Warning Jobserver and all related Jobserver integrations reached their End of Life in commercial environments in October, 2024. In Collibra Platform for Government and Collibra Platform Self-Hosted environments, they will reach their End of Life on May 30, 2027.
For information on the integration of S3 via Edge, go to Integrating an Amazon S3 file system via Edge.
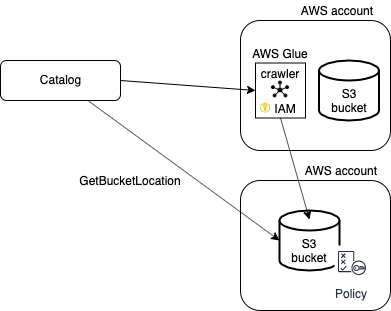
If you use Jobserver, you can make an S3 bucket accessible for crawlers from other AWS accounts than the account in which the S3 bucket is located. To access the external S3 bucket, the programmatic user and the IAM crawling role must be defined in the AWS main account.
Policy
A policy must be attached to the external S3 bucket to allow:
- the AWS Glue crawler to access and perform S3 actions on an external S3 bucket from another AWS account.
- Data Catalogto execute the S3 GetBucketLocation API on an external S3 bucket via the programmatic user.
You can use the following JSON content:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "collibra-jobserver-access",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<enter_id>:role/collibra-jobserver-s3-role"
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::crawler-name",
"arn:aws:s3:::crawler-name/*"
]
},
{
"Sid": "collibra-jobserver-access",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<enter_id>:user/collibra-jobserver"
},
"Action": "s3:getBucketLocation",
"Resource": [
"arn:aws:s3:::*"
]
}
]
}