This section shows how you can design and build a SQL rule on the Rule Workbench.
Prerequisites
You have:
- ROLE_ADMIN, ROLE_DATASET_RULES, or ROLE_VIEW_DATA
- An existing dataset against which you want to write a rule.
Steps
Select a navigation method from the following tabs.
Tip
If you plan to create a rule with SQL Assistant for Data Quality, ensure you meet the prerequisites detailed on About SQL Assistant for Data Quality and follow the steps on Create a data quality rule with SQL Assistant for Data Quality.
- Click the
 in the sidebar menu, then click Rule Builder. The Dataset Rules page opens.
in the sidebar menu, then click Rule Builder. The Dataset Rules page opens.
- There are two ways to open the Rule Workbench.
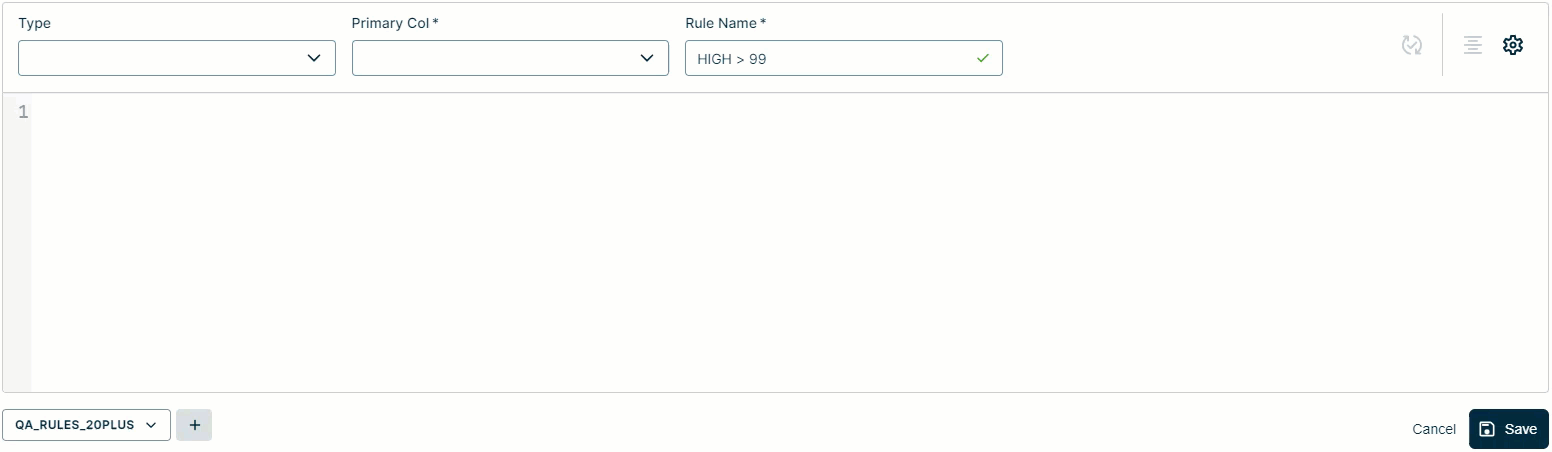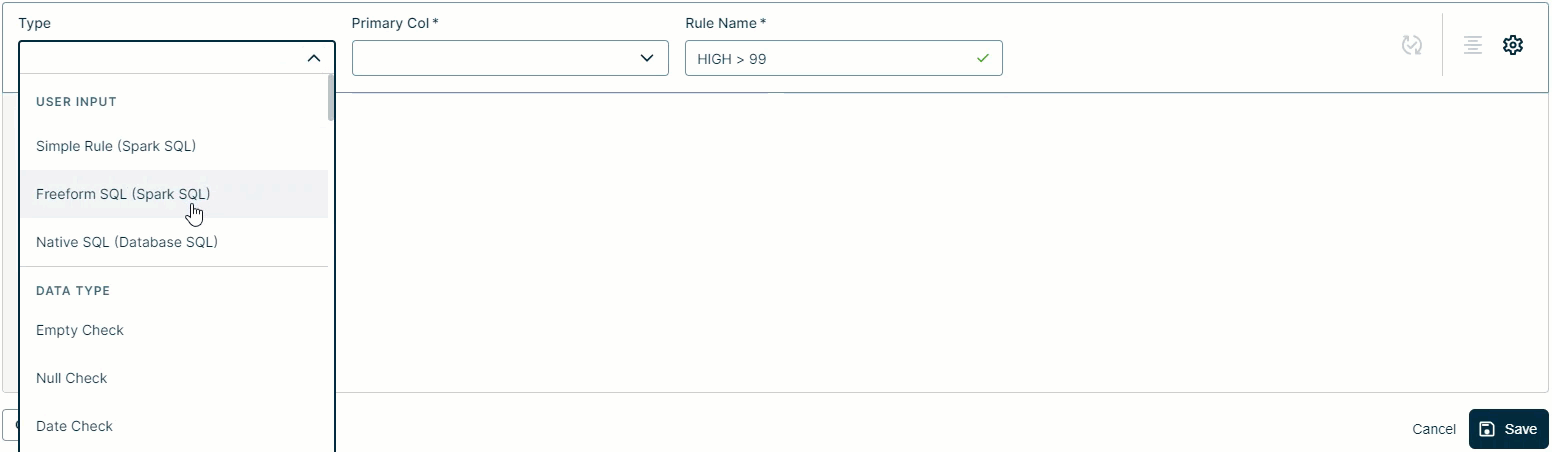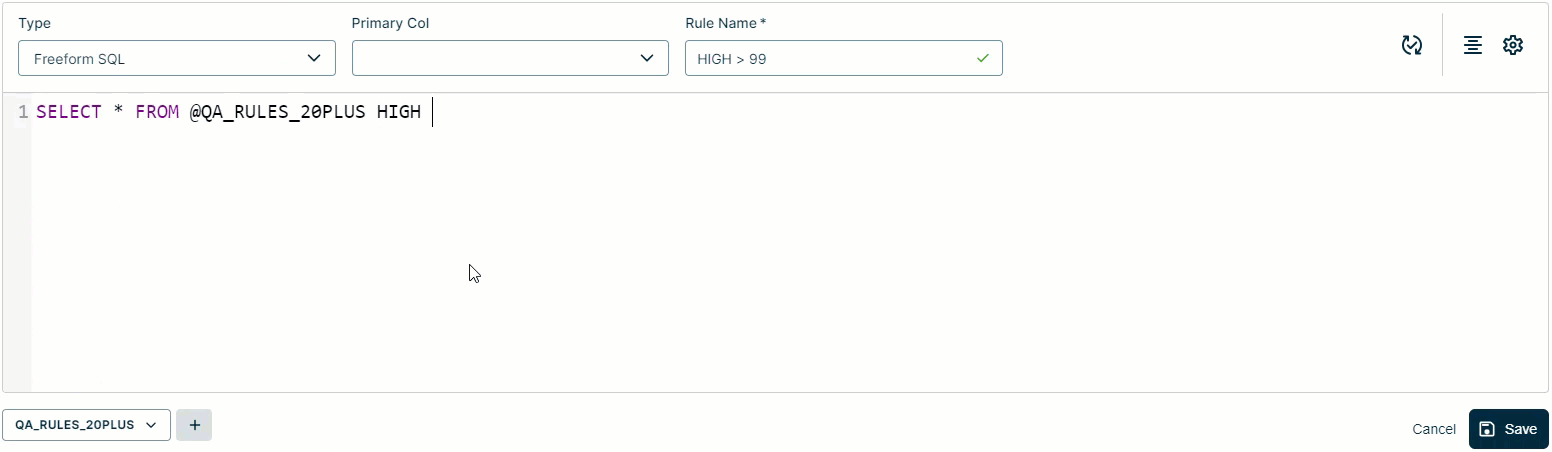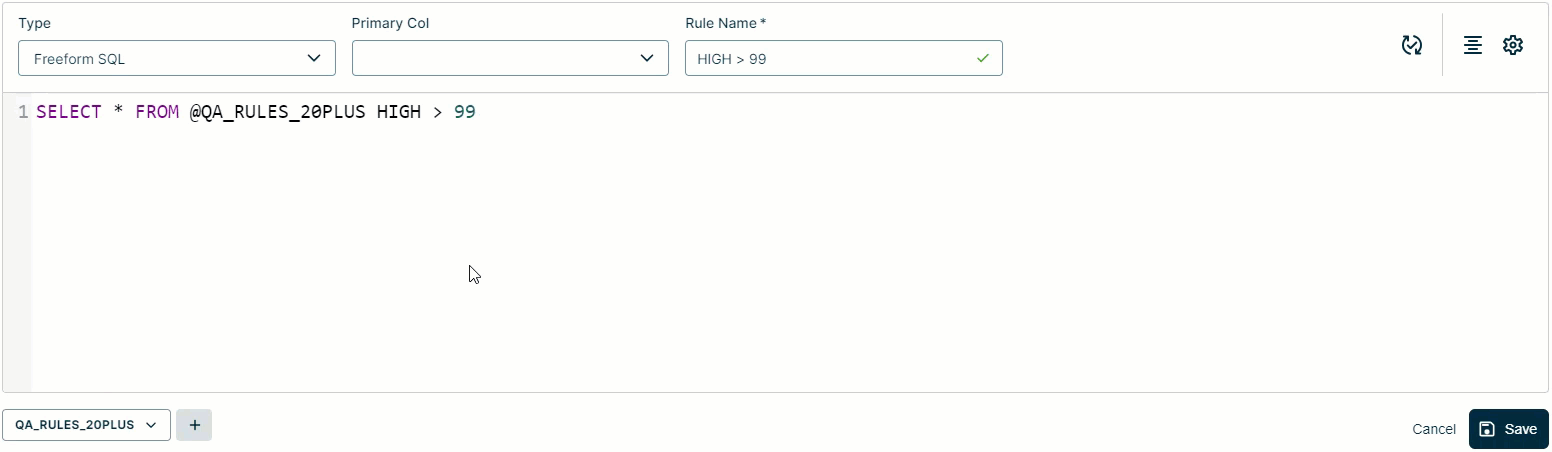
- Select a rule type from the Type drop-down list.
- Enter a name for your rule in the Rule Name input field.
- Select a primary column from the Primary Col drop-down.
- Optionally, click
 to add a secondary dataset.
