Warning Jobserver and all related Jobserver integrations reached their End of Life in commercial environments in October, 2024. In Collibra Platform for Government and Collibra Platform Self-Hosted environments, they will reach their End of Life on May 30, 2027. For information on the integration of S3 via Edge, go to Steps: Integrate an Amazon S3 file system via Edge.
A crawler is an automated script that ingests data from Amazon S3 to Data Catalog.
You can create, edit and delete crawlers in Collibra Platform. When you synchronize Amazon S3, the crawlers are created in AWS Glue and executed. Each crawler crawls a location in Amazon S3 based on its include path. You can make an S3 bucket accessible for crawlers from the same or other AWS accounts than the account in which the S3 bucket is located. The results are stored in one AWS Glue database per domain assigned to one or more crawlers. Those databases are ingested in Data Catalog in the form of assets, attributes, and relations. The databases are stored in AWS Glue until the next synchronization. At that moment, they are deleted and re-created. The crawlers in AWS Glue are deleted immediately after as the synchronization is finished.
- By default, AWS Glue allows up to 25 crawlers per account. For more information, go to the AWS Glue documentation. This has consequences for Collibra:
- If you created crawlers in AWS Glue directly, Collibra can create fewer crawlers for synchronization.
- Because Collibra creates the crawlers in AWS Glue during synchronization, you should avoid having 25 or more crawlers in one S3 File System asset.
- You can synchronize several S3 File System assets simultaneously, but if the total number of crawlers exceeds the maximum amount in AWS Glue, synchronization fails. Since Collibra deletes the crawlers from AWS Glue after synchronization, it is safer to synchronize each S3 File System asset at a unique time.
- Crawlers in AWS Glue can crawl multiple buckets, but in Collibra, each crawler can only crawl a single bucket.
Common prerequisites
For Jobserver:
- You have a resource role with the Configure external system resource permission, for example, Owner.
- You have a global role with the Catalog global permission, for example, Catalog Author.
- You have registered an Amazon S3 file system.
- You have configured one or more Jobservers in Collibra Console. If there is no available Jobserver, the Register data source actions are grayed out in the global create menu of Collibra Platform.
- You have connected an S3 File System asset to Amazon S3.
Create a crawler
You can create a crawler for an S3 File System asset in Data Catalog.
Steps
- Open an S3 File System asset page.
- In the tab bar, click Configuration.
- In the Crawlers section, click Create crawler.
The Create crawler dialog box appears. - Enter the required information.
Field Description Domain
The domain in which the assets of the S3 file system are created.
Read more about linking domains to crawlers.- A specific Storage Catalog domain is created automatically when the S3 File System asset is created. That domain is selected by default. However, you can manually create a new Storage Catalog domain and select it.
- If multiple crawlers point to the same domain, then all assets are created in the same domain.
- If multiple crawlers point to different domains, then all assets are created in their respective domains.
- If multiple crawlers from the same S3 File System asset overlap and point to different domains, then overlapping assets are created in each domain.
- If multiple crawlers from the same S3 File System asset overlap and point to the same domain, then overlapping assets are created once in that domain.
- If crawlers from multiple S3 File System assets overlap and point to different domains, then overlapping assets are created in each domain.
- If crawlers from multiple S3 File System assets overlap and point to the same domain, then overlapping assets are created once in the domain and the S3 Bucket asset has a relation to both S3 File System assets.
Name The name of the crawler in Collibra.
Read more about crawler names.- You cannot use the same name for two crawlers in the same S3 File System asset.
- The name of the corresponding crawler in AWS Glue will contain this name. Its name will follow the following convention:
collibra_catalog_<s3fs asset id>_<name_of_the_crawler_in_Collibra>. - The crawler name must be compliant with the AWS Glue limitations:
- It has to match the single-line string pattern:
[\u0020-\uD7FF\uE000-\uFFFD\uD800\uDC00-\uDBFF\uDFFF\t]*. - The length should be between 1 and 255 bytes long, including the fixed prefix that Collibra adds. That means that you can use roughly 65 characters, depending on the characters that were used.Warning This restriction is imposed by Amazon S3, which allows up to 255 bytes, including the prefix added by Collibra. If you enter too many characters and exceed the byte limit, synchronization fails.
