID is useful if you need to troubleshoot the synchronization job with Collibra Support.
-
View the summary of the results.
After you synchronize the technical lineage, you can view the ingestion report. This shows the impact of technical lineage synchronization on the assets in Collibra Data Intelligence Platform.
Steps
- Open the Activities list.
-
In the row for your capability, click Result.
The Synchronization Result dialog box opens.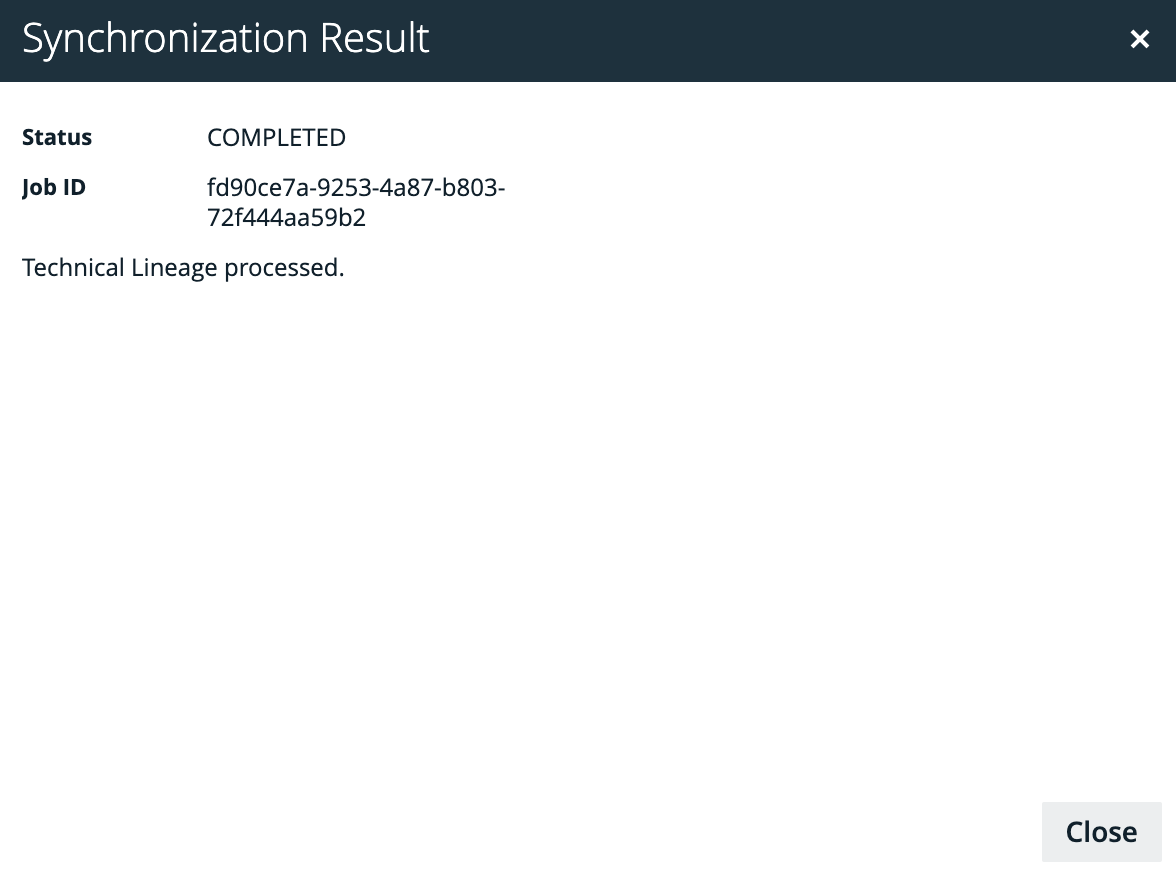
- In the row containing the synchronization job, click Result.The Synchronization Result dialog box opens.
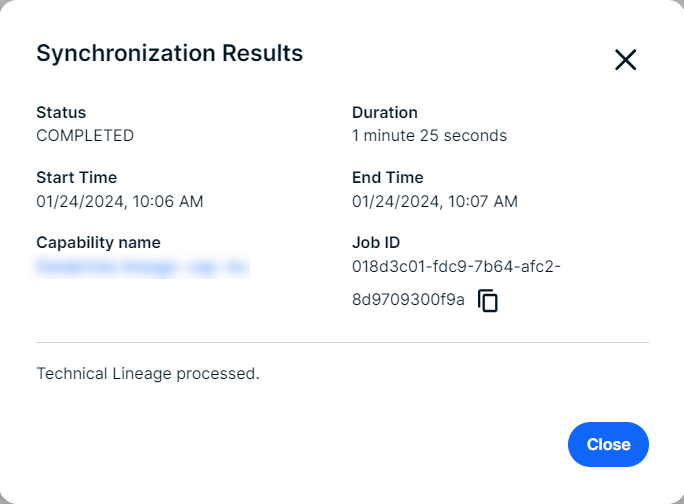
Tip The Job ID is useful if you need to troubleshoot the synchronization job with Collibra Support.
