Configure job limits
Prerequisites
You have the Data Quality Admin global role with the Data Quality > Manage Settings global permission.
Steps
- On the main toolbar, click
 →
Settings.
→
Settings. - Click the Data Quality tab.
- Click Limits.
- Update the limits, as needed.
- Red for failing scores (default 0-75)
- Orange for warning scores (default 76-89)
- Green for passing scores (default 90-100)
- Click Save changes.
| Limit | Description |
|---|---|
| Lookback limit |
The lookback limit is the number of previous job runs that Data Quality & Observability examines to train the adaptive rules model. The default value is 21. You can adjust it by entering a value greater than 0. |
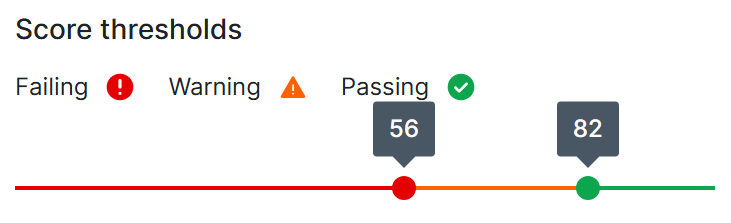
| Score thresholds |
Score thresholds are specific data quality scores that you can configure to determine whether a job is passing or failing. Scores between the passing and failing thresholds are marked as warnings to alert users to possible or emerging data quality issues. The scoring scale uses two sliders for the passing and failing thresholds and is visually represented in color-coded segments:
To set custom scoring thresholds, click and drag the passing or failing slider until the associated number matches your desired score threshold. |
| Maximum concurrent pushdown jobs |
The number of Pushdown jobs that can run at the same time. The default is 5. You can adjust it by entering a value between 1 and 25. |
| Maximum concurrent pullup jobs |
The number of Pullup jobs that can run at the same time. The default is 5. You can adjust it by entering a value between 1 and 25. |
| Pullup job sizing limits |
The maximum Spark resources each Pullup job can request. For recommendations on how you might consider configuring these settings, go to Pullup job sizing recommendations. |
|
Maximum number of executors
|
The maximum number of executors that the Spark agent can allocate to a job to process it efficiently. The default is 4. |
|
Maximum executor memory
|
The maximum amount of RAM per executor that the Spark agent can allocate to a job to process it efficiently. The default is 8 GB. |
|
Maximum number of driver cores
|
The maximum number of driver cores that the Spark agent can allocate to a job to process it efficiently. The default is 1. |
|
Maximum driver memory
|
The maximum amount of driver memory that the Spark agent can allocate to a job to process it efficiently. The default is 2 GB. |
|
Maximum executor cores
|
The maximum number of executor cores that the Spark agent can allocate to a job to process it efficiently. The default is 4. |
|
Maximum worker memory
|
The maximum amount of memory per Spark worker that the Spark agent can allocate to a job to process it efficiently. This value is proportionate to the total number of workers in your environment. The default is 8 GB. |
|
Maximum worker cores
|
The maximum number of CPU cores per worker that the Spark agent can allocate to a job to process it efficiently. This value is proportionate to the total number of workers in your environment. The default is 4. |
|
Maximum partitions
|
The maximum number of partitions in your data to allow Spark to process large jobs more efficiently. A partition is an even split of the total number of rows in your data. For large jobs, increasing the number of partitions can improve performance and processing efficiency. If your data is unevenly distributed, you may need to increase the number of partitions to avoid data skew. The default is 100. |
|
Parallelism factor
|
The parallelism factor setting that controls the Spark job execution parallelism. This setting accepts values from 1 to 8, allowing you to optimize performance by increasing partition density per executor unit. |
Helpful resources
- Review the options in the Monitoring Overview to begin working with your data.
- Add quick monitoring to schemas in your data source.
- Create a Data Quality Job.