Configuring Apache Hadoop to Execute DQ Jobs
The following diagram shows the DQ architecture with a Hadoop cluster:
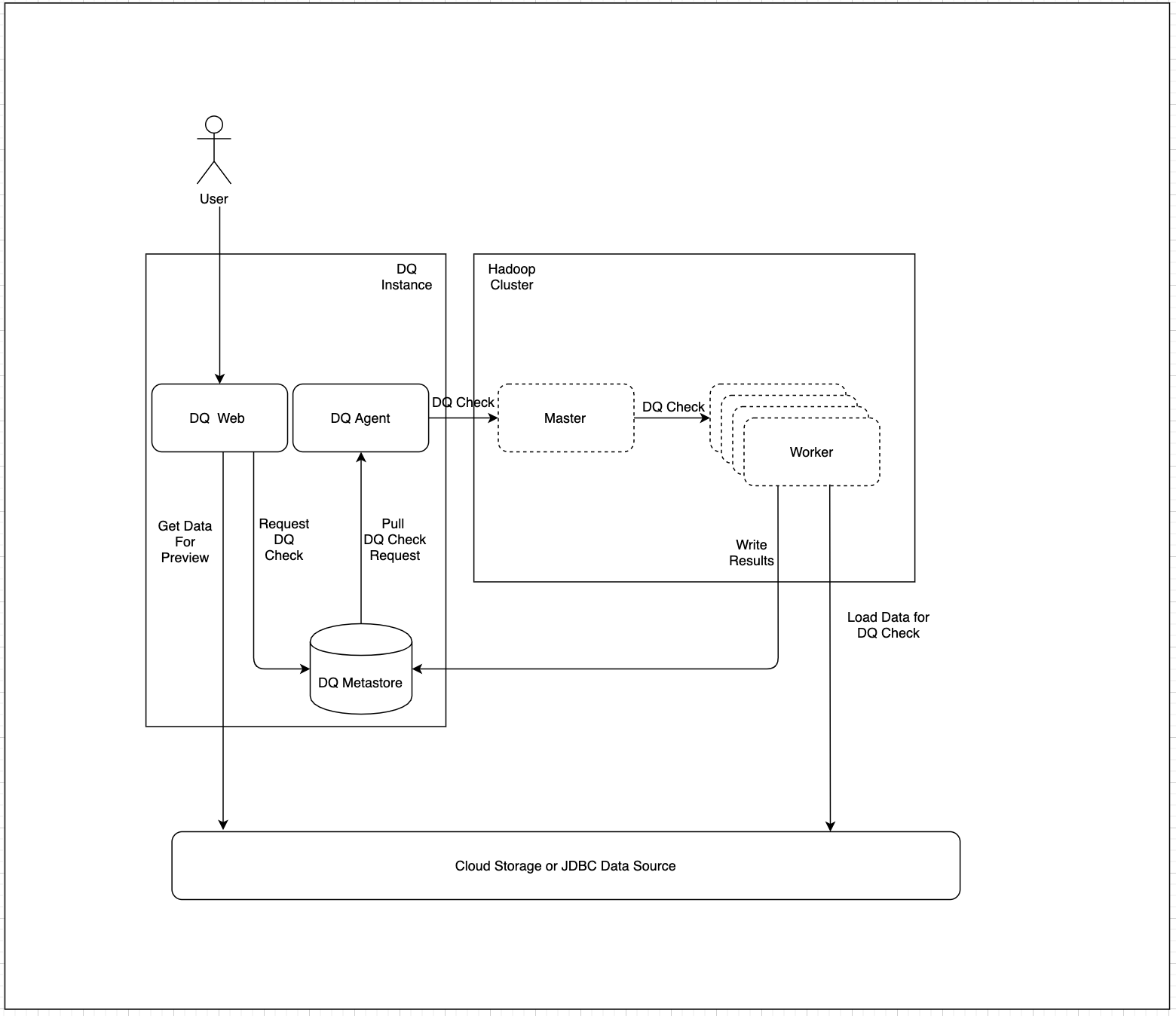
The following diagram shows the DQ architecture with a Hadoop cluster: