Data Retention Policy allows admins to purge data from Data Quality & Observability Classic based on time- or size-based policies in both single- and multi-tenant environments. This feature is turned off by default, so you must opt in before proceeding.
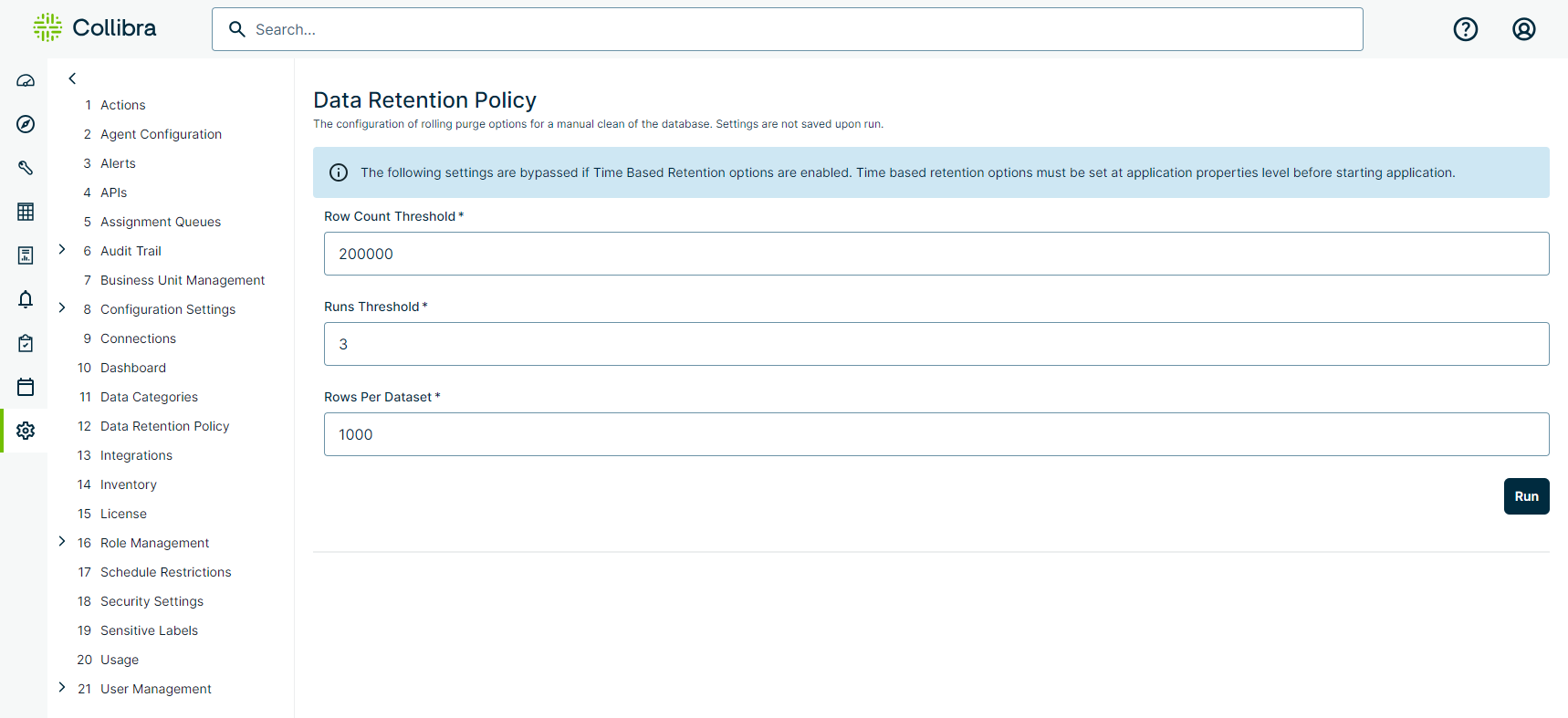
| Option | Description |
|---|---|
| Row Count Threshold | The minimum number of rows in the data_preview table for the system to consider purging data from it. |
| Runs Threshold | The minimum number of DQ Job runs of a given dataset that exceeds the Rows Per Dataset and Row Count Threshold minimum requirements for the system to consider purging data from it. |
| Rows Per Dataset | The minimum number of rows of a dataset that exceeds the Runs Threshold and Row Count Threshold minimum requirements for the system to consider purging data from it. |
How does it work?