to add a secondary dataset.- Enter the name of your secondary dataset in the search bar when the Add Secondary Dataset dialog appears, then click Add Secondary Dataset.
If you use snowflake_key_pair authentication for the secondary dataset, then add this to the Spark configuration file in the command line after the -conf parameter:
spark.kubernetes.driverEnv.OWL_SCRATCH_DIR=/tmp/scratch,spark.kubernetes.executorEnv.OWL_SCRATCH_DIR=/tmp/scratch
Important If you edit the rule later, you will need to add the secondary dataset again. Secondary datasets do not persist when a rule is edited. Secondary datasets in the query itself are still referenced when the job is run.
- Write your SQL query. When you select the Freeform rule type, as shown in the GIF below, the Workbench pre-populates the beginning of the query for you. For example,
SELECT * FROM @<dataset name>. As you type, the Workbench provides a suggested options with common SQL operators and column names relative to your primary and secondary datasets. - If your SQL query contains columns with special characters, you need to escape them with backticks
` `to ensure the rule runs successfully. For example,`col_à` IS NOT NULLandSELECT * FROM example_table where `col_à` is not null. This is due to a Spark limitation which causes a syntax parsing error when the DQ Job runs. - For a complete list of Spark SQL operators and functions available for use on SQLG and SQLF rule types, see the official Spark documentation.
- If your SQL query is very lengthy, there is an increased likelihood that it may fail to validate or save. To mitigate this issue, we recommend:
- Leveraging an
INclause to break down queries into small, more manageable rules. - Using Pretty Print formatting, which improves readability and reduces the risk of parsing or processing issues. Proper indentation and line breaks make it easier to review, debug, and maintain complex rules.
- Using alias names consistently to improve rule processing and stability, particularly for rules that include functions or have complex structures.
- Leveraging an
- Optionally, add a filter query in the Filter input field.
- Click
 Validate to validate your expression.
