Data similarity is a feature that proposes similar assets. This can be useful for data consumers because:
- It simplifies data discovery: Quickly find relevant data based on connectivity and similarity to existing tables.
- It saves time and effort: Uncover valuable data sources without extensive manual searching or relying on experts.
- It builds trust in data: Check the data similarity score to assess the suitability of data for specific needs.
Currently, this feature is available in Data Marketplace to show similar Table assets.
This feature is powered by Collibra AI. To calculate the similarity between tables, Collibra AI compares the tables and their columns, and calculates a similarity score. This similarity score indicates how similar assets are. For information about how we leverage AI in our products, including how we handle data that is used for training and input, go to the Collibra Trust Site.
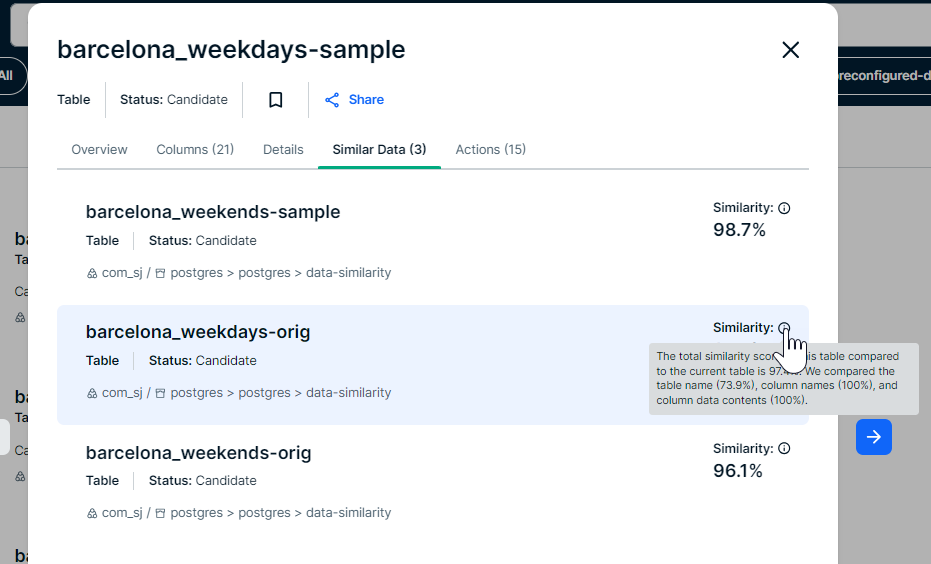
Similarity score calculation for a table
The table similarity score indicates the similarity between two tables and ranges from 0 (not similar) to 100 (very similar). The score combines three metrics:
- Table name similarity: This metric compares the table names.
- Column name similarity: This metric compares all column names. It checks how many columns have a similarly named column, and how similar the names are.
- Column content similarity: This metric compares the data in all columns. It checks how many columns have similar content.
Once the metric scores are known, the following formula is used: total_similarity = (0.10 * table_name_similarity + 0.20 * column_names_similarity + 0.70 * column_content_similarity) * 100
Note We compare only tables and columns that have been profiled. For more information, go to Enable and calculate data similarity.
Data similarity in Data Marketplace
If the Data similarity feature is enabled in your environment, the Similar Data tab is shown in Table asset previews. The tab is shown only if tables with a similarity score higher than the defined threshold exist for the table. Up to five Table assets are shown. For information on the Table asset preview, go to Asset preview.
Frequently asked questions (FAQ) on data similarity
Which data is used for similarity comparisons?
Currently, Collibra AI compares only profiled tables and columns.
Where can you see similarity?
Currently, this feature is available only in Data Marketplace for Table asset comparison. Similar Table assets are shown in the Similar Data tab.
How does data similarity work?
During data profiling, we irreversibly hash your table and column data on Edge before sending the data to Collibra. Collibra AI only uses a subset of the actual data, maximum 10,000 rows, to create these hashes These summaries are stored in Collibra. When you open a Table preview in Data Marketplace, the summaries are used to find similar data assets.
If you want to know more, reach out to your Collibra Account Team.