Warning Jobserver and all related Jobserver integrations reached their End of Life in commercial environments in October, 2024. In Collibra Platform for Government and Collibra Platform Self-Hosted environments, they will reach their End of Life on May 30, 2027. For more information, go to Announcements.
Automatic Data Classification via the Cloud Data Classification Platform
When you register a data source, you can store a data profile and sample data. This is required if you want to classify columns in the data set. The Cloud Data Classification Platform predicts the data classes of selected columns and sends them back to Collibra Platform, where you confirm or reject the suggested data classes. The Cloud Data Classification Platform uses your feedback to retrain the platform and improve future data classifications.
Warning If you want to use the Cloud Data Classification Platform, request it via your Collibra contact or create a support ticket. See also Cloud Data Classification Platform setup.
Limitations
- Automatic data classification via the Cloud Data Classification Platform is a cloud service. Only if your on-premises environment can reach the cloud service, you can use it.
- Out-of-the-box, automatic data classification can predict several data classes. However, you can also create user-defined data classes to increase its prediction quality.
- The only supported language for data classes is English.
- The Cloud Data Classification Platform needs sample data and profiling data to be able to predict the data classes.
Note You can create sample data and profiling data by registering a data source and choosing to create sample data and profiling data or by importing the data via the Catalog API.
- The Cloud Data Classification Platform only works for columns of data sources that are registered in Data Catalog with sample data and profiling data.
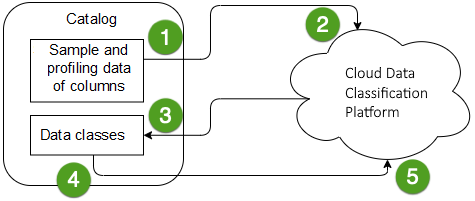
Automatic data classification flow via the Cloud Data Classification Platform
In the following schema, you can see the different steps of an automatic data classification flow via the Cloud Data Classification Platform.
|
Step |
Description |
|---|---|

|
You select the columns that you want to classify and send their sample and profiling data to the Cloud Data Classification Platform. See Classify columns |

|
The Cloud Data Classification Platform predicts the data classes of the columns. |

|
The Cloud Data Classification Platform sends the data classes to Collibra. |

|
You provide feedback by accepting or rejecting the predicted data class of each column or by adding your own new classes. The Cloud Data Classification Platform can predict multiple data classes for one column. If the prediction is accurate, you can accept multiple data classes for one column. |

|
Your data class selections are sent to the Cloud Data Classification Platform . |