Google Dataplex is a technical catalog on Google that provides information for data in the various Dataplex projects. If you integrate Google Dataplex, you integrate the metadata of all data of Dataplex projects into Collibra Platform. Collibra offers multiple Dataplex integration types: Google Dataplex ingestion and Google Knowledge Catalog integration. For more information, go to About working with Google Cloud Platform (GCP).
The Google Dataplex ingestion is based on Dataplex and results in assets that represent the projects, lakes, zones, tables, and columns. For information on other ingestion types, go to About Google Knowledge Catalog integration.
Important considerations:
- We only integrate the metadata, so you cannot get sample data for the columns and tables, nor profile and classify them. If you want to get sample data, and profile and classify the data, you can combine the integration of Google Dataplex with the registration of a BigQuery data source. For more information, go to Ways to work with Google Cloud Platform (GCP).
- The current Dataplex GCS discovery system has a limit of 1,000 tables per bucket.
Google Dataplex diagram view
Note You can integrate Google Dataplex only via Edge, not via Jobserver.
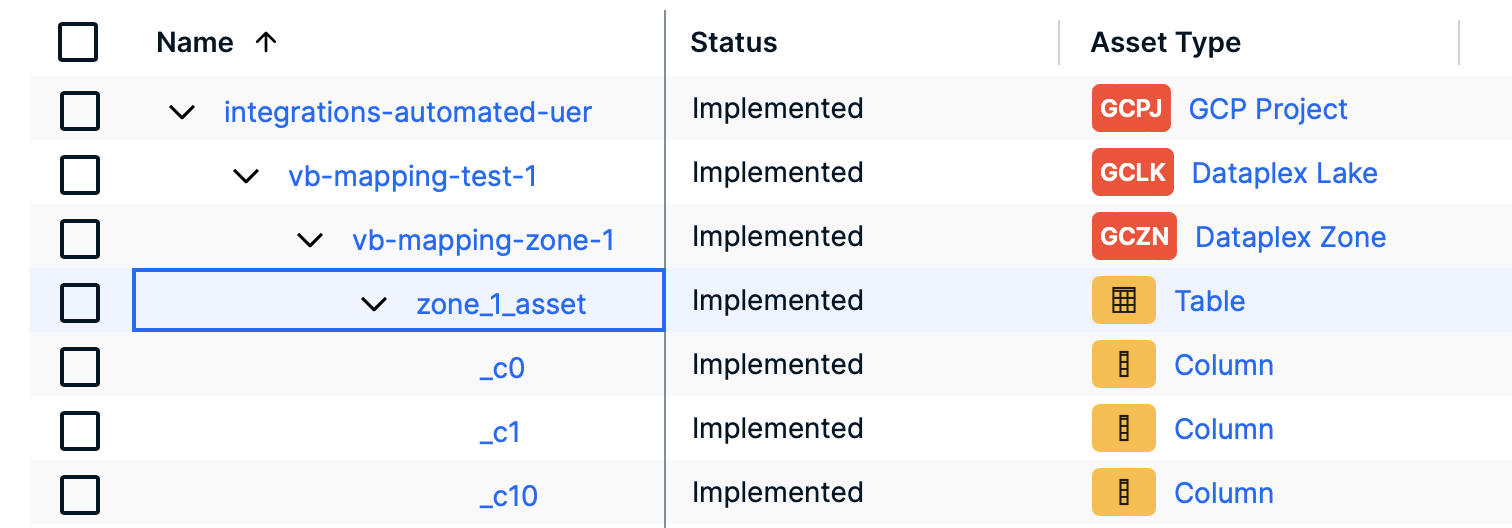
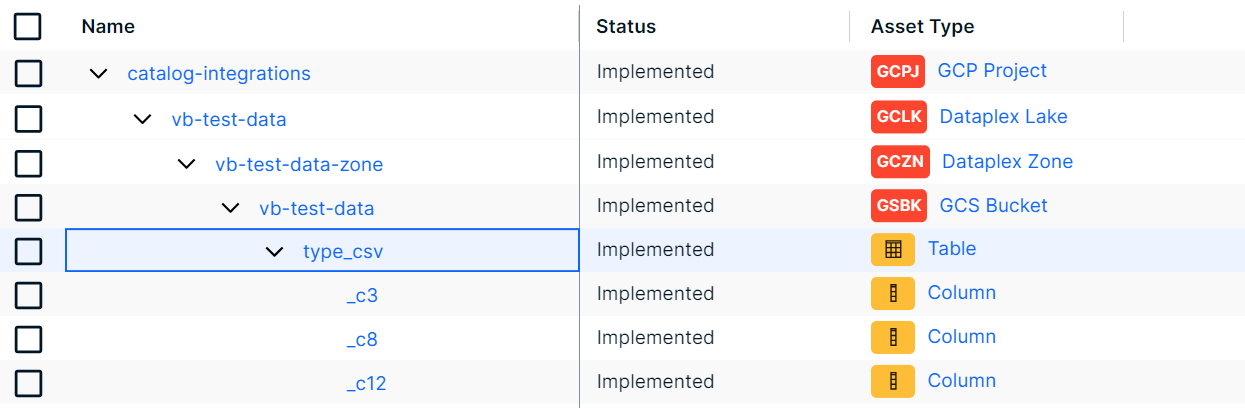
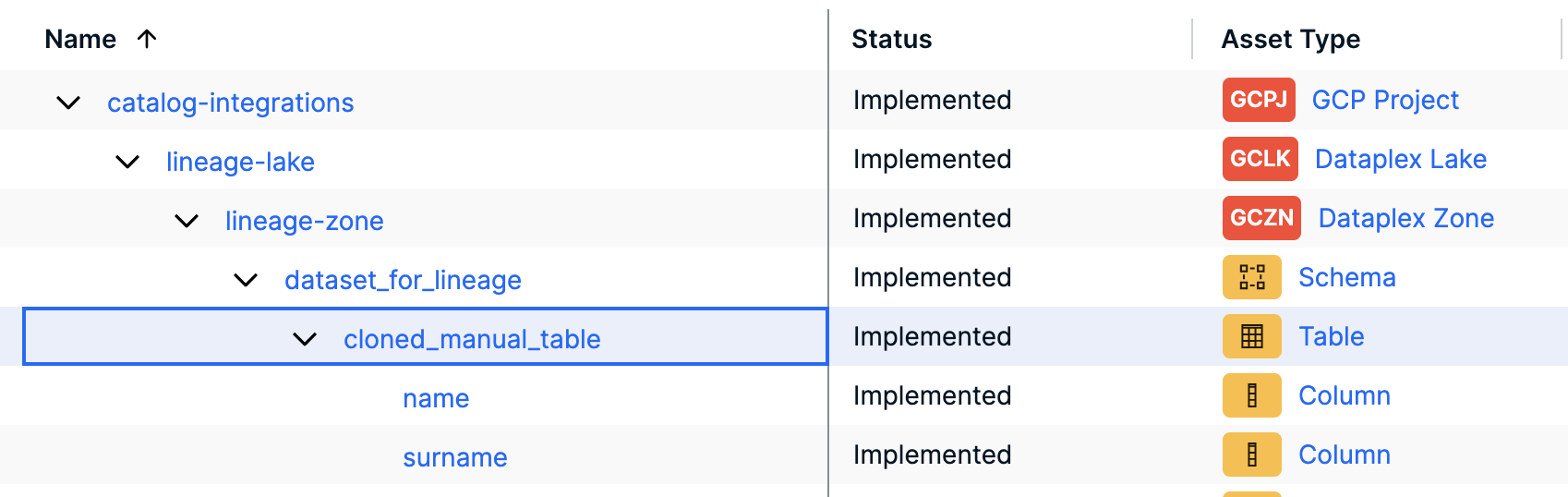
