Synchronizing schemas is the process of updating the metadata of a registered data source in Collibra Data Intelligence Cloud.
You can synchronize a schema manually or automatically at fixed intervals:
- Synchronize manually if you want to test the synchronization of your data source or if you want to synchronize immediately.
- Synchronize automatically if the content of the data source changes regularly.
Synchronization process
- After you have registered a data source via Edge, Data Catalog connects to your Edge site to create a list of schemas from the registered database.
You can see the schema list on the Configuration tab page of the Database asset page. - You can refresh the schema list in the Configuration tab page, by clicking the
 Refresh List icon.
Refresh List icon. - You can synchronize all schemas that have one or more synchronization rules.
- During the synchronization process, the Edge site connects to your data source again and ingests all schemas, tables and columns according to the synchronization rules. Collibra Data Intelligence Cloud also detects whether there are changes since the last synchronization of a schema.
Edge resolves the possible conflicts in the following way:
Change in data source Result in Collibra Required action A table, column or foreign key has been added to the schema. Collibra creates the assets. No action is required of you. A table, column or foreign key has been removed from the schema. The existing asset receives the Missing from source status.
If it concerns a table, also the related Column assets receive the Missing from source status.This process is called soft delete.
If needed, you can manually delete the assets. A schema has been removed. The schema receives the Missing from source status. Also the related Table and Column assets receive the Missing from source status.
This process is called soft delete.
If needed, you can manually delete the Schema asset and all related assets. A column or foreign key has been renamed. - Collibra creates an asset with the new name.
- The existing asset receives the Missing from source status.
This process is called soft delete.
If needed, you can apply any manual changes you made to the original asset, to the new asset. And then remove the assets that are no longer applicable. A table has been renamed. - Collibra creates a Table asset with the new name. Collibra also creates new Column assets for the new Table asset.
- The existing Table and related Column assets receive the Missing from source status.
This process is called soft delete.
If needed, you can apply any manual changes you made to the original assets, to the new assets. And then remove the assets that are no longer applicable. A schema has been renamed. - Collibra creates a Schema asset with the new name. Collibra also creates new Table and Column assets for the new Schema asset.
- The existing schema and related assets receive the Missing from source status.
This process is called soft delete.
If needed, you can apply any manual changes you made to the original assets, to the new assets. And then delete the assets that are no longer applicable. Any created assets receive a unique full name (fully qualifying name) based on Edge naming conventions.
Schema, Table, Column or Foreign Key assets with the Missing from source status don't block the synchronization process.
Note In the asset diagram, assets with the Missing from source status are shown by default. If you don't want to see these assets, apply a filter to the diagram view to only display assets with valid statuses.
Important If you rename a database in the data source, the Edge synchronization process will consider it a new database. We don’t detect the renaming of a database at this moment.
- If, in the rule, you have indicated you want to include source tags, the tags defined on the assets in the data source are registered and available from the Schema, Table, Database View, and Column assets in the Source Tags attribute. For more information, go to Source tags.
- If a schema is synchronized, you see a check symbol (
 ) next to the schema name.
) next to the schema name.
If the synchronization of a schema fails or the schema is no longer available in the source, an exclamation mark ( ) is shown instead.
) is shown instead.
You can also see the synchronization status in the Activities list.
- After the synchronization, the synchronized data becomes available. To see which data is added, go to Metadata synchronization results.
- If you no longer want to synchronize a schema, and delete associated assets, go to Remove a synchronized schema.
Synchronization rules
The synchronization rule determines which tables of a schema you synchronize in Data Catalog.
- You can add up to five synchronization rules. The order of the rules is important. For all information, go to Configure the synchronization of a data source.
- The Schema asset and the Foreign Key assets are always ingested in the domain defined in the first rule.
- Only schemas that have at least one synchronization rule can be synchronized. If a schema has a synchronization rule, you see a table icon (
 ) next to the schema name.
) next to the schema name.