- It has to match the single-line string pattern:
Data source The data source indicates a data format for the AWS Glue crawler to correctly parse metadata. Select a data source for the crawler to crawl:
- S3
- Iceberg
Table Level Specify the level from which tables have to be created during the integration. By default, tables are created from the top level, level 1.
Only specify a number if you want to create tables starting from another level, such as 2 or 3. For more information, go to the AWS documentation.File Group Pattern Add a regular expression to group files with similar file names into a File Group asset during the S3 synchronization. Multiple regular expression grammar variants exist. We use the Java variant.
A regular expression, also referred to as regex or regexp, is a sequence of characters that specifies a match pattern in text.Example If you add the
(\w*)_\d\d\d\d\.csvregex, the integration automatically detects files matching this pattern and groups them into a File Group asset.You can define one regex per crawler.
Tip- Multiple websites provide guidelines and examples of regular expressions, for example, Regexlib and RegexBuddy, or even ChatGPT.
- You can also test your regular expression on various websites, for example, Regex101 (Select the Java 8 option in the Flavor panel).
The referenced websites serve only as examples. The use of ChatGPT or other generative AI products and services is at your own risk. Collibra is not responsible for the privacy, confidentiality, or protection of the data you submit to such products or services, and has no liability for such use.
Include path The case-sensitive path to a directory of a bucket in Amazon S3. All objects and subdirectories of this path are crawled.
For more information and examples, go to the AWS Glue documentation.
Exclude patterns Glob pattern that represents the objects that are in the include path, but that you want to exclude.
For more information and examples, go to the AWS Glue documentation.
Custom Classifiers If you want the AWS crawler created by the S3 integration to use a specified custom classifier, click Add Custom Classifier Name and then enter the name of the classifier in the Custom Classifier Name field. The custom classifier should be created in the AWS Glue console. For more information, go to the AWS Glue documentation.
You can add multiple classifiers by clicking Add Custom Classifier Name.
- Click Create.
You can now synchronize Amazon S3 manually or define a synchronization schedule.
Edit a crawler
You can edit a crawler of an S3 File System asset in Data Catalog. For example, you can do this if you want to edit the exclude pattern.
Steps
- Open an S3 File System asset page.
- In the tab bar, click Configuration.
- In the Crawlers section, in the row of the crawler that you want to edit, click
 .
.
The Edit crawler dialog box appears. - Enter the required information.
Field Description Domain
The domain in which the assets of the S3 file system are created.
Read more about linking domains to crawlers.- A specific Storage Catalog domain is created automatically when the S3 File System asset is created. That domain is selected by default. However, you can manually create a new Storage Catalog domain and select it.
- If multiple crawlers point to the same domain, then all assets are created in the same domain.
- If multiple crawlers point to different domains, then all assets are created in their respective domains.
- If multiple crawlers from the same S3 File System asset overlap and point to different domains, then overlapping assets are created in each domain.
- If multiple crawlers from the same S3 File System asset overlap and point to the same domain, then overlapping assets are created once in that domain.
- If crawlers from multiple S3 File System assets overlap and point to different domains, then overlapping assets are created in each domain.
- If crawlers from multiple S3 File System assets overlap and point to the same domain, then overlapping assets are created once in the domain and the S3 Bucket asset has a relation to both S3 File System assets.
Name The name of the crawler in Collibra.
Read more about crawler names.- You cannot use the same name for two crawlers in the same S3 File System asset.
- The name of the corresponding crawler in AWS Glue will contain this name. Its name will follow the following convention:
collibra_catalog_<s3fs asset id>_<name_of_the_crawler_in_Collibra>. - The crawler name must be compliant with the AWS Glue limitations:
- It has to match the single-line string pattern:
[\u0020-\uD7FF\uE000-\uFFFD\uD800\uDC00-\uDBFF\uDFFF\t]*. - The length should be between 1 and 255 bytes long, including the fixed prefix that Collibra adds. That means that you can use roughly 65 characters, depending on the characters that were used.Warning This restriction is imposed by Amazon S3, which allows up to 255 bytes, including the prefix added by Collibra. If you enter too many characters and exceed the byte limit, synchronization fails.
