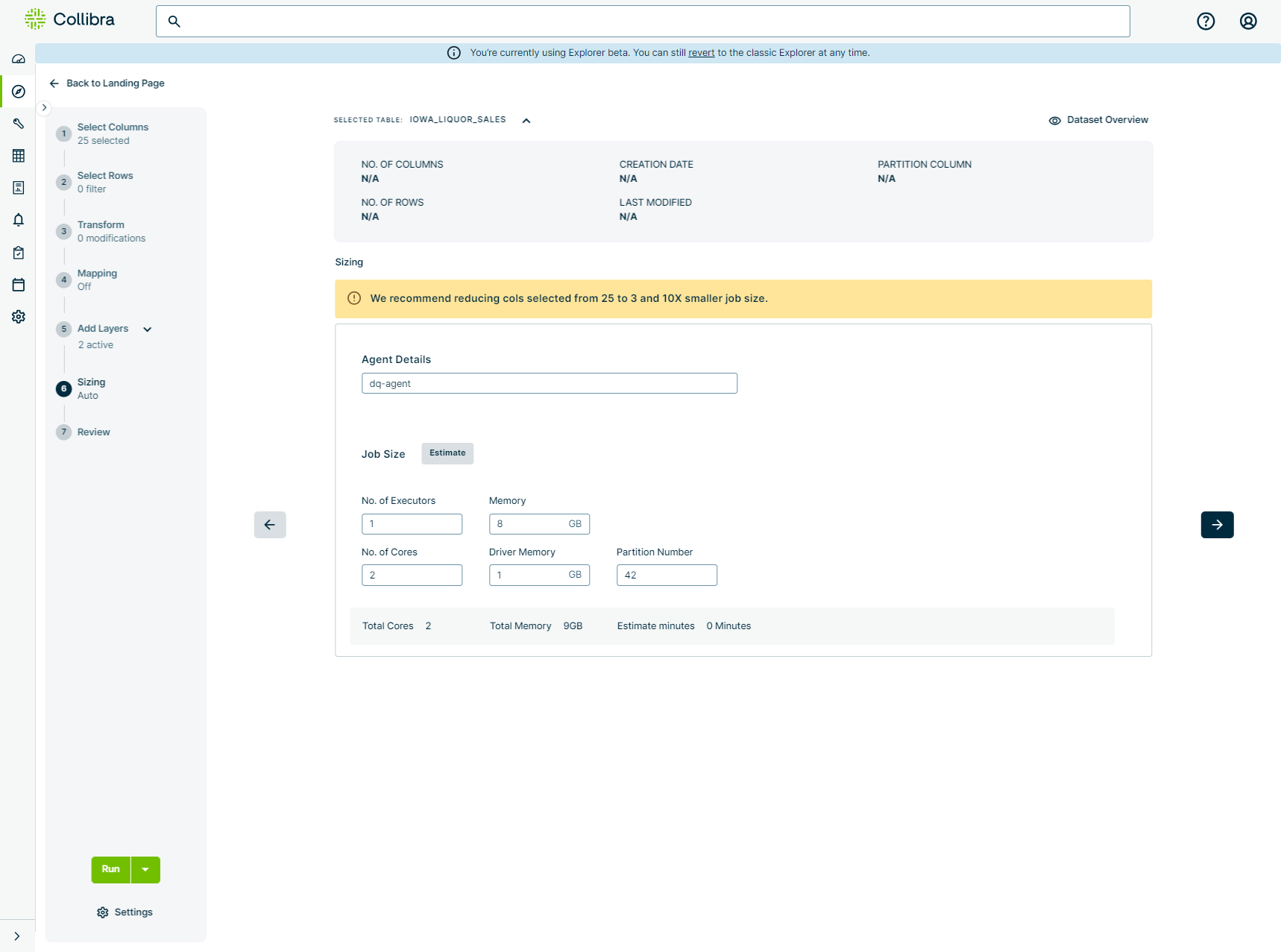
This page shows you how to configure your environment to allow Collibra DQ to automatically estimate the sizing requirements of your job, as shown in the following screenshot of a job with updated Spark resources after job size estimation.
When you enable the automatic calculation of the sizing requirements of a job, the following parameters must be set from the Admin Console ![]() Admin Limits.
Admin Limits.
Note While this is a one-time configuration, if you have a multi-tenant environment, this must be configured per tenant.
Steps
- Sign in to Collibra DQ and click the
 in the sidebar menu
in the sidebar menu - Click Admin Console.
- Select Configuration Settings in the left navigation panel.
- Select Admin Limits.
- Review the configurations for the required parameters and make updates as needed.
- From Explorer, create a Pullup job.
- In the Sizing step of the Explorer workflow, click Estimate. The Job Size configurations automatically update to reflect the sizing requirements of your dataset.
- Click Run or continue updating your Pullup job.
| Setting | Description | Recommended Value |
|---|---|---|
| partitionautocal |
Enables the automatic partition calculation on the Review step in Explorer. For the automatic partition calculation to be available, this value must be set to |
true
|
| maxpartitions | The maximum number of partitions. You can change this depending on the performance needs of your environment. | 200 |
| totalworkers |
The total numbers of workers available. In Spark Standalone this is the maximum number of Spark workers in your Spark cluster. In Kubernetes, this is the maximum number of VMs. In Hadoop, Dataproc, or EMR, this is the maximum number of task nodes. Important While the default for totalworkers is 100, we strongly advise you work with your team's internal DQ admins to determine the value required for your environment. If you are unsure of the value to set, we recommend setting this to 1. |
100 |
| maxworkercores |
The maximum number of CPU cores per worker. This value is proportionate to the limit you set for totalworkers based on your environment. |
2 |
| maxworkermemory |
The Agent Worker Maximum Memory (WMM) is the maximum amount of memory per worker in gigabytes. This value is proportionate to the total number of workers in your environment. Example An environment configuration with 8 worker cores and 4 workers would have 32 gigabytes of memory. |
12 |
| minworkermemory | The Agent Worker Minimum Memory (WMI) is the minimum amount of memory per worker in gigabytes. This value is proportionate to the maximum number of workers in your environment. | 2 |
| pergbpartitions |
The minimum number of partitions for every 1 gigabyte of worker memory. This value will never exceed the value you set for maxpartitions. Example If your total memory is 10 GB and you have 6 partitions for every 1 GB of worker memory, then you would have 60 partitions in total. |
6 |
Tip We highly recommend reviewing the Admin Limit values of totalworkers, maxworkercores, and maxworkermemory with a DQ admin on your internal team to determine the requirements specific to your environment. The recommended values above are based on benchmarks we've observed.
| Spark Resource | Description | Default Value |
|---|---|---|
| No. of Executors |
The total number of Spark workers available. |
1 |
| Memory |
The amount of memory allocated per Spark executor for Spark processing. |
1 GB |
| No. of Cores |
The number of cores per Spark executor. |
1 |
| Driver Memory |
Total memory allocated per Spark driver. |
1 GB |
| Partition Number |
The number of chunks of the dataset to split evenly across the Spark executors. |
0 |
Tip While you can edit the application properties, we consider it best practice to use the default sizing recommendations.
Known limitations
- There is a limitation with the estimator where it has limited ability to estimate the required resources of jobs with rules referencing secondary datasets or that have lookback enabled for outliers and patterns.
-
Keep in mind that Spark allocates overhead memory on top of the requested memory. For example, an executor pod configured with 6GB of memory may actually request 6.8GB of memory. For more information, go to Apache Spark Memory Management.