The following images show the asset types in Collibra after the integration of Google Dataplex via the Google Dataplex ingestion. Note the following:
- The asset types from Google Cloud Storage (GCS) may or may not contain the GCS Bucket asset type.
- The asset types from the integration of Google Dataplex with Google BigQuery include the Schema asset type.
- When you add a bucket to Dataplex and Dataplex identifies schemas (tables and columns) for files in the bucket, these tables and columns are also added automatically to BigQuery by Dataplex.
For information on Google Dataplex, go to the Google documentation.
For information on supported data types, go to the data types Google documentation.
Combining the ways of working
It is possible to combine the Google Dataplex integration - Dataplex ingestion and the registration of a Google BigQuery database because they result in the same technology assets.
You can use the Dataplex ingestion to quickly get an overview of all your databases in Collibra Platform. Once you have a better view of the important databases, you can register them individually via the JDBC driver.
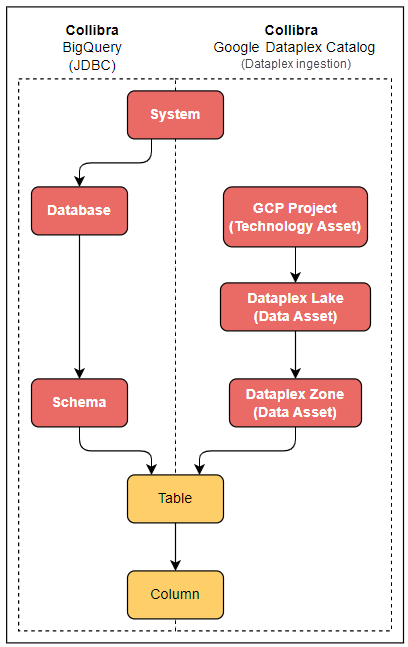
- You cannot combine the Google Dataplex integration - Dataplex Catalog ingestion with the registration of a Google BigQuery database.
- Use the same System asset for the integration and registration.
| Combining the two ways of working with GCP |
|---|
|
|