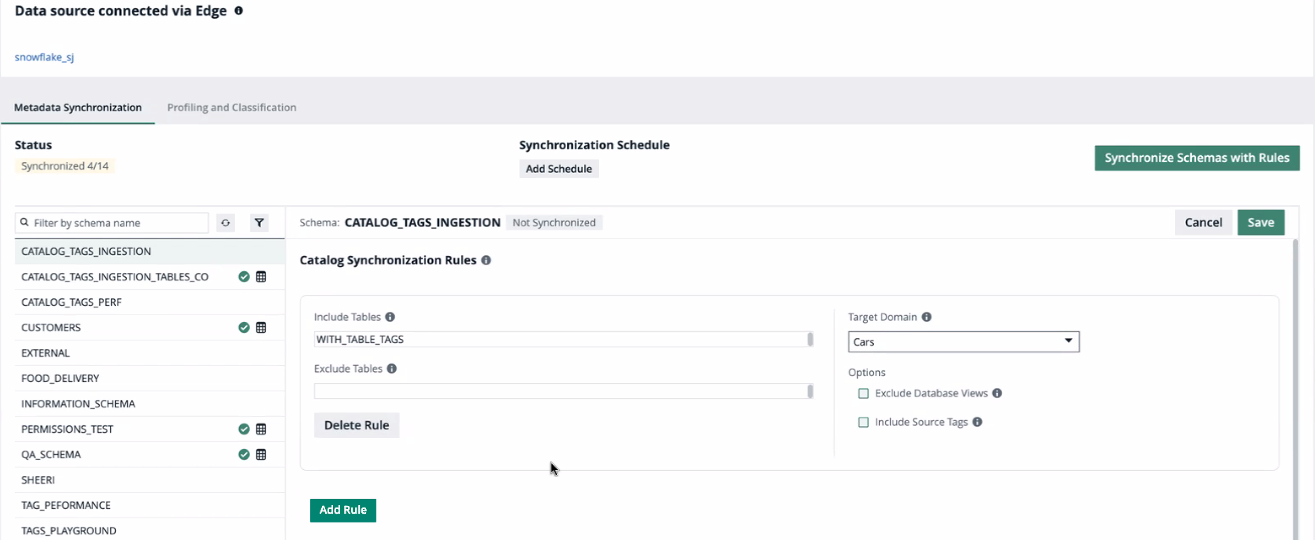
The following table shows fields of synchronization rules:
| Rule field | Description |
|---|---|
| Include Tables |
A comma-separated list of the names of the tables you want to synchronize.
Example
|
| Exclude Tables |
A comma-separated list of the names of the tables you do not want to synchronize.
You can use exclude to do the following:
Example
|
| Target Domain |
The Physical Data Dictionary domain in which the schema is synchronized. The default value is Schema domain. This means the metadata is placed in a domain located in the same community as the domain of your Database asset. If that domain doesn't exist yet, Data Catalog creates the domain using the following naming convention: [edge_connection_name] > [database_name] > [schema_name], for example Snowflake Connection > CERTIFICATION > CUSTOMERS.
You can select any other Physical Data Dictionary domain for which you have a resource role with the Configure External System resource permission. It is advised, however, to have a domain per schema. |
| Options |
Additional options to specify which type of tables you want to synchronize. |
|
Exclude Database Views
|
A checkbox to exclude database views from the synchronization process. If selected, no assets of the type Database view are created. Tip You can also use Include Tables and Exclude Tables to include or exclude specific database views. |
|
Include Source Tags
|
This option is only available if you have enabled the synchronization of source tags. If you select this option, the tags defined on the assets in the data source are registered and available from the Schema, Table, Database View, and Column assets in the Source Tags attribute. Note Currently, you can synchronize source tags only from Snowflake. |
Source tags
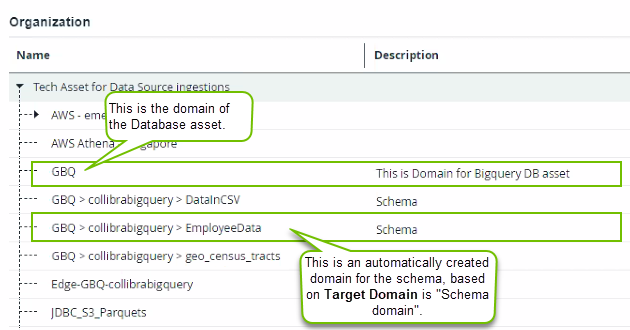
Tags created and assigned in the data source can be registered and synchronized in Data Catalog.
To do this, you need to enable the synchronization of source tags and select the Include Source Tags checkbox when you define the synchronization rule for a schema. As a result, the tags defined on the assets in the data source are registered and available from the Schema, Table, Database View, and Column assets in the Source Tags attribute.
Note Currently, you can synchronize source tags only from Snowflake.
- The naming convention for source tags synchronized from Snowflake is:
<source_tag_name>=<source_tag_value>, for example: cost_center=sales.<source_tag_name>, if no values are assigned to the tag, for example PII.
- We apply the same inheritance for source tags as the data source. Example
- If a tag was assigned to a schema in Snowflake, the tag will be registered for the related Schema, Table, Column and View assets in Data Catalog.
- If a tag was assigned to an account in Snowflake, the tag will be registered for the related Schema, Table, Column and View assets in Data Catalog.
For information on tags in Snowflake, go to the Snowflake documentation.
- Don't change the source tags in Data Catalog, as the changes are not pushed to the data source. I If you make changes to the tags in the data source and synchronize the data source again, your updates will be overwritten with the information from the data source.