- Data Quality & Observability Classic checks if data needs to be purged by comparing the row count threshold to the total number of rows in the data_preview table of the Metastore.
- It generates a list of purge candidates for each dataset based on the number of runs by run ID and total rows in the table.
- It removes rows for the oldest run IDs in each table by looping through the candidate list.
- A new candidate list is created, and step 3 is repeated.
| Option | Description |
|---|---|
| Retention by Fields |
Options include:
|
| Retention Days | The number of days data is retained before being automatically purged. |
How does it work?
- Data Quality & Observability Classic checks the dataset_scan table of the Metastore to determine if data needs to be purged. It identifies days outside the threshold based on your selection of either By Run Date (run_id) or By Update Timestamp (updt_ts).
- It generates a list of purge candidates for rows in the dataset_scan table that exceed the threshold of the selected field.
- The dataset name and run ID of all rows in the candidate list are joined with the dataset name and run ID in the specific table to identify the rows to be purged from that table.
Note When Data Quality & Observability Classic attempts to create a purge candidate list, it may not identify any rows for removal in the specific tables.
What is purged?
When data is purged from Data Quality & Observability Classic, data from each dataset included in the purge is cleared on a rolling basis. When a dataset is cleaned as part of this process, the following tables are purged from the Metastore.
| Table | Table description | Data |
|---|---|---|
| Shared by many activities | ||
|
data_preview
|
The drill-in records for rules, outliers, shapes, and so on. | dataset and runId |
|
observation
|
The type of finding discovered during a DQ Job run. | dataset and runId |
| Profile | ||
|
dataset_scan
|
The findings scores and pass and fail information for a given DQ Job run. | dataset and runId |
|
dataset_field
|
The profiling stats relative to any given column for a database table scan. | dataset and runId |
|
dataset_field_value
|
The top and bottom N values of a dataset, including the unique count. | dataset and runId |
|
datashape
|
The data shape format, associated linkID, and assignments. | dataset and runId |
| Dataset Histogram | ||
|
dataset_hist
|
The historical job run values, including the averages, medians, and quartile information for a given dataset. | dataset and runId |
| Dataset Correlation | ||
|
dataset_corr
|
The correlation data between columns. | dataset and runId |
| Behavior | ||
|
behavior
|
The profile data observed during a DQ Job run, including min, max, and stats relative to a given column. | dataset and runId |
| Rules | ||
|
rule_breaks
|
The rule breaks and link IDs for a given dataset and DQ Job run. | dataset and runId |
|
rule_output
|
The results of a rule observed during a DQ Job run. | dataset and runId |
| Outliers | ||
|
outlier
|
The outlier column, type, value, confidence score, associated link ID, and assignments. | dataset, runId, and true |
| Validate Source | ||
|
validate_source
|
The source dataset and its associated observation types and counts related to validate source correlation. Any tables associated with validate_source will be included in the purge. | dataset and runId |
|
dataset_schema_source
|
The schema differences between source and target datasets observed during a DQ Job run. | dataset and runId |
| Other | ||
|
alert_output
|
The contents of the alert email that send when the required conditions are met to trigger an alert during a DQ Job run. | dataset and runId |
|
dataset_activity
|
A rollup of all the aggregate stats for a given DQ Job run, including the time it takes to run per activity. | dataset and runId |
|
hint
|
The DQ Job activity stages and the stage details that populate on the Job log. For example, LOAD - 15520 rows loaded to Historical dataframe. | dataset and runId |
|
dq_inbox
|
All processed findings with rank values to help calculate the final impact to the DQ Job score. | dataset and runId |
Additionally, the following dataset run data is included in the purge:
| Element | Description | Data |
|---|---|---|
| Dataset | Any dataset containing data flagged as sensitive. | String dataset, Date runId, dataset, runId, and "admin" |
| PII | Personally identifiable information observed in datasets during DQ Job runs. | String dataset, String colName, dataset, and colName |
| MNPI | Material nonpublic information observed in datasets during DQ Job runs. | String dataset, String colName, dataset, and colName |
After a data purge, dataset and runId details are included in the Security Audit. To confirm if your dataset was purged, ask your admin to review the Security Audit records.