Release 2024.05
Release Information
- Release date of Data Quality & Observability Classic 2024.05: June 3, 2024
- Publication dates:
- Release notes: April 22, 2024
- Documentation Center: May 2, 2024
Highlights
Important
In the upcoming Data Quality & Observability Classic 2024.07 (July 2024) release, the classic UI will no longer be available.
- Integration
- For a more comprehensive bi-directional integration of Data Quality & Observability Classic and Collibra Platform, you can now view data quality scores and run jobs from the Data Quality Jobs modal on asset pages. You can find this modal via the View Monitoring link located on the At a glance pane to the right of the Quality tab on asset pages.
This significant enhancement strengthens the connection between Data Quality & Observability Classic and Collibra Platform, allowing you to compare data quality relations seamlessly without leaving the asset page. Whether you are a data steward, data engineer, or another role in between, this enhanced integration breaks down barriers, empowering you with the ability to unlock data quality and observability insights directly within Collibra Platform. - Note A fix for the issue that has prevented the use of the Quality tab on asset pages for users who do not have a Data Quality & Observability Classic license is scheduled for the third quarter (Q3) of 2024.
- Pushdown
- Additionally, Pushdown for SAP HANA and Microsoft SQL Server are now available for preview testing. Contact a Collibra CSM or apply directly to participate in private preview testing for SAP HANA Pushdown.
-
Pushdown is an alternative compute method for running DQ Jobs, where Data Quality & Observability Classic submits all of the job's processing directly to a SQL data warehouse. When all of your data resides in the SQL data warehouse, Pushdown reduces the amount of data transfer, eliminates egress latency, and removes the Spark compute requirements of a DQ Job.
We are delighted to announce that Pushdown is now generally available, for three new data sources, including:
- SQL Assistant for Data Quality
- SQL Assistant for Data Quality is now generally available! This exciting tool allows you to automate SQL rule writing and troubleshooting to help you accelerate the discovery, curation, and visualization of your data. By leveraging SQL Assistant for Data Quality powered by Collibra AI, beginner and advanced SQL users alike can quickly discover key data points and insights and then convert them into rules.
- Explorer
- Profile
- Findings
- Alert Builder
- Further, we've added the ability to create an AI prompt for the frequency distribution of all values within a column. From the Collibra AI dropdown menu, select Frequency Distribution in the Advanced section and specify a column for Collibra AI to create a frequency distribution query. (idea #DCC-I-2639)
Anywhere Dataset Overview is, so is SQL Assistant for Data Quality. This means you can unlock the power of Collibra AI from the following pages:
For the most robust SQL rule building experience, you can also find SQL Assistant for Data Quality when adding or editing a rule on the Rule Workbench page.
Enhancements
Capabilities
- We added a JSON tab to the Review step in Explorer and the Findings page to allow you to analyze, copy, and run the JSON payload of jobs.
- When exporting rule breaks with details, the column order in the .xlsx file now matches the arrangement in the Data Preview table on the Findings page. (idea #DCC-I-1656, DCC-I-2400)
- Specifically, the columns in the export file are organized from left to right, following the same sequence as in the Data Preview table. The columns are sorted with the following priority:
- Column names starting with numbers.
- Columns names starting with letters.
- Column names starting with special characters.
- Specifically, the columns in the export file are organized from left to right, following the same sequence as in the Data Preview table. The columns are sorted with the following priority:
- When a pullup has multiple link IDs in a break record export file, the link IDs will be parsed into multiple columns.
- To improve user experience when using the Rules table on the Findings page, we’ve locked the column headers and added a horizontal scrollbar to the rule breaks sub-table.
- You can now configure your user account to receive email notifications for your assignments by clicking your user avatar in the upper right corner of the Data Quality & Observability Classic application and selecting "Send me email notifications for my assignments" in the Notifications section.
- When a user who is not the dataset owner or has ROLE_ADMIN or ROLE_DATASET_MANAGER attempts to delete one or multiple datasets, they are prevented from a successful dataset deletion, and an error message displays to help inform them of the role requirements needed to delete datasets. (idea #DCC-I-1938)
- We added a new Attributes section with two filter options to the Dataset Manager. (idea #DCC-I-2155)
- The Rules Defined filter option displays the datasets in your environment that contain rules only (not alerts).
- The Alerts Defined filter option displays the datasets in your environment that contain alerts only (not rules).
- When both filter options are selected, datasets that contain both rules and alerts display.
- With this release, we made several additional enhancements to SQL Assistant for Data Quality:
- The Collibra AI dropdown menu now has improved organization. We split the available options into two sections:
- Basic: For standard rule generation and troubleshooting suggestions.
- Advanced: For targeted or otherwise more complex SQL operations.
- You can now click and drag your cursor to highlight and copy specific rows and columns of the results table, click column headers to sort or highlight the entire column, and access multiple results pages through new pagination.
- We improved the UI and error handling.
