What is Livy?
Apache Livy is a RESTful web service that serves as a session manager for Spark jobs on Kubernetes and Hadoop deployments of Data Quality & Observability Classic. Livy creates temporary Spark pod sessions (Spark Contexts) to efficiently run jobs in the Spark cluster. Data Quality & Observability Classic uses Livy to help estimate the number of resources it needs to process and preview jobs that run against datasets created from remote file connections, such as S3 and ADLS. Without Livy, you cannot preview the data that you bring in from remote files.
Additionally, when you create rules on the Rule Workbench, Livy's ability to read and transform large datasets allows you to use the Result Preview component for a convenient sample of available columns in your dataset. With a preview of the columns in your dataset next to the rule builder, Livy enables you to more efficiently write SQL business rules without having to leave the page to reference your dataset.
Note Livy is included as an optional component in most Collibra DQ release packages. Contact your Collibra Account Team to help you choose a release package with Livy.
Livy architecture within Collibra DQ
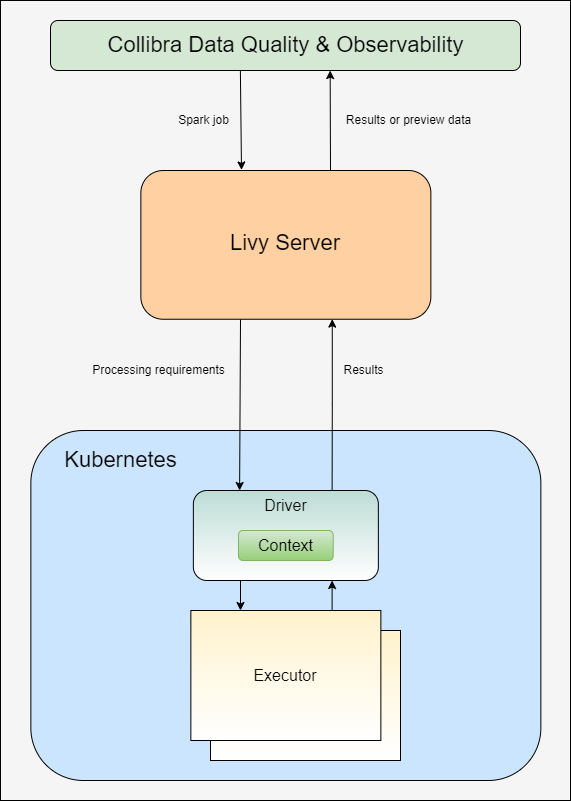
- Data Quality & Observability Classic submits a Spark job to the Livy server.
- Livy:
- Examines the data to determine the optimal number of resources it needs to efficiently process the job.
- Creates a Spark context to communicate with the Spark runtime and coordinate the execution of the job.
Note Kubernetes provides the compute space for the ephemeral Spark containers that comprise the Spark session needed to run, but there is not a Spark Cluster when running on Kubernetes.
- Spark workers execute the job inside the cluster.
- The results return to Data Quality & Observability Classic.
Supported deployment types
Livy is currently supported on Kubernetes deployments of Data Quality & Observability Classic.
Important Livy is not currently supported on Standalone or Hadoop deployments.
Supported remote file data sources
The following table shows the remote file connections that support Livy.
| Connection | Supported | Estimate Job |
|---|---|---|
| Amazon S3 |
|
|
| HDFS |
|
|
| Google Cloud Storage |
|
|
| Azure Data Lake Storage |
|
|
| Azure Blob Storage |
|
|
| Network File Storage | ||
|
CSV
|
|
|
|
ORC
|
|
|
|
Parquet
|
|
|
|
Avro
|
|
|
|
JSON
|
|
|
|
XML
|
|
|
|
Delta
|
|
|
|
Hudi
|
|
|