Steps: Integrate an Amazon S3 file system via Edge
The Amazon S3 file system integration allows for the registration of an Amazon S3 file system as a data source and synchronization of Amazon S3 metadata in Collibra, representing the full Amazon S3 file structure in Collibra.
Follow the steps below to integrate an Amazon S3 file system via Edge.
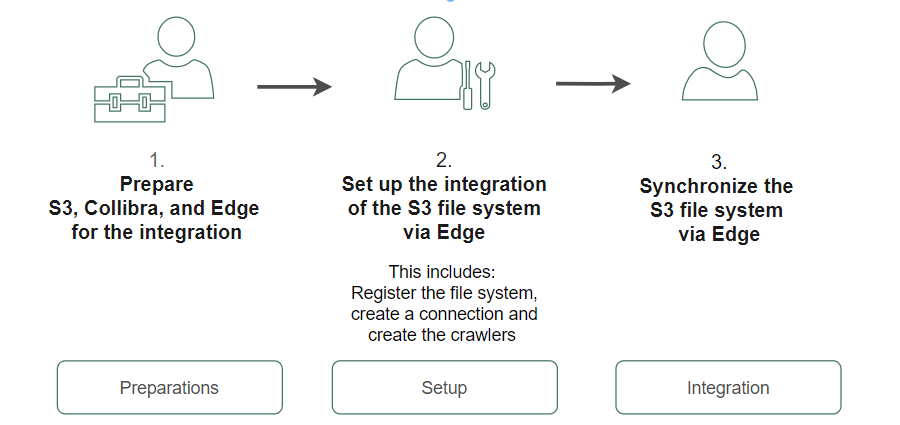
Steps
|
No. |
Step |
Description |
Results |
|---|---|---|---|
|
1 |
Prepare S3 file system for integration via Edge | Prepares the S3 file system for integration in Data Catalog. | You have access keys that you can use during the integration. |
|
2 |
Restrict AWS regions | Ensures that the regions to collect data from are known. | Collibra knows which regions to look at. |
| 3 | Prepare your Edge site |
Prepares your Edge site for the integration of S3. |
Your Edge site is ready to integrate Amazon S3 via Edge. |
|
4 |
Register the Amazon S3 file system | Creates the initial structure for the integration. |
|
| 5 | Connect a file system asset to Amazon S3 | Links the registered S3 file system to an Edge capability to connect to Amazon S3. | The connection is available. |
| 6 |
If needed, create crawlers. |
Creates crawlers to find and ingest the Amazon S3 metadata. | The crawlers to collect metadata from Amazon S3 are available. |
| 7 | Synchronize Amazon S3 |
Runs the crawlers to ingest the metadata of Amazon S3. By default, the assets are shown in a plain list, but you can create a hierarchy to show it in a tree structure. |
The metadata of Amazon S3 is available in Collibra. For more information, go to Integrated Amazon S33 data. |