If there are errors in the synchronization result, go to Technical lineage via Edge troubleshooting for Databricks in Collibra Support Portal for more information.
-
Synchronize your technical lineage.
You can synchronize your technical lineage manually or automatically by adding a synchronization schedule.
If you want to synchronize technical lineage by using the Collibra Catalog Cloud Ingestions API, use the
/genericIntegration/{ingestibleId}/runAPI, where{ingestibleId}is the capability ID.If you synchronize a capability without selecting the Analyze Only option in the capability, a full synchronization is run, which is equivalent to the
full-synccommand with the-sargument specified when you use the lineage harvester. You can synchronize as many technical lineage capabilities in parallel as you want. If a full synchronization is in progress, the other capabilities are put in a queue until the existing synchronization completes. Then, this new synchronization starts automatically.Steps
- Manually synchronize technical lineage
- Add a synchronization schedule Use Collibra
-
On the main toolbar, click
, and then click
Catalog.
The Catalog Home opens. -
In the tab bar, click
Integrations.
The Integrations page opens. - Click the
Integration Configuration tab.
- Locate the GCP connection that you used when you added the technical lineage for Google Dataplex capability, and click the link in the capability column. If multiple capabilities exist for the GCP connection, expand them to locate your technical lineage for Google Dataplex capability. The synchronization configuration page opens.
- In the Synchronization Configuration section, click Add Configuration.
- In System, select the System asset to which Collibra Data Lineage stitches the data objects from Dataplex.
- To add a Project ID where Dataplex is enabled, click Add Project Id. You can add multiple Project IDs. The capability will search in these projects.
- Click Save.
- Click Synchronize.
A notification indicates the synchronization has started.
-
On the main toolbar, click
, and then click
Catalog.
The Catalog Home opens. -
In the tab bar, click
Integrations.
The Integrations page opens. - Click the
Integration Configuration tab.
- Locate the GCP connection that you used when you added the technical lineage for Google Dataplex capability, and click the link in the capability column. If multiple capabilities exist for the GCP connection, expand them to locate your technical lineage for Google Dataplex capability. The synchronization configuration page opens.
- In the Synchronization Configuration section, click Add Configuration.
- In System, select the System asset to which Collibra Data Lineage stitches the data objects from Dataplex.
- To add a Project ID where Dataplex is enabled, click Add Project Id. You can add multiple Project IDs. The capability will search in these projects.
- Click Save.
- On the Synchronization Schedule tab pane, click Add Schedule.
- Enter the required information and click Save:
Field Description Repeat The interval when you want to synchronize automatically. The possible values are: Daily, Weekly, Monthly, and Cron expression. CronThe Quartz Cron expression that determines when the synchronization takes place.
This field is only visible if you select
Cron expressionin the Repeat field.EveryThe day on which you want to synchronize, for example, Sunday.
This field is only visible if you select
Weeklyin the Repeat field.Every firstThe day of the month on which you want to synchronize, for example, Tuesday.
This field is only visible if you select
Monthlyin the Repeat field.At
The time at which you want to synchronize automatically, for example, 14:00.
- You can only schedule on the hour. For example, you can add a synchronization schedule at 8:00, but not at 8:45. If you try to add it at 8:45, we will default it to 8:00. Use a cron expression if you don't want to schedule on the hour.
- This field is only visible if you select
Daily,Weekly, orMonthlyin the Repeat field.
Time zone The time zone for the schedule.
-
View the summary of the results.
After you synchronize the technical lineage, you can view the ingestion report. This shows the impact of technical lineage synchronization on the assets in Collibra.
Steps
- Open the Activities list.
- In the row containing the synchronization job, click Result.The Synchronization Result dialog box opens.
Tip The Job ID is useful if you need to troubleshoot the synchronization job with (Undefined variable: CollibraProducts.DICAcronym) Support.


What's next?
- CollibraData Lineage visualizes lineage for Google Dataplex down to the table level. To view the technical lineage for Google Dataplex, ensure that you select Objects in the toolbar of your technical lineage graph.
- Currently, stitching is not supported for the table level lineage. This support will be added in a future release with the addition of column level lineage support. When this support is available, stitching will work, regardless of whether you integrated Google Dataplex or registered Google BigQuery databases by using the BigQuery JDBC connector.
- Databricks Unity Catalog does not provide source code for each transformation. Therefore, no source code is shown in the source code pane in the technical lineage graph.
- Collibra Data Lineage ingests lineage for Databases, Schemas, Tables, and Columns, but does not ingest any other assets such as Notebooks or Workflows.
For more information, go to Supported transformation details.