Validate to validate your expression. - Optionally, click
 to format your SQL query in a more readable layout.
to format your SQL query in a more readable layout. - Click Save to apply your rule to your dataset.
| Option | Description |
|---|---|
| User Input | User Input rules are custom SQL statements that can be either short or long form, depending on the complexity. |
|
Simple Rule (SQLG)
|
Simple rules are SQL statements that use just the condition and primary column name. For example, Simple Rules use Spark SQL syntax. |
|
Freeform SQL (SQLF)
|
Freeform rules are complete SQL statements that are commonly used when more complex SQL rules are necessary. Freeform Rules can include multiple conditions, table joins, common table expressions (CTEs), and window statements, among other operations. Freeform Rules use Spark SQL syntax. See Supported SQL functions for Pullup rules for more information on the supported and unsupported SQL functions. Note As of version 2025.05, you can save rules that contain long query strings. |
|
Native SQL
|
Native rules use SQL statements with functions or expressions that may be specific to the underlying connection or database (Database SQL). For example, a Native SQL rule written on a dataset whose data resides in Snowflake uses the SQL query syntax native to Snowflake. Remote files are not eligible for Native SQL rules. Note All Pushdown rules use the SQL dialect native to the specific database of your source data. Because all Pushdown rules technically use Native (Database) SQL, the Native SQL option is not available for Pushdown jobs on the Rule Workbench. To check whether a rule conforms to the SQL dialect of the source database, click Note As of version 2025.05, you can save rules that contain long query strings. |
| Data Type | Data Type rules check for nulls, empty values, or specific data types. |
|
Empty Check
|
Checks whether the target column has empty values or not. |
|
Null Check
|
Checks whether the target column has NULL values or not. |
|
Date Check
|
Checks whether the target column has only DATE values or not. |
|
Int Check
|
Checks whether the target column has only integer values or not. |
|
Double Check
|
Checks whether the target column has only DOUBLE values or not. |
|
String Check
|
Checks whether the target column has only STRING values or not. |
|
Mixed Type Check
|
Checks the dataType of the field. Note Mixed datatype rules are not supported in Pushdown. |
| Data Class | See the Data Class page for a list of out-of-the-box Data Class rules. |
