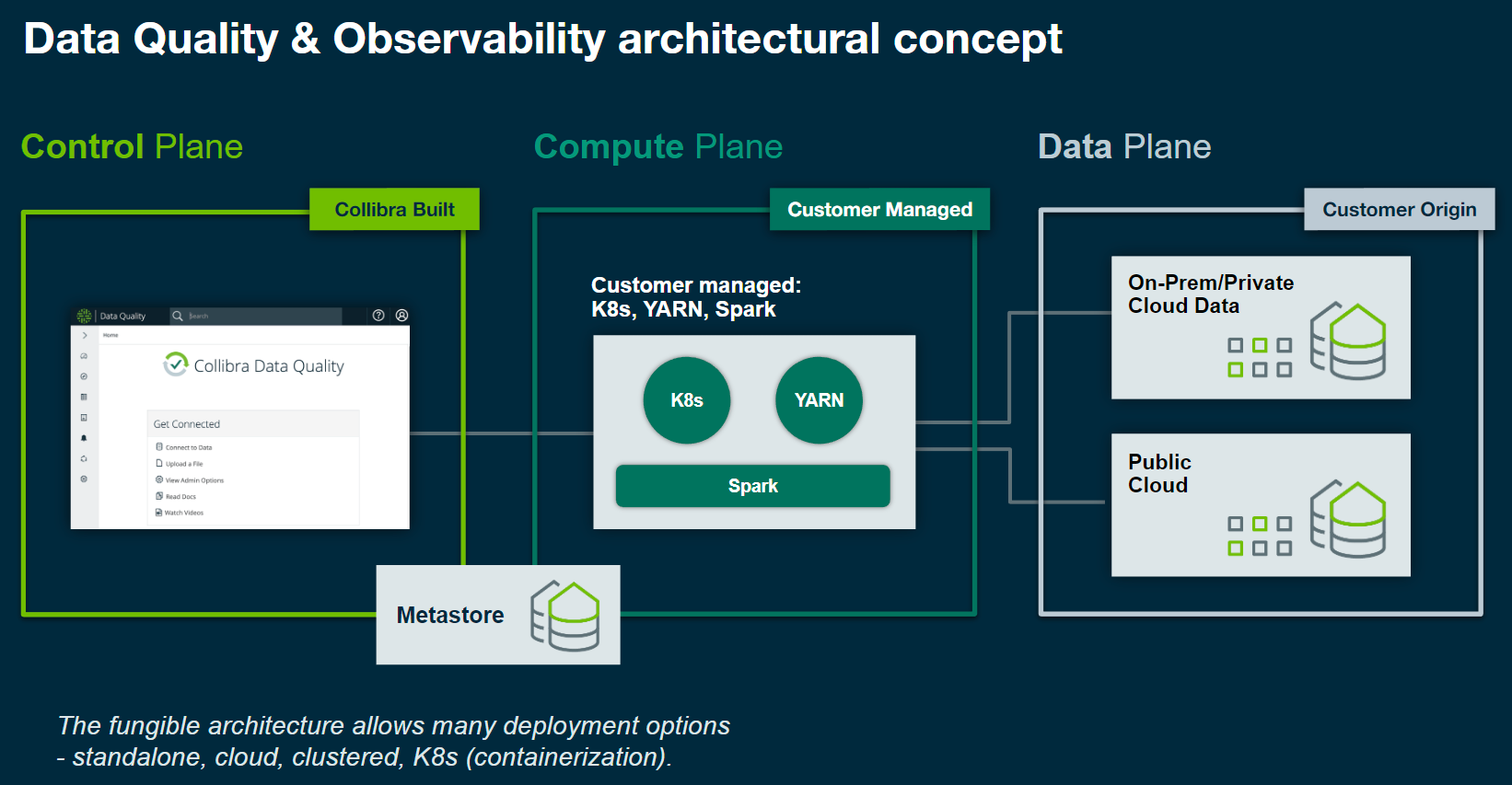
Collibra DQ Architecture
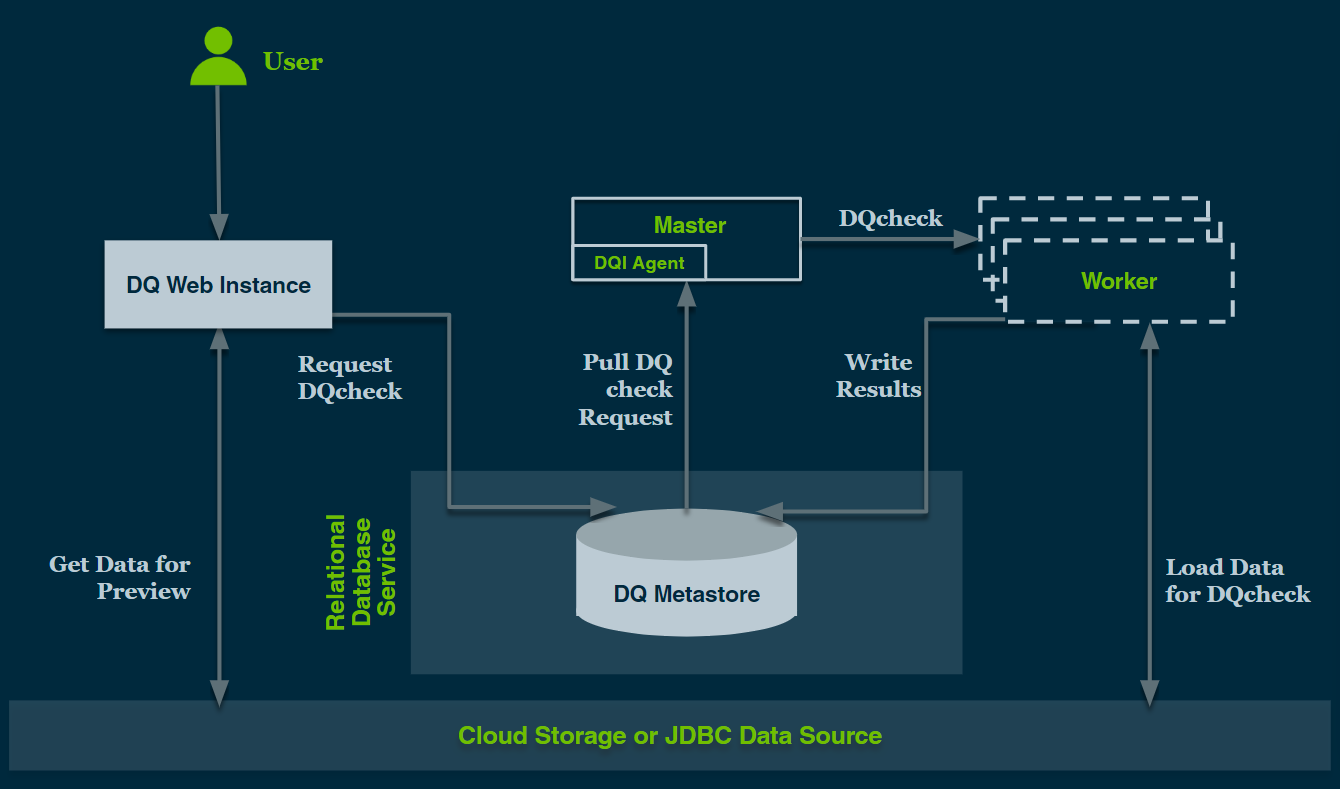
Collibra DQ Hadoop Deployment Diagram
Collibra DQ Kubernetes Deployment Diagram
