Installing Data Quality & Observability Classic on self-hosted Kubernetes
Data Quality & Observability Classic wholeheartedly embraces the principles of cloud native technologies in its design and deployment. Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds.
The diagram below depicts Data Quality & Observability Classic's cloud native deployment architecture:
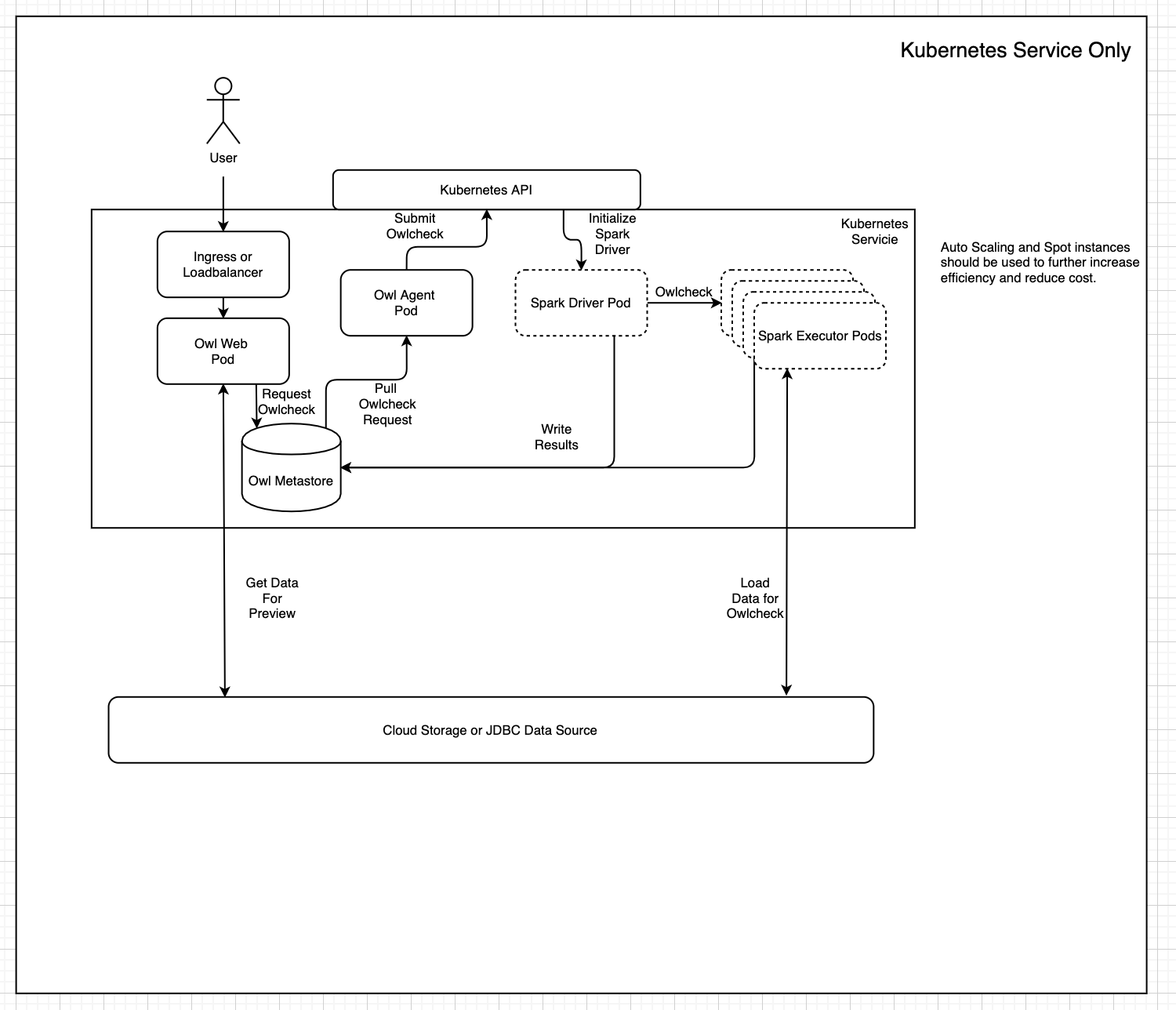
In this form factor, you can deploy Collibra DQ in any public or private cloud while maintaining a consistent experience, performance, and management runbook.
Collibra DQ microservices
To achieve cloud native architecture, Collibra DQ is decomposed into several components, each of which is deployed as a microservice in a container.
Containerization
The binaries and instruction sets described in each of the Collibra DQ microservices are encompassed within Docker container images. Each of the images is versioned and maintained in a secured cloud container registry repository. To initiate a Collibra DQ cloud native deployment, you must first obtain credentials to either pull the containers directly or download them to a private container registry.
Warning Support for Collibra DQ cloud native deployment is limited to deployments using the containers provided from the Collibra container registry.
Reach out to your customer contact for access to pull the Collibra containers.
Kubernetes
Kubernetes is a distributed container scheduler and has become synonymous with cloud native architecture. While Docker containers provide the logic and runtime at the application layer, most applications still require network, storage, and orchestration between multiple hosts in order to function. Kubernetes provides all of these facilities while abstracting away all of the complexity of the various technologies that power the public or private cloud hosting the application. Collibra DQ supports the following Kubernetes vendors:
- Amazon Elastic Kubernetes Service (EKS)
- Azure Kubernetes Service (AKS)
- Google Kubernetes Engine (GKE)
Collibra DQ Helm chart
While Kubernetes currently provides the clearest path to gaining the benefits of a cloud native architecture, it is also one of the more complex technologies in existence. This has less to do with Kubernetes itself and more with the complexity of the constituent technologies it is trying to abstract. Technologies like attached distributed storage and software defined networks are entire areas of specialization that require extensive expertise to navigate. Well implemented Kubernetes platforms hide all of this complexity and make it possible for anyone to leverage these powerful concepts. However, a robust application like Collibra DQ requires many descriptors (K8s manifests) to deploy its various components and all of the required supporting resources like network and storage.
This is where Helm comes in. Helm is a client side utility (since v3) that automatically generates all the descriptors needed to deploy a cloud native application. Helm receives instructions in the form of a Helm chart that includes templated and parameterized versions of Kubernetes manifests. Along with the Helm chart, you can also pass arguments like names of artifacts, connection details, enable and disable commands, and so on. Helm resolves the user defined parameters within the manifests and submits them to Kubernetes for deployment. This enables you to deploy the application without necessarily having a detailed understanding of the networking, storage or compute that underpins the application.