- The Collibra AI dropdown menu now has improved organization. We split the available options into two sections:
- You can now authenticate SQL Server connections using an Active Directory MSI client ID. This enhancement, available in both Java 11/Spark 3.4.1 and Java 8/Spark 3.2.2, better enables your team to follow Azure authentication best practices and InfoSec policies. For more information about configuration details, see the Authentication documentation for SQL Server.
- We added an automatic cleaner to clear the
alert_qtable of stale alerts marked asemail_sent = truein the Metastore. - We removed the license key from job logs.
Platform
- By specifying additional projects (AdditionalProjects) in the Connection URL, we now support multiple GCP projects in Google BigQuery connections. You can now specify the project ID in the Connection URL (limited to 1 additional project ID). With this enhancement, you no longer need to append the project ID in the command line.
- When running Google BigQuery jobs via the /v3/jobs/run API, the dataDef updates with the correct
-liband-srclibparameters, and the jobs run successfully. - The names of all out-of-the-box sensitive labels now begin with "OOTB_". This enhancement allows you to define your own sensitive labels with names that were previously reserved, such as PII, PHI, and CUI.
- The following Jobs APIs now return the source rule breaks file containing the SQL statement for breaks jobs in JSON, CSV, or SQL:
- /v3/jobs/{dataset}/{runDate}/breaks/rules
- /v3/jobs/{dataset}/{runDate}/breaks/outliers
- /v3/jobs/{dataset}/{runDate}/breaks/dupes
- /v3/jobs/{dataset}/{runDate}/breaks/shapes
- /v3/jobs/{jobId}/breaks/rules
- /v3/jobs/{jobId}/breaks/outliers
- /v3/jobs/{jobId}/breaks/dupes
- /v3/jobs/{jobId}/breaks/shapes
- We've updated or enhanced the following API endpoints:
- We’ve added job scheduling information to the dataset def to allow you to GET and POST this information along with the rest of the dataset definition.
- We’ve added the outlier weight configs to the dataset def.
- You can now use the GET /v3/datasetDefs/{dataset} API to return a dataset’s meta tags.
- We’ve restructured the JobScheduleDTO to make job scheduling more intuitive when using the /v3/datasetDefs/{dataset} API.
- connectiontype is now connectiontypes
- dataclass is now dataClasses
- datacategory no longer displays
- businessUnitIds is now businessUnitNames
- dataConceptIds is now dataCategoryNames
- sensitivityIds is now sensitivityLabels
- "limit": 0, = The maximum number of records returned
- "offset": 0, = The number of records that should be skipped from the beginning and can be used to return the next ’pages' or number of results after calling the API in sequence
Important If you upgrade to Data Quality & Observability Classic 2024.05 and then roll back to a previous version, you will receive a unique constraint conflict error, as the sensitive label enhancement required a change to the Metastore.
| Method | Endpoint | Controller Name | Description |
|---|---|---|---|
| POST | /v3/rules/{dataset} | rule-api |
After using GET /v3/rules to return all rules in your environment, you can now use POST /v3/rules/{dataset} to migrate them to another environment. When settings are changed and you use POST /v3/rules/{dataset} again, those rules (with the same name) are updated. |
| GET | /v3/datasetDefs/{dataset} | dataset-def-api |
We've made the following enhancements to the GET /v3/datasetDefs/{dataset} API: |
| POST | /v3/datasetDefs/find | dataset-def-api |
We've updated the following parameter names for consistency with the latest Collibra DQ UI: Additionally, this API returns specific filtered arrays of datasetDefs. Parameter descriptions: |
| POST | /v3/datasetDefs | dataset-def-api | You can now use the POST /v3/datasetDefs/{dataset} API to add meta tags to a dataset. |
| DELETE | /v3/datasetDefs | dataset-def-api | When removing a dataset using the DELETE /v3/datasetdef API, you can now successfully rename another dataset to the name of the deleted dataset. |
| POST | /v2/datasetDefs/migrate | controller-dataset |
You can now add a Pullup dataset def to create a dataset record in the Dataset Manager without running the job or setting a job schedule. This is useful when migrating from a source environment to a target environment. Note This API endpoint is supported only in Pullup mode. It is not supported in Pushdown mode. |
| GET | /v2/assignment-q/find-all-paging-datatables | controller-assignment-q | We’ve added an updateTimestampRange parameter to the GET /v2/assignment-q/find-all-paging-datatables API to allow for the filtering of assignments records based on timestamp updates. |
Integration
- We improved the connection mapping when configuring the integration by introducing pagination for tables, columns, and schemas.
- For improved security when sharing data between applications, we have temporarily removed the Score Details attribute from the Collibra Platform integration and the JSON payload.
Fixes
Capabilities
- The Dataset Overview, Findings, Profile, and Rules pages in the latest UI now correctly display the number of rows in your dataset. Previously, the rows displayed correctly in the job logs but did not appear on the aforementioned pages. (ticket #137230, 137979, 140203)
- When using remote file connections with Livy enabled in the latest UI, files with the same name load data content correctly. We fixed an issue where data from the first file persisted in the second file of the same name.
