The rule filter option on the Rule Workbench allows you to narrow the scope of your SQL query by adding a second query definition to your data quality rule limiting the total number of rows included in the rule score calculation.
In this topic
Prerequisites
You have:
- ROLE_ADMIN, ROLE_DATASET_RULES, or ROLE_VIEW_DATA
- A user with ROLE_ADMIN has set the RULE_FILTER setting to TRUE on the Application Configuration Settings page.
- An existing dataset against which you want to write a rule.
Using a filter query
Rule scores are always based on the total number of rows in your dataset, which means irrelevant records are often included in your rule. When these extraneous records are not filtered out of your SQL query, you may encounter unintended skew to the results of your rule score. By applying a filter query, you can limit the total number of rows that are considered when Data Quality & Observability Classic calculates the rule score, improving the relevance of the rule results.
Using a filter can also eliminate the need to create additional duplicate datasets for each rule that requires a different filter. In addition to reducing the amount of time it takes to set up these synthetic filters, the usage of filter queries on the Rule Workbench reduce the cost and computational waste from duplicate profiling.
By defining the SQL for the subset of relevant records (filter) and the invalid conditions (rule) independently, you can increase the visibility on the ratio between them.
Data steward use case
Suppose you are a data steward whose organization maintains a table containing massive amounts of data about its operations in different regions of the world. Each region has a data steward responsible for monitoring the data therein, and your region is Asia.
Previously, to isolate the most relevant data, a data steward would need to create a new dataset containing only the data of a given region. While this technically works, it is not an optimal approach to separating data, because it introduces unnecessary operational cost and can be more cumbersome to maintain in the long term.
Now, you can rely on a single dataset as the source of truth, where, instead of creating new datasets with rules set up for each region, you can create filter queries on top of the same rule query to only include results for the Americas, Asia, and so on.
In the below screenshot, several rules are set up to query the same dataset. The first 3 rules have filter queries to filter the exact data relevant to each data steward's region. An asterisk displays to the right of the value in the Total Records column to denote that the rule in that row has a filter query.
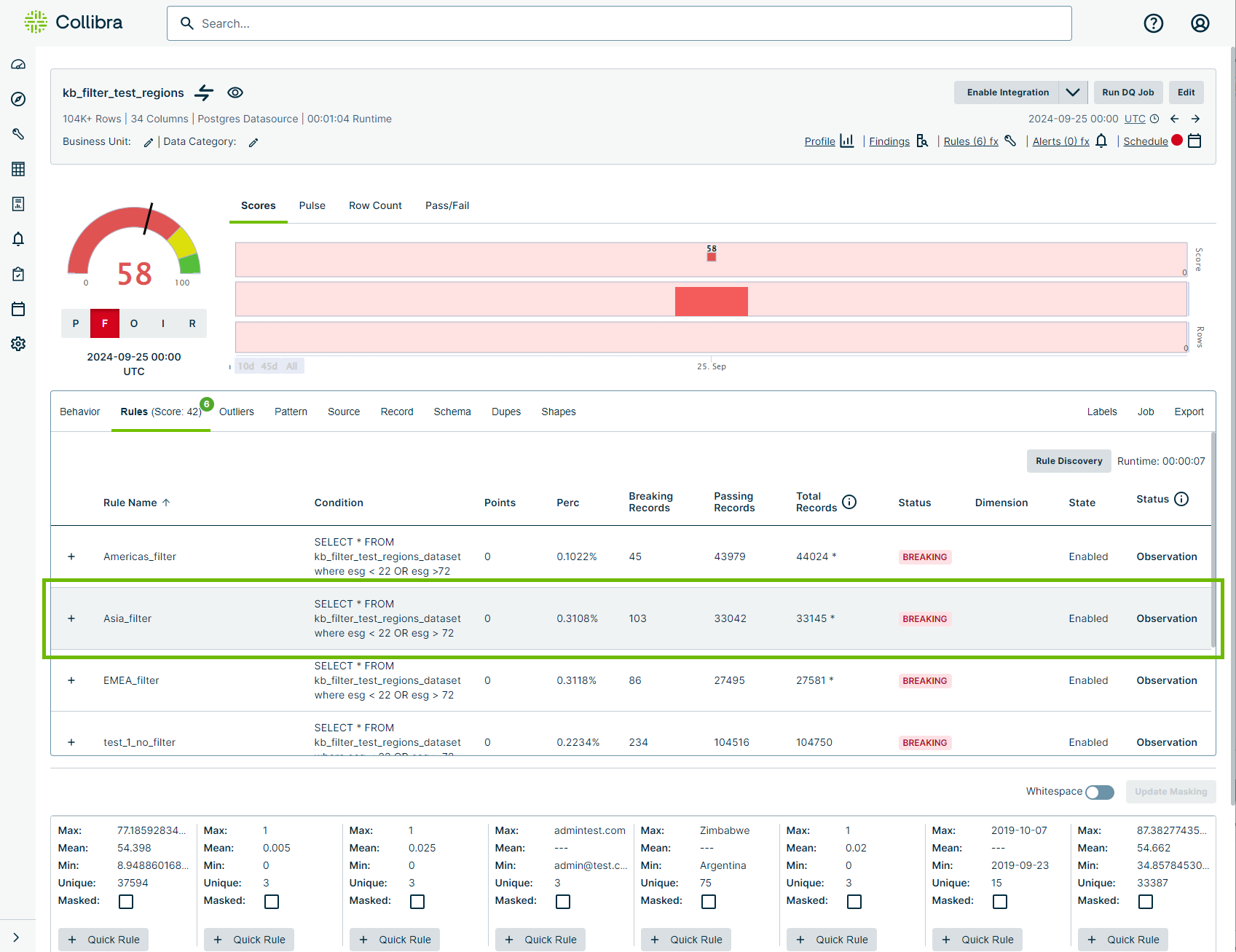
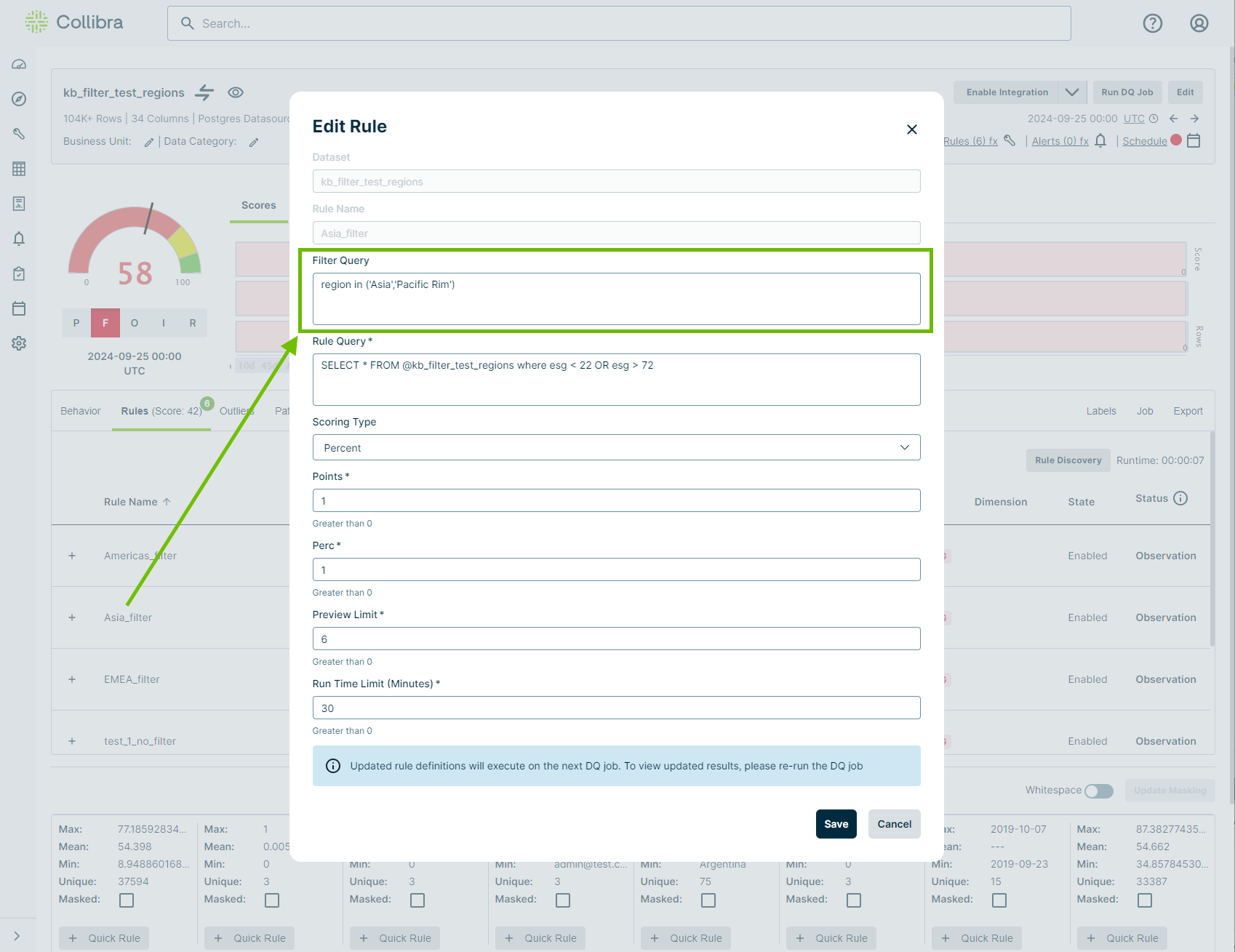