| Template | See the Template page for a list of out-of-the-box Template rules. |
Important Rule names cannot contain spaces.
Note A primary column is required only when the MANDATORY_PRIMARY_RULE_COLUMN application configuration setting is set to TRUE or if you use a Data Type, Data Class, or Template rule.
Note removes tab spaces from rules, which are not supported characters. If you used tabs to format your rules, be sure to click before saving.
Tip
If you plan to create a rule with SQL Assistant for Data Quality, ensure you meet the prerequisites detailed on About SQL Assistant for Data Quality and follow the steps on Create a data quality rule with SQL Assistant for Data Quality.
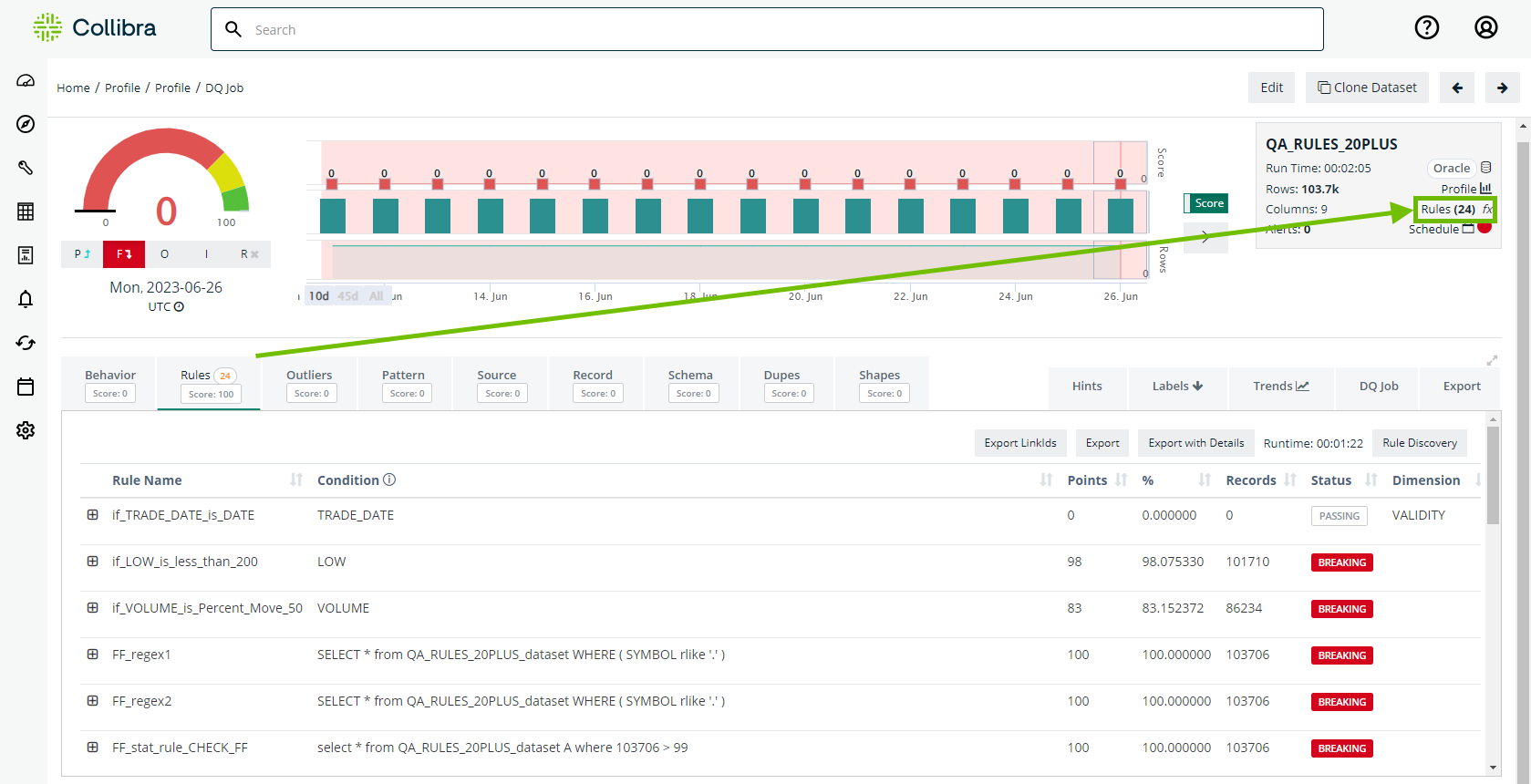
- On the upper-right corner of the Findings page, click the Rules link in the metadata box. The Dataset Rules page opens.
- There are two ways to open the Rule Workbench.
- Select a rule type from the Type drop-down list.
- Enter a name for your rule in the Rule Name input field.
- Select a primary column from the Primary Col drop-down list.
- Optionally, click to add a secondary dataset.
- Enter the name of your secondary dataset in the search bar when the Add Secondary Dataset dialog appears, then click Add Secondary Dataset.
Important If you edit the rule later, you will need to add the secondary dataset again. Secondary datasets do not persist when a rule is edited. Secondary datasets in the query itself are still referenced when the job is run.
- Write your SQL query. When you select the Freeform rule type, as shown in the GIF below, the Workbench pre-populates the beginning of the query for you. For example,
SELECT * FROM @<dataset name>. As you type, the Workbench provides a suggested options with common SQL operators and column names relative to your primary and secondary datasets. - If your SQL query contains columns with special characters, you need to escape them with backticks
` `to ensure the rule runs successfully. For example,`col_à` IS NOT NULLandSELECT * FROM example_table where `col_à` is not null. This is due to a Spark limitation which causes a syntax parsing error when the DQ Job runs. - For a complete list of Spark SQL operators and functions available for use on SQLG and SQLF rule types, see the official Spark documentation.
- Optionally, add a filter query in the Filter input field.
- Click Validate to validate your expression.
- Optionally, click to format your SQL query in a more readable layout.
