About Data Quality & Observability (cloud)
For information about the self-hosted Data Quality & Observability Classic application, go to Data Quality & Observability Classic.
Data Quality & Observability helps to ensure only reliable, high-quality data exists across your data landscape. Automatic and custom data quality monitoring equips you with detailed data profiling insights, which, when coupled with instant alerting, allows you to identify and take action on data anomalies as soon as they are observed.
Data Quality & Observability provides a comprehensive set of monitoring options for data engineers, analysts, governance roles, and other technical stewards. From basic schema profiling to granular table-level analysis, you can run custom SQL queries and advanced monitoring along an automated schedule for a sophisticated approach to ensuring data quality.
Data Quality & Observability process
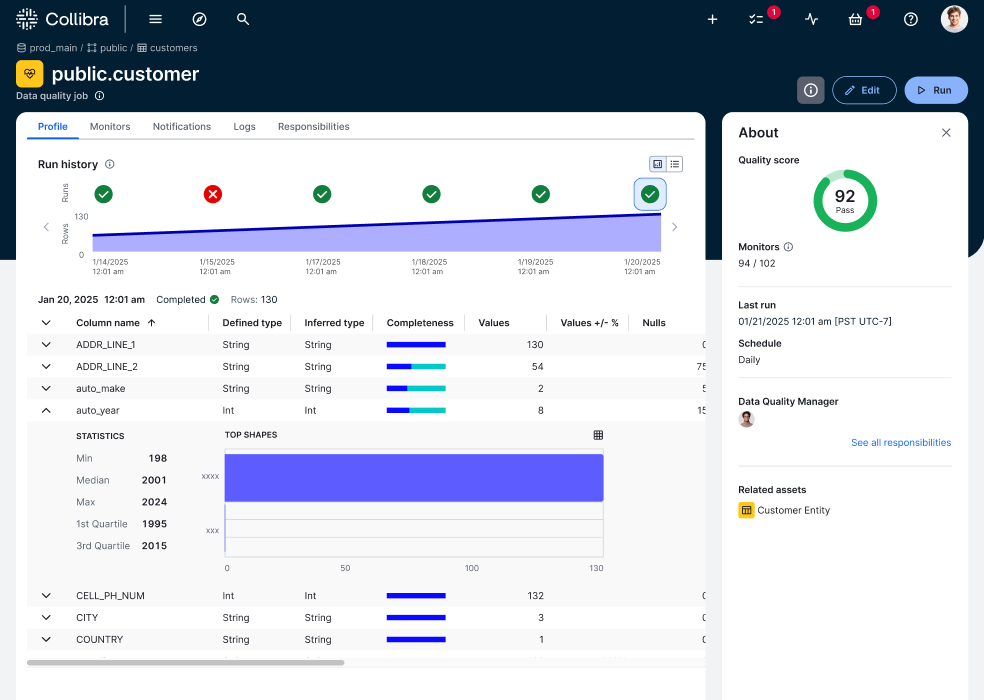
The following image and table show the key processes for maintaining high-quality data with Data Quality & Observability.
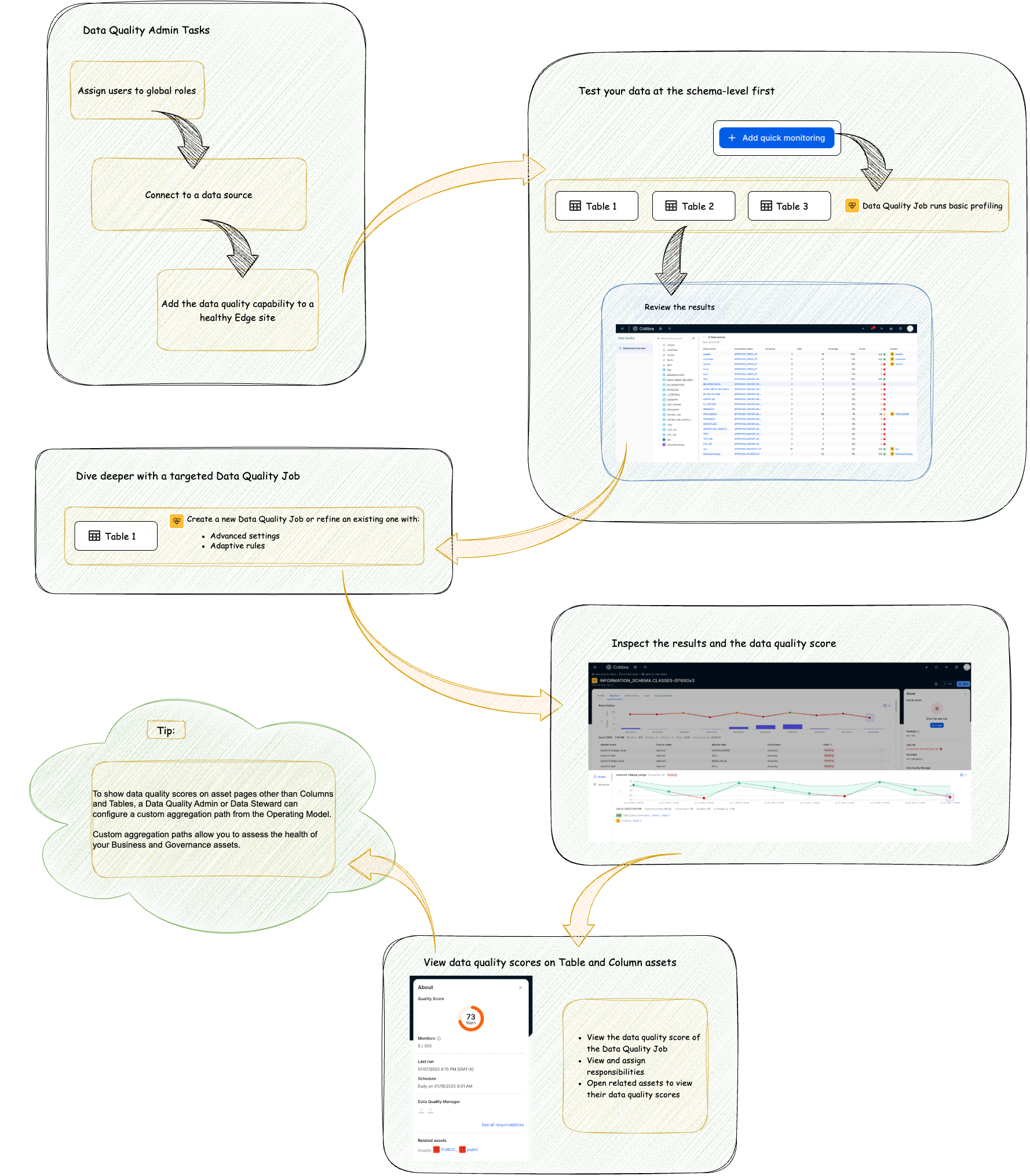
| Process | Task overview | Description |
|---|---|---|
| Prepare Edge |
Data Quality & Observability prioritizes security by relying on Edge. All interactions with your data sources occur through Edge. This means you do not need to change how you expose your databases to Collibra or globally. Before running data quality, a system administrator connects to data sources, adds the required capabilities, and ensures that users have the necessary roles to use Data Quality & Observability. |
|
| Test your data at the schema-level |