In the below example, only data for your region, Asia (which includes the Pacific Rim), is being queried with the addition of the filter query, region in ('Asia','Pacific Rim').
After the results of freeform or simple rules with filter queries separating each one into regions are available on the Findings page, you can view and export their break records when a column in the dataset is assigned as the link ID column. From the ability to pare down the results of your rules with a filter query to the exportation of their break records, you now have more complete end-to-end control over the management of your data region.
Filter query scoring impact
The inclusion or exclusion of a filter query impacts the rule score on the Findings page by changing the denominator to reflect the number of filtered or unfiltered rows.
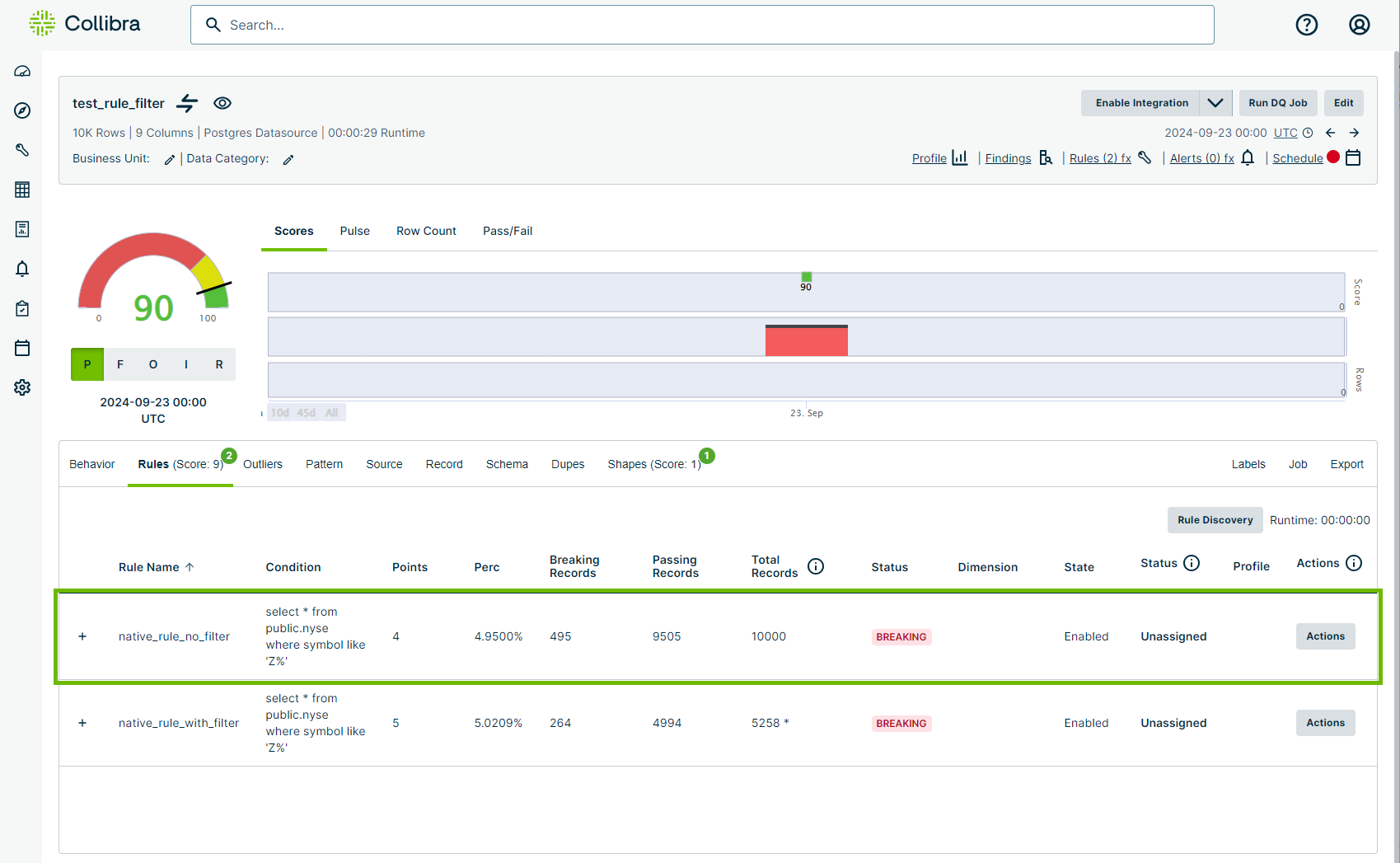
In the following example based on a New York Stock Exchange dataset, the rule "native_rule_filter" uses the rule query select * from public.nyse where symbol like 'Z%' to examine all of its 10,000 rows for records in the "symbol" column beginning with the letter "Z." Without a filter query this returns 495 breaking records when the DQ Job runs. 1 point is deducted for each percentage point, which is the total number of breaking records (495) over the total number of rows (10,000). In this case, because the rule queries the entire dataset, the percentage of rule breaks is 4.95% for a total of 4 points deducted from the overall data quality score.