- It has to match the single-line string pattern:
Data source The data source indicates a data format for the AWS Glue crawler to correctly parse metadata. Select a data source for the crawler to crawl:
- S3
- Iceberg
Table Level Specify the level from which tables have to be created during the integration. By default, tables are created from the top level, level 1.
Only specify a number if you want to create tables starting from another level, such as 2 or 3. For more information, go to the AWS documentation.File Group Pattern Add a regular expression to group files with similar file names into a File Group asset during the S3 synchronization. Multiple regular expression grammar variants exist. We use the Java variant.
A regular expression, also referred to as regex or regexp, is a sequence of characters that specifies a match pattern in text.Example If you add the
(\w*)_\d\d\d\d\.csvregex, the integration automatically detects files matching this pattern and groups them into a File Group asset.You can define one regex per crawler.
Tip- Multiple websites provide guidelines and examples of regular expressions, for example, Regexlib and RegexBuddy, or even ChatGPT.
- You can also test your regular expression on various websites, for example, Regex101 (Select the Java 8 option in the Flavor panel).
The referenced websites serve only as examples. The use of ChatGPT or other generative AI products and services is at your own risk. Collibra is not responsible for the privacy, confidentiality, or protection of the data you submit to such products or services, and has no liability for such use.
Include path The case-sensitive path to a directory of a bucket in Amazon S3. All objects and subdirectories of this path are crawled.
For more information and examples, go to the AWS Glue documentation.
Exclude patterns Glob pattern that represents the objects that are in the include path, but that you want to exclude.
For more information and examples, go to the AWS Glue documentation.
Custom Classifiers If you want the AWS crawler created by the S3 integration to use a specified custom classifier, click Add Custom Classifier Name and then enter the name of the classifier in the Custom Classifier Name field. The custom classifier should be created in the AWS Glue console. For more information, go to the AWS Glue documentation.
You can add multiple classifiers by clicking Add Custom Classifier Name.
- Click Save.
Delete a crawler
You can delete a crawler from an S3 File System asset.
Note If you delete an S3 File System asset that contains one or more crawlers, the crawlers are also deleted.
Steps
- Open an S3 File System asset page.
- In the tab bar, click Configuration.
- In the Crawlers section, in the row of the crawler that you want to delete, click
 .
.
The Delete Crawler confirmation message appears. - Click Delete crawler.
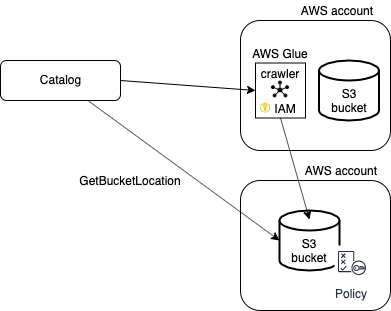
Cross-account crawling
If you use Jobserver, you can make an S3 bucket accessible for crawlers from other AWS accounts than the account in which the S3 bucket is located. To access the external S3 bucket, the programmatic user and the IAM crawling role must be defined in the AWS main account.
Policy
A policy must be attached to the external S3 bucket to allow:
- The AWS Glue crawler to access and perform S3 actions on an external S3 bucket from another AWS account.
- Data Catalog to execute the S3 GetBucketLocation API on an external S3 bucket via the programmatic user.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "collibra-jobserver-access",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<enter_id>:role/collibra-jobserver-s3-role"
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::crawler-name",
"arn:aws:s3:::crawler-name/*"
]
},
{
"Sid": "collibra-jobserver-access",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<enter_id>:user/collibra-jobserver"
},
"Action": "s3:getBucketLocation",
"Resource": [
"arn:aws:s3:::*"
]
}
]
}