- Click Save to apply your rule to your dataset.
| Option | Description |
|---|---|
| User Input | User Input rules are custom SQL statements that can be either short or long form, depending on the complexity. |
|
Simple Rule (SQLG)
|
Simple rules are SQL statements that use just the condition and primary column name. For example, Simple Rules use Spark SQL syntax. |
|
Freeform SQL (SQLF)
|
Freeform rules are complete SQL statements that are commonly used when more complex SQL rules are necessary. Freeform Rules can include multiple conditions, table joins, common table expressions (CTEs), and window statements, among other operations. Freeform Rules use Spark SQL syntax. See Supported SQL functions for Pullup rules for more information on the supported and unsupported SQL functions. Note As of version 2025.05, you can save rules that contain long query strings. |
|
Native SQL
|
Native rules use SQL statements with functions or expressions that may be specific to the underlying connection or database (Database SQL). For example, a Native SQL rule written on a dataset whose data resides in Snowflake uses the SQL query syntax native to Snowflake. Remote files are not eligible for Native SQL rules. Note All Pushdown rules use the SQL dialect native to the specific database of your source data. Because all Pushdown rules technically use Native (Database) SQL, the Native SQL option is not available for Pushdown jobs on the Rule Workbench. To check whether a rule conforms to the SQL dialect of the source database, click Note As of version 2025.05, you can save rules that contain long query strings. |
| Data Type | Data Type rules check for nulls, empty values, or specific data types. |
|
Empty Check
|
Checks whether the target column has empty values or not. |
|
Null Check
|
Checks whether the target column has NULL values or not. |
|
Date Check
|
Checks whether the target column has only DATE values or not. |
|
Int Check
|
Checks whether the target column has only integer values or not. |
|
Double Check
|
Checks whether the target column has only DOUBLE values or not. |
|
String Check
|
Checks whether the target column has only STRING values or not. |
|
Mixed Type Check
|
Checks the dataType of the field. Note Mixed datatype rules are not supported in Pushdown. |
| Data Class | See the Data Class page for a list of out-of-the-box Data Class rules. |
| Template | See the Template page for a list of out-of-the-box Template rules. |
Important Rule names cannot contain spaces.
Note A primary column is required only when the MANDATORY_PRIMARY_RULE_COLUMN application configuration setting is set to TRUE or if you use a Data Type, Data Class, or Template rule.
Note If your SQL query is very lengthy, there is an increased likelihood that it may fail to validate or save. To mitigate this issue, we recommend breaking down such queries into small, more manageable rules. A possible way of achieving this is by leveraging an IN clause.
Note removes tab spaces from rules, which are not supported characters. If you used tabs to format your rules, be sure to click before saving.
Configuring Rule Details
To configure rule details, click the ![]() in the upper-right corner of the Workbench to open the Rule Details modal.
in the upper-right corner of the Workbench to open the Rule Details modal.
The following table shows the settings when you set up a rule in the Rule Workbench.
| Setting | Description | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DQ Dimension |
Associate your rule with a DQ Dimension, as shown in the following table. This can be especially useful when you use the Collibra Platform integration and custom reporting. This is required if the MANDATORY_RULE_DIMENSION is set to
Note Tagging rules with custom dimensions in the Metastore is not supported. |
||||||||||||||
| Category | You can create and apply custom categories to your rule to group similar rules together. For example, you can create categories for "Rules for missing data" or "Rules to identify format issues". | ||||||||||||||
| Description | Provide a detailed description of your rule. | ||||||||||||||
| Purpose |
Provide details about Collibra Platform assets associated with your rule in Data Quality & Observability Classic. This allows you to see which assets should relate to your Data Quality Rule asset upon integration. Note A purpose is required only when the MANDATORY_RULE_PURPOSE application configuration setting is set to TRUE. |
||||||||||||||
| Preview Limit (Rows) |
The number of available rows to preview when you drill into a rule record. Set a value between 0-500 records. The default value is 6 records. Note Rule Break Preview is only supported for Freeform and Simple rules. Tip Because jobs and rules can accumulate quickly, setting a high number of preview records may slow down the Metastore and cause it to crash. Set the Preview Limit to the minimum required for your use case. |
||||||||||||||