- We fixed an issue where renaming a dataset using the same characters with different casing returned a success message upon saving, but still reflected the old dataset name. For example, an existing dataset renamed "EXAMPLE_DATASET" from "example_dataset" now updates correctly. (ticket #139384)
- When creating jobs on S3 datasets based on data from CSV files with pipe delimited values, the delimiter no longer reverts from Pipe (|) to Comma (,) when you run the job. (ticket #132097)
- We fixed an issue with the Edit Schedule modal on the latest UI where both Enabled and Disabled displayed at once. (ticket #139207)
Platform
- We fixed an issue where the username and password credentials for authenticating Azure Blob Storage connections did not properly save in the Metastore, resulting in job failure at runtime. (ticket #131026, 138844, 140793, 142635,145201)
- When a rule includes an @ symbol in its query without referring to a dataset, for example,
select * from @dataset where column rlike ‘@’, the rule now passes syntax validation and no longer returns an error. (ticket #139670)
Integration
- You can now map columns containing uppercase letters or special characters from Google BigQuery, Amazon Athena, Amazon Redshift, Snowflake, and PostgreSQL datasets created in Data Quality & Observability Classic to column relations in Collibra Platform. (ticket #133280)
- We fixed an issue where integrated datasets did not load correctly on the Dataset Manager page. Instead, a generic error message appeared on the Dataset Manager without loading any datasets. (ticket #136303, 140286)
- We fixed an issue where the dimension cards did not display when using the Quality tab on Column and Rule Asset pages. (ticket #122949)
Pushdown
- We updated some of the backend logic to allow the Archive Break Records option in the Connections modal to disable the Archive Break Records options on the Settings modal on the Explorer page. (ticket #137396)
- We added support for special characters in column names. (ticket #135383)
Latest UI
- We added upper and lower bound columns to the export with details file for Outliers.
- We fixed the ability to clear values in the Sizing step when manually updating job estimation fields during job creation.
- We improved the ability to update configuration settings for specific layers in the job creation process.
- We fixed intermittent errors when loading text and Parquet files in the job creation process.
- We added the correct values to the Day of Month dropdown menu in the Scheduler modal.
Limitations
Platform
- Due to a change to the datashapelimitui admin limit in Data Quality & Observability Classic 2024.04, you might notice significant changes to the number of Shapes marked on the Shapes tab of the Findings page. While this will be fixed in Data Quality & Observability Classic 2024.06, if you observe this issue in your Data Quality & Observability Classic environment, a temporary workaround is to set the datashapelimit admin limit on the Admin Console > Admin Limits page to a significantly higher value, such as 1000. This will allow all Shapes findings to appear on the Shapes tab.
Integration
- With the latest enhancement to column mapping, you can now successfully map columns containing uppercase letters and special characters, but columns containing periods cannot be mapped.
DQ Security
Important A high vulnerability, CVE-2024-2961, was recently reported and is still under analysis by NVD. A fix is not available as of now. However, after investigating this vulnerability internally and confirming that we are impacted, we have removed the vulnerable character set, ISO-2022-CN-EXT, from our images so that it cannot be exploited using the iconv function. Therefore, we are releasing Data Quality & Observability Classic 2024.05 with this known CVE without an available fix, and we have confirmed that Data Quality & Observability Classic 2024.05 is not vulnerable.
Additionally, a new vulnerability, CVE-2024-33599, was recently reported and is still under analysis by NVD. Name Service Cache Daemon (nscd) is a daemon that caches name service lookups, such as hostnames, user and group names, and other information obtained through services like DNS, NIS, and LDAP. Because nscd inherently relies on glibc to provide the necessary system calls, data structures, and functions required for its operation our scanning tool reported this CVE under glibc vulnerabilities. Since this vulnerability is only possible when ncsd is present and nscd is neither enabled nor available in our base image, we consider this vulnerability a false positive that cannot be exploited.
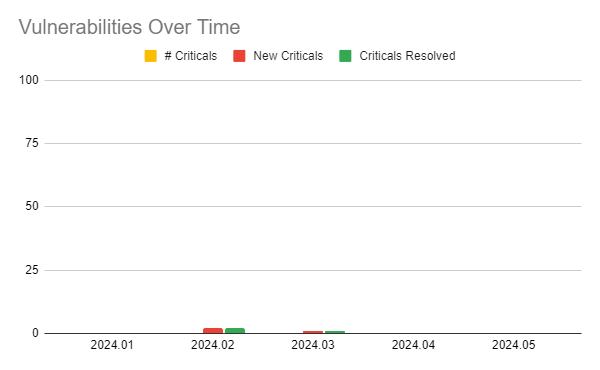
The following image shows a chart of Collibra DQ security vulnerabilities arranged by release version.

The following image shows a table of Collibra DQ security metrics arranged by release version.
Maintenance Updates
2024.05.2
- When editing an existing scheduled dataset and re-running it from Explorer, the job no longer fails with an "Invalid timeslot selected" error. (ticket #149549)
- When using the GET /v3/datasetDefs/{dataset} call to return a dataset with a scheduled run, then update it with the POST /v3/datasetDefs call or modify the name of the dataset in the same POST call, you no longer need to manually remove the
"jobSchedule": {}element and the API calls are successful.