Data Profiling creates a summary of a data source in Data Catalog and determines the data type of columns in the data source. The summary mainly contains statistics and graphics to give the user an idea what the data is about.
Data Profiling is available for registered JDBC data sources
After profiling has been set up, you can profile the data via the Configuration tab in the Database asset page of the data source. Edge profiles the data on the Edge or Collibra Cloud site itself and only sends the results to Collibra Platform. The profiling results are automatically anonymized based on your anonymization configuration before they are sent to Collibra Platform.
As a result, if you profile a data source via Edge:
- Data Catalog has access to synchronized metadata and profiling results.
- Data Catalog doesn't have access to the actual data from your data source.
Profiling steps in Edge
|
Step |
Description |
|---|---|
| Before you start | |

|
Create an Edge or Collibra Cloud site with a JDBC connection, a JDBC ingestion capability, and a JDBC profiling capability. |

|
|
|
|
Synchronize one or more schemas. |

|
Configure the profiling options for the synchronized schemas. |

|
Profile the data. The Edge or Collibra Cloud site will initiate the profiling process and send the results to Collibra Platform. Tip You can trigger the profiling job manually, set up a schedule, or trigger it after synchronizing a schema. Note Columns mapped to the following java.sql.Types are excluded from the profiling queries: ARRAY, BINARY, BLOB, CLOB, DATALINK, DISTINCT, JAVA_OBJECT, LONGVARBINARY, NCLOB, NULL, OTHER, REF, REF_CURSOR, ROWID, SQLXML, STRUCT, VARBINARY. These data types are excluded because they represent complex, binary, or non-standard data, such as large text files, audio files, or video files, that may not be suitable for profiling or are not supported by the profiling process. Note The Data Classification process does not automatically run at the same time as profiling. You need to activate the classification process separately. |

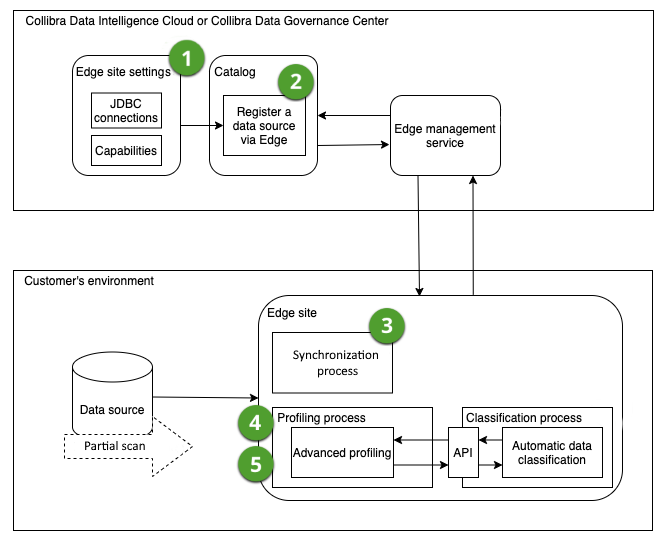
|
Step |
Description |
|---|---|
| Before you start | |
|
|
Integrate the Databricks Unity Catalog, Google Knowledge Catalog, or SageMaker Unified Studio (in preview) data sources. For Databricks Unity Catalog, to allow for profiling, add a JDBC connection in the Databricks Unity Catalog synchronization capability. For Google Knowledge Catalog, to allow for profiling, add a JDBC connection in the Google Knowledge Catalog synchronization capability. For SageMaker Unified Studio, to allow for profiling, select one or more JDBC connections on the synchronization page. During synchronization, a JDBC profiling capability is created automatically if it does not already exist. As a result, you do not need to create a separate JDBC profiling capability to profile data from integrations. For more information, go to Steps: Integrate Databricks Unity Catalog via Edge, Steps: Integrate Google Knowledge Catalog via Edge, or Steps: Integrate Amazon SageMaker Unified Studio. |
|
|
Configure the profiling options for the synchronized schemas. |
|
|
Profile the data. The Edge or Collibra Cloud site will initiate the profiling process and send the results to Collibra Platform. Tip You can trigger the profiling job manually, set up a schedule, or trigger it after synchronizing a schema. Note Columns mapped to the following java.sql.Types are excluded from the profiling queries: ARRAY, BINARY, BLOB, CLOB, DATALINK, DISTINCT, JAVA_OBJECT, LONGVARBINARY, NCLOB, NULL, OTHER, REF, REF_CURSOR, ROWID, SQLXML, STRUCT, VARBINARY. These data types are excluded because they represent complex, binary, or non-standard data, such as large text files, audio files, or video files, that may not be suitable for profiling or are not supported by the profiling process. Note The Data Classification process does not automatically run at the same time as profiling. You need to activate the classification process separately. |
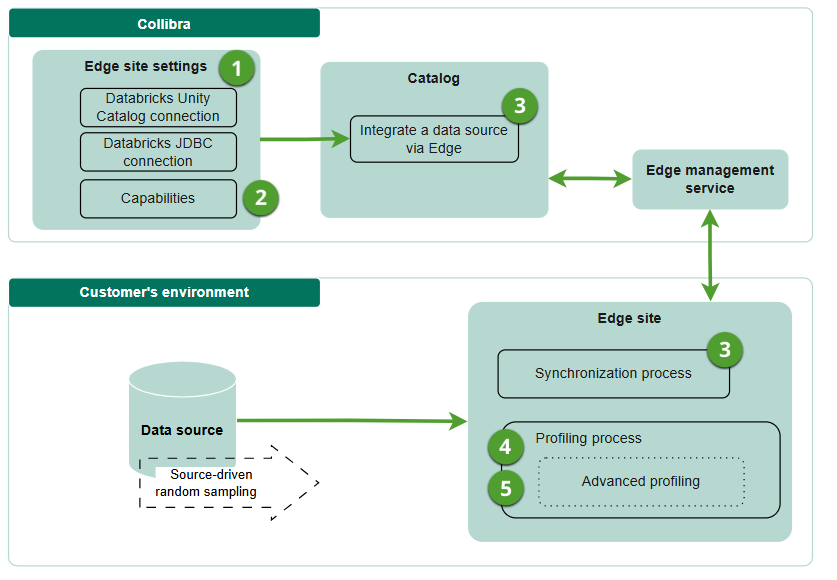
Data used to create profiling results via Edge
To create the profiling results, Data Catalog uses a representative set of the data from the data source.
Note This data is not the same as the sample data that can be available for an asset.
Edge profiles the data on the Edge or Collibra Cloud site itself and only sends the profiling results to Collibra Platform.
- If you use all rows, all the rows in a data source table are used by Edge for profiling, without limit.
- If you use a random set of rows, the data source randomly selects data and sends it to Edge for profiling.
Important Only some data sources support the use of random rows, also called source-driven random sampling. To verify if it is available for your data source, go to Collibra-provided JDBC drivers.
For more information, go to Configure the profiling options via Edge.