| Run Time Limit (Minutes) | The maximum number of minutes any rule associated with a dataset can take to process before it times out and proceeds to the next activity in the job. If you increase this value to one greater than the previous maximum Run Time Limit of any rule associated with your dataset, it becomes the new maximum timeout limit. | ||||||||||||||
| Score |
Provides three options, or presets, for calculating the rules score: Low, Medium, and High. Select an option to automatically populate the Points field and Percentage field (if applicable) with predefined values. For more information, go to Understanding the rules score. |
||||||||||||||
| Scoring Type |
Determines the methodology used to calculate the rules score: Percent or Absolute. For more information, go to Understanding the rules score. |
||||||||||||||
| Points |
A value between 0-100, representing the number of points deducted from the total quality score when a record violates your rule. For more information, go to Understanding the rules score. |
||||||||||||||
| Percent |
When you use the Percent scoring type, this can be a value between 0-100. This represents the ratio of the total number of breaking records over the total number of rows. For more information, go to Understanding the rules score. |
||||||||||||||
| Tolerance |
Specifies the tolerance threshold as a percentage. For more information, go to Understanding the rules score. |
||||||||||||||
| Rule Status | The Active option is selected by default, indicating the rule is active. To deactivate the rule, uncheck this option. |
Managing a Livy Session
You can preview the columns in your dataset to help you create SQL queries for rules on Pullup jobs. To do this, ensure that you allocate ample resources for Livy to run efficiently. Livy starts when you click Run Result Preview and has 1 core, 1 GB of memory, and 1 worker by default.
For large datasets that require increased processing resources, you may need to modify your Livy session to improve the loading time of your Result Preview. When you use Result Preview, there is a 500-row limit on the preview, regardless of the number of rows are in the results of your query.
Note To view the preview data, you must have the role_data_preview security role.
- Click Manage Session.
The Manage Livy Session modal appears. - Enter the required information.
- Choose whether to acknowledge that all cached preview data will be lost when you update your Livy session.
- Click Update.
| Setting | Description |
|---|---|
| Cores | The number of executor cores for Spark processing. The minimum value is 1. |
| Memory | The amount of memory allocated for Spark processing. Allocate at least 1 GB of memory per Livy pod. |
| Workers |
The number of executors available in your Livy session. The minimum value is 1. When you increase the number of workers, an additional Livy session is created for each additional worker you specify. For example, if you increase your workers from 1 to 3, then 2 additional Livy sessions are created for a total of 3. |
Tip Adjust the Livy resources based on the number of rows included in your query. For columns with a large amount of rows, you may find that you need to increase the memory and workers.
Important To update your Livy session, you must select this option.
Note Livy is not required to use the Result Preview feature for Pushdown.
Working with COUNT and GROUP BY
Be careful when using COUNT and GROUP BY in Freeform SQL and Native SQL rules, because they may create unexpected or unintended results. For best results, keep in mind the following points:
- COUNT. Returns the number of rows that meet the specified criteria. If used on its own, without additional operators and functions, COUNT will create a breaking rule by default.
- GROUP BY. Does not function when used on its own. GROUP BY must be used as part of a group or aggregate function (SUM, COUNT, etc.).
A rule passes when it does not find any rows that meet a specified criteria, and it breaks when it finds rows that need a customer's attention. To create rules with this behavior, include WHERE and/or HAVING in the query. For example, you can use HAVING with both COUNT with GROUP BY to create the following query:
SELECT column_A, COUNT(column_A)
FROM table_1
WHERE column_B = value_X
GROUP BY column_A
HAVING COUNT(column_A) > number_YSupported SQL functions for Pullup rules
The following list shows the supported and unsupported functions for pattern matching in Pullup rules. Use only the supported functions when creating Freeform rules, and validate the syntax afterward.
Supported functions
-
LIKE
-
RLIKE
-
REGEXP
-
REGEXP_LIKE
Unsupported functions
-
Other variations of REGEXP, such as REGEXP_COUNTor REGEXP_REPLACE
-
QUALIFY
-
DATEADD
-
TRANSLATE
-
ROUND
-
FLOOR
Known limitations
-
An error can occur when you write a rule using REGEXP. To resolve this issue, use RLIKE instead.
-
The Result Preview does not show columns with alias names.