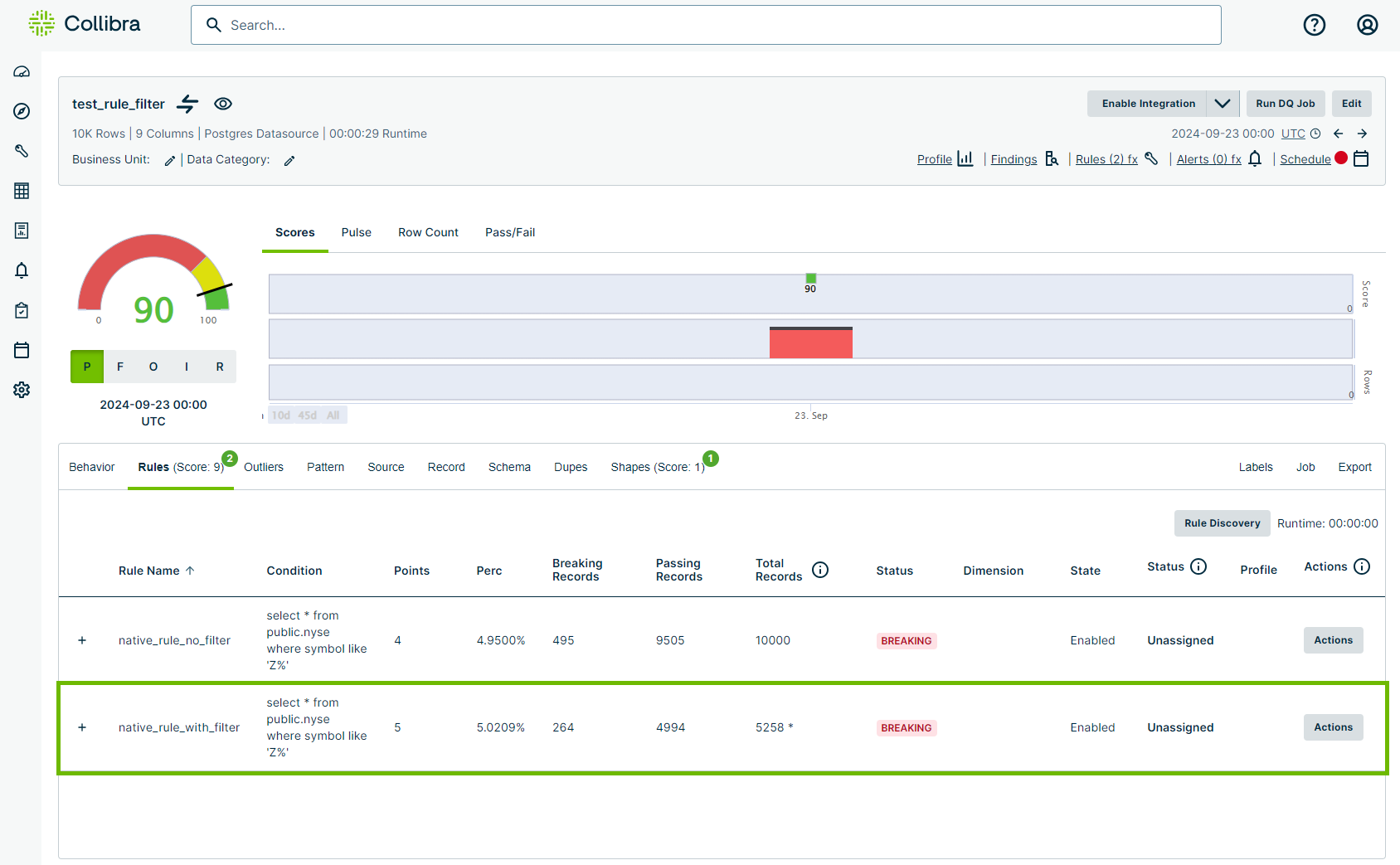
The same New York Stock Exchange dataset uses an identical rule query in the rule "native_rule_with_filter" but applies the filter query low > 25 on top of it to exclude all records that do not also contain values greater than 25 in the "low" column. This results in 5,258 total records and 264 breaking records for 5.02% breaking and 5 points deducted from the overall data quality score.
Adding a rule filter
- Click the Rules link on the metadata bar on a dataset-level page or open the Dataset Rules page of a dataset by clicking the
 in the sidebar menu, then clicking Rule Builder. The Dataset Rules page opens.
in the sidebar menu, then clicking Rule Builder. The Dataset Rules page opens.
- Follow the steps to add a rule from the Rule Workbench. Show Rule Workbench steps
- There are two ways to open the Rule Workbench.
- Select a rule type from the Type dropdown menu.
- Enter a name for your rule in the Rule Name input field.
- Select a primary column from the Primary Col dropdown menu.
- Optionally click
 to add a secondary dataset.
to add a secondary dataset.- Enter the name of your secondary dataset in the search bar when the Add Secondary Dataset dialog appears, then click Add Secondary Dataset.
- Enter your SQL query in the Rule (required) input field.
- In the Filter (optional) input field, enter a filter query in the format of a simple query, such as
symbol is not nullorlow > 25. - The filter query should only contain conditions and predicates found after the
whereclause in a SQL query. For example, the correct syntax of a filter query for results in the "low" column of a NYSE dataset might look likelow > 25, neverselect * from public.nyse where low > 25. - The most relevant results return when the rule query is based solely on data in the source query.
- Click Save to apply your rule to your dataset.
- Rerun your DQ Job. The results of your run are available on the Rules tab of the Findings page.
Important Rule names cannot contain spaces.
Note Primary Column is only required when you use a Data Type, Data Class, or Template rule.

Note Rules that contain a filter query are marked with an asterisk to the right of the Total Records value. For example, 5258*.
Limitations
- You cannot use @t1 rules in the filter query.
- SQL Assistant for Data Quality is not available for the filter query.
- When the rule refers to a dataset that is different from the origination dataset, the rule results reflect the rule filter query combination from the dataset referenced in the filter query, not the origination dataset.
- The filter query does not support LIMIT clauses.