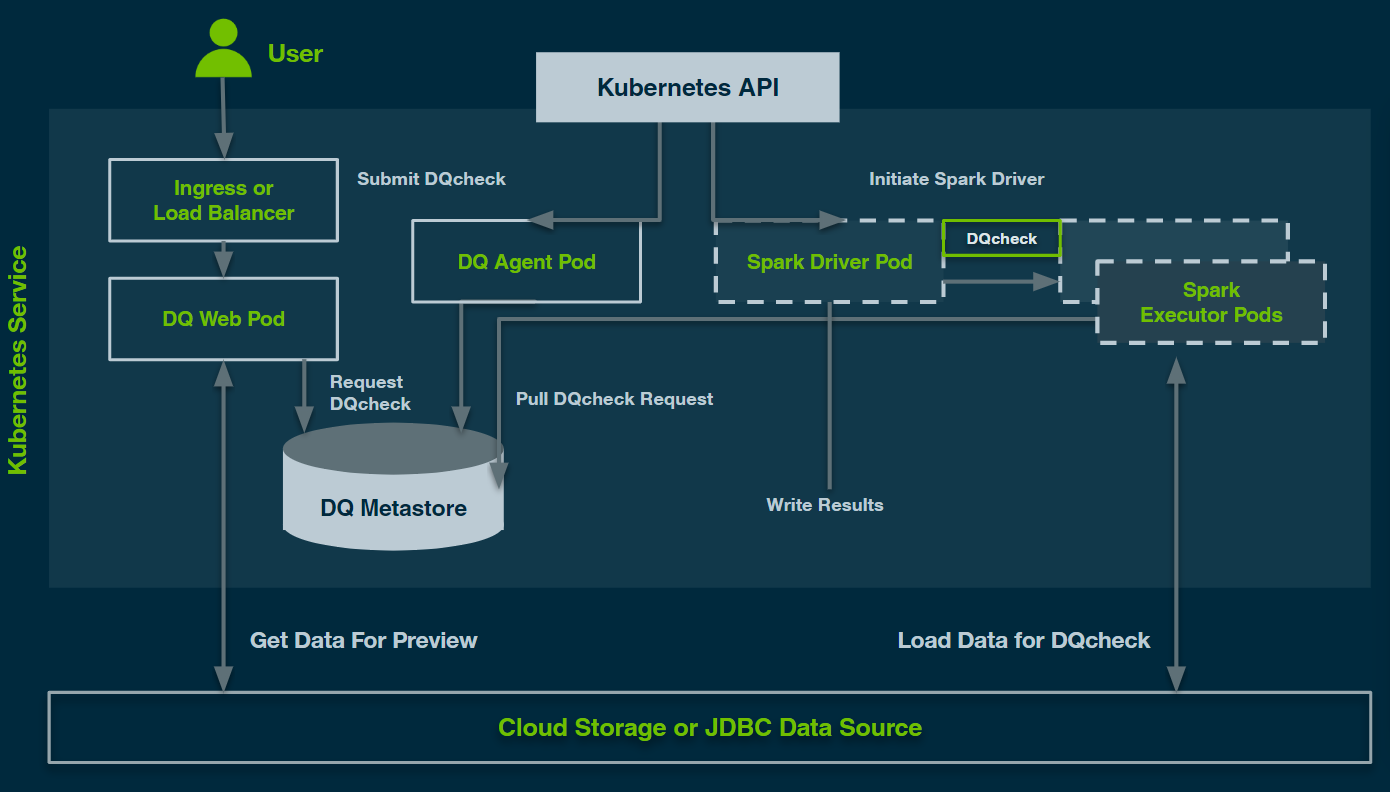
Note For Kubernetes deployments of Collibra DQ should use Auto Scaling and Spot instances to further increase efficiency and reduce cost.