After you have synchronized the data, the integration of the Amazon S3 file system is completed.
Synchronization results
After synchronization, the resulting assets are in the domain specified in the crawler. By default, the assets get the Candidate status.
Warning Do not move the assets to another domain. Doing so may lead to errors during future synchronizations. This is a known limitation.
By default, the assets are shown in a plain list, but you can enable a multi-path hierarchy to show it in a tree structure. For the best result, we recommend that you use the following relations:
- Storage Container contains Storage Container
- Directory contains Directory
- Storage Container contains File
- Directory contains File Group
- File contains Table
- File Group contains Table
- Table contains Column
The following images shows the resulting hierarchical table.
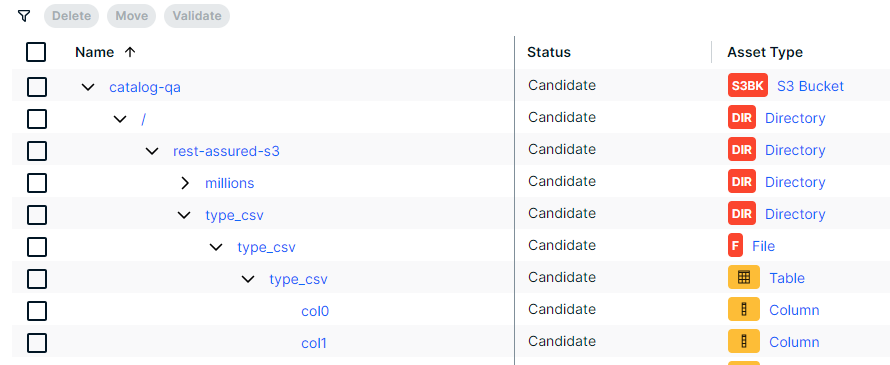
Note In case of a partial synchronization caused by a temporary communication issue, the status of the assets that cannot be synchronized is set to Missing from source. During the next fully successful synchronization, the assets are removed or their previous status is restored, depending on their actual status in the source system.
Synchronized metadata per asset type
This table shows the metadata for each Amazon S3 asset type.
|
Asset type |
Synchronized metadata |
Public ID |
|---|---|---|
| S3 Bucket |
URL |
Url |
|
Location |
Location | |
| File Storage contains/ is part of Storage Container | FileContainerContainsFileContainer | |
| Directory |
URL |
Url |
| Storage Container contains/ is part of Storage Container | FileContainerContainsFileContainer | |
| Directory contains/ is part of Directory | DirectoryContainsDirectory | |
| File Group | URL | Url |
| File Type | FileType | |
| Document Size | DocumentSize | |
| Number of Files | NumberOfFiles | |
| Directory contains/ is part of File Group | DirectoryContainsFileGroup | |
| File | URL | Url |
| File Type | FileType | |
| Document Size | DocumentSize | |
| Storage Container contains/ contained in File | FileContainerContainsFile | |
| Table | Glue database name | GlueDatabaseName |
| Glue table name | GlueTableName | |
|
Description from source (available only if you integrate via Edge) Note
You cannot integrate the descriptions from source directly. If you want to integrate descriptions, and you have not synchronized S3 before:
If you ran the S3 synchronization via Edge before running it via a crawler defined in Collibra:
|
DescriptionFromSourceSystem | |
| Table type (available only if you integrate via Edge) | TableType | |
| File contains/ is part of Table | FileContainsTable | |
| File Group contains/ is part of Table | FileGroupContainsTable | |
| Column | Technical Data Type | TechnicalDataType |
|
Column Position (available only if you integrate via Edge) Note The column position is not included when columns in the same table have identical names. |
ColumnPosition | |
|
Description from source (available only if you integrate via Edge) Note
You can't integrate the descriptions from source directly. If you want to integrate descriptions, and you have not synchronized S3 before:
If you ran the S3 synchronization via Edge before running it via a crawler defined in Collibra:
|
DescriptionFromSourceSystem | |
| Column is part of/ contains Table | ColumnIsPartOfTable |