using advanced monitoring, use quick monitoring for an immediate impression of the health of your data. Quick monitoring creates basic Data Quality Jobs to instantly apply observability to your schema and, based on your preference, to all or specific tables. Beyond standard data profiling, which includes data type and schema change detection, you can also include row count checks and enable descriptive statistics, such as minimum and maximum values. These statistics are shown in the user interface (UI) for a quick impression of your data. Quick monitoring always generates descriptive statistics, but you control whether Collibra shows them in the UI. This helps you reduce the risk of exposing potentially sensitive data as you begin to check the health of your data. |
|
| Create a Data Quality Job at the table-level |
For in-depth table monitoring, deploy table-level Data Quality Jobs. Data Quality Jobs provide advanced monitoring capabilities and flexibility to automate their run schedules, building on the initial data profile insights gained from quick monitoring. You can configure custom SQL queries to perform targeted checks, providing detailed insights tailored to your business needs. Instant notifications about your Data Quality Job runs keep you informed about important changes in data quality monitoring. This allows you to take immediate action, maintain high-quality trustworthy data, and proactively identify and address potential issues in your data environment. |
|
| View the score |
Data quality scores are automatically shown on Column, Table, Schema, Database, and Database View asset pages. If you want to see data quality scores on other asset pages, such as Business and Governance assets, a system administrator can configure custom aggregation paths to those assets. This allows you to view and monitor the evolution of data quality scores for those assets. You can always access related asset pages through direct links on Data Quality Job pages. You can also assign Data Quality Jobs to members of your organization for regular monitoring and closer inspection of potential data quality issues. Assigning responsibilities to a Data Quality Job provides end-to-end governance and strengthens the trustworthiness of your data. |
Data Quality & Observability and Edge architecture
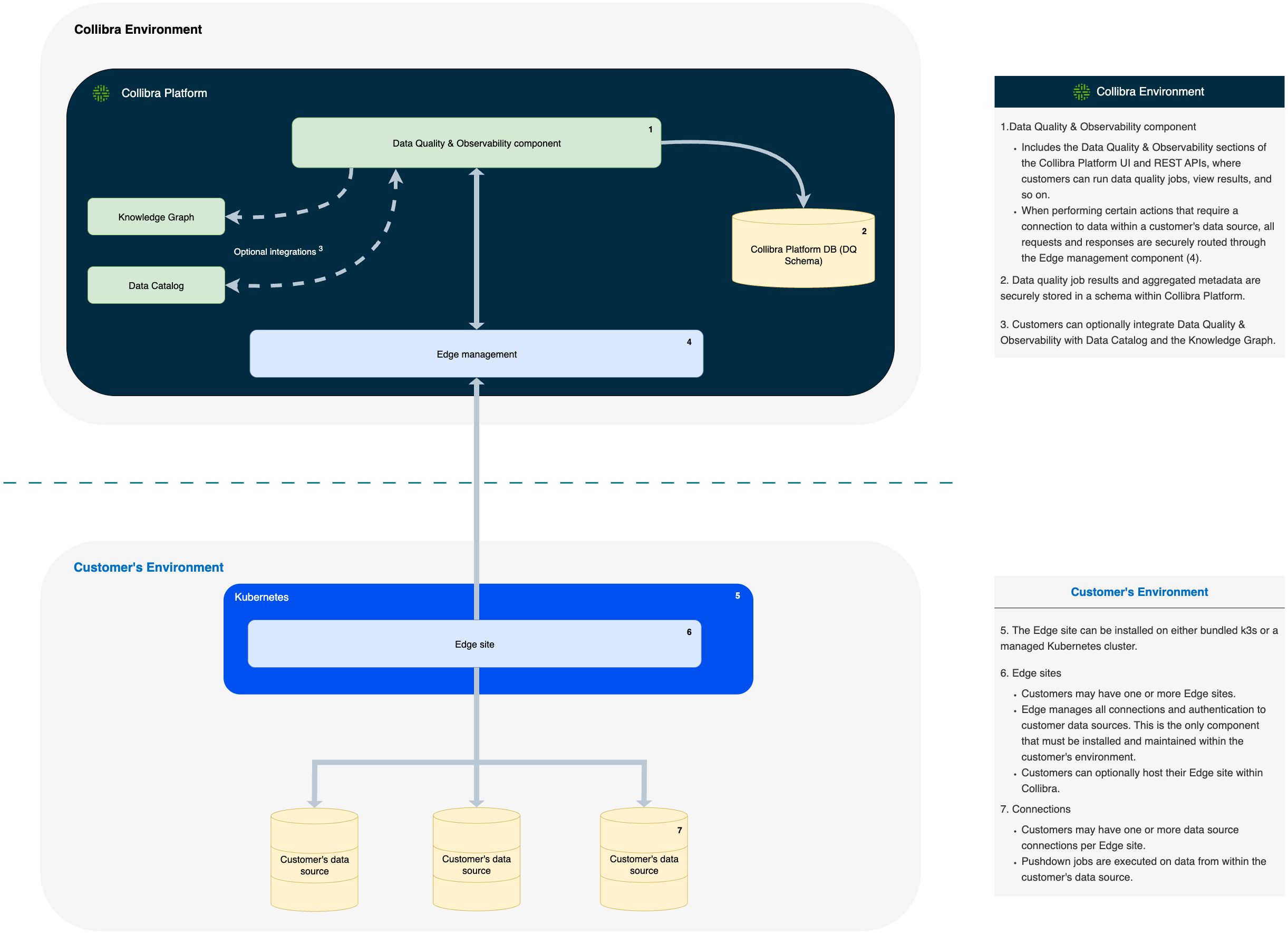
- Data Quality & Observability component
- Includes the Data Quality & Observability sections of the Collibra Platform UI and REST APIs, where customers can run Data Quality Jobs, view results, and so on.
- Data Quality Job results and aggregated metadata are securely stored in a schema within Collibra Platform.
- Customers can optionally integrate Data Quality & Observability with Data Catalog and the Knowledge Graph.
- When performing certain actions that require a connection to data within a customer's data source, all requests and responses are securely routed through the Edge management component.
- The Edge site can be installed on either bundled k3s or a managed Kubernetes cluster.
- Edge sites
- Customers may have one or more Edge sites.
- Edge manages all connections and authentication to customer data sources. This is the only component that must be installed and maintained within the customer's environment.
- Customers can optionally host their Edge site within Collibra.
- Connections
- Customers may have one or more data source connections per Edge site.
- Pushdown jobs are executed on data from within the customer's data source.