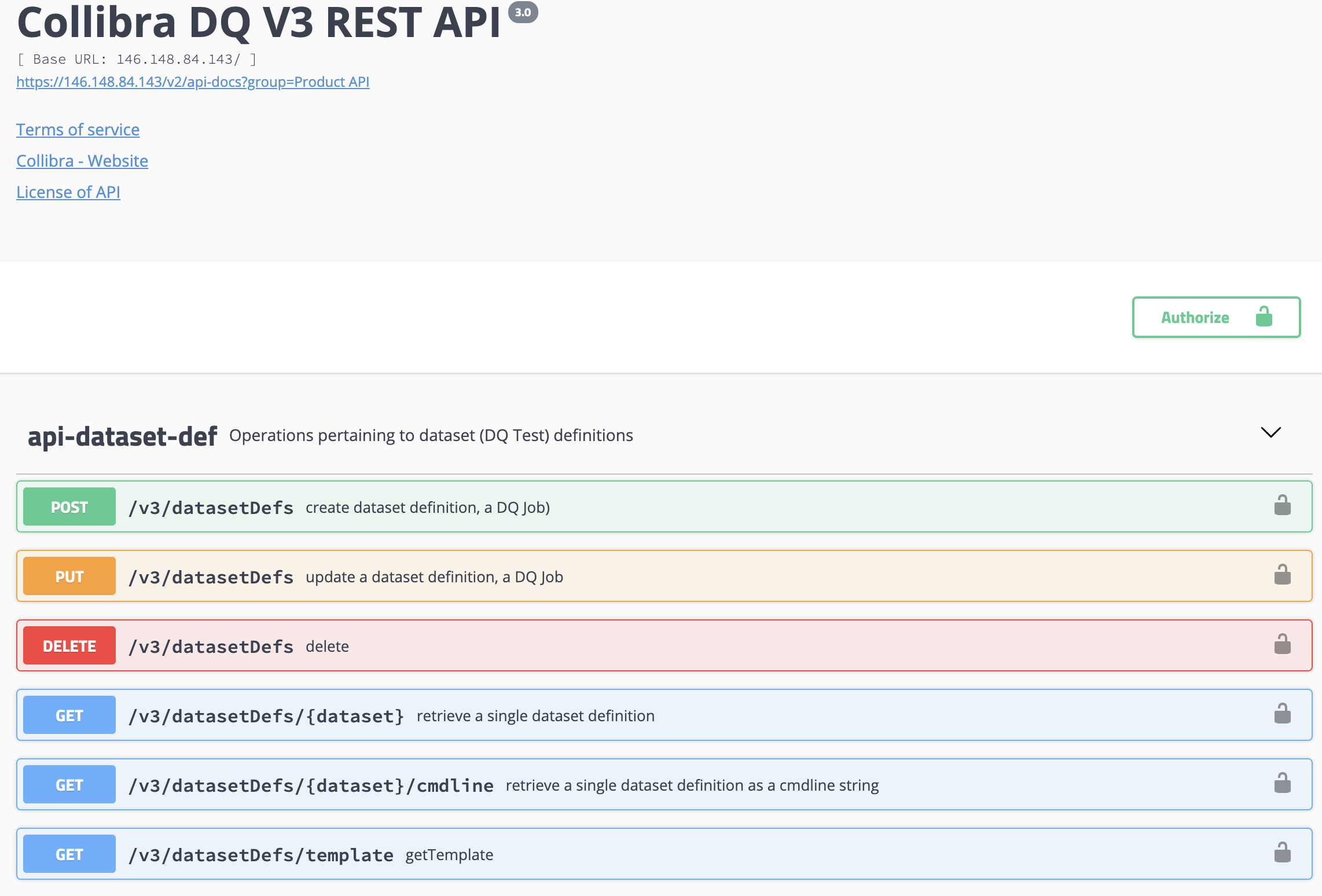
All REST APIs are available inside the application under admin section. The APIs can be used against the application in live working mode, which is preferred over documentation of APIs because it means the API works and was tested at compile time versus documentation time.
Product API
The product API is for end-users who want to interact with the official and supported API. You can also generate a client side SDK from the API with four steps below.
#psuedo code example REST API
dataset = 'public.nyse'
runId = '2021-03-05'
#SAVE datasetDef
dataset = POST /v3/datasetDefs/ {json_datasetDef}
#UPDATE datasetDef
dataset = PUT /v3/datasetDefs/ {json_datasetDef}
#RUN JOB
jobId = POST /v3/jobs/run/{dataset},{runDate}
#CHECK STATUS
status = /v3/jobs{jobId}/status
#GET DQ FINDINGS
findings = /v3/jobs/{jobId}/findingsJWT Token For Auth #
import requests
import json
url = "http://localhost:9000/auth/signin"
payload = json.dumps({
"username": "<user>",
"password": "<pass>",
"iss": "public"
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)curl --location --request POST 'http://localhost:9000/auth/signin' \
--header 'Content-Type: application/json' \
--data-raw '{
"username": "<user>",
"password": "<pass>",
"iss": "public"
}'Python Example
Alternatively, you can use the rest endpoints directly. This example shows how it can be done with Python.
- Create a dataset def:
- Using the UI (Explorer) or
- Using the dataset-def-api (https://<ip>/swagger-ui.html#/dataset-def-api)
- Confirm your Python environment has the appropriate modules and imports.
- Fill-in the variables and customize to your preference:
- url, user and pass
- dataset, runDate, and agentName
import requests
import json
# Authenticate
owl = "https://<url>"
url = "https://<url>/auth/signin"
payload = json.dumps({
"username": "<user>", # Edit Here
"password": "<pass>", # Edit Here
"iss": "public" # Edit Here
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload, verify=False)
owl_header = {'Authorization': 'Bearer ' + response.json()['token']}
# Run
dataset = '<your_dataset_name>' # Edit Here
runDate = '2021-08-08' # Edit Here
agentName = '<your_agent_name' # Edit Here
response = requests.post(
url = owl + '/v3/jobs/run?agentName='+agentName+'&dataset='+dataset+'&runDate='+runDate,
headers=owl_header,
verify=False
)
jobId = str(response.json()['jobId'])
# Status
for stat in range(100):
time.sleep(1)
response = requests.get(
url = owl + '/v3/jobs/'+jobId,
headers=owl_header,
verify=False
)
job = response.json()
if job['status'] == 'FINISHED':
break
# Results
response = requests.get(
url = owl + '/v3/jobs/'+jobId+'/findings',
headers=owl_header,
verify=False
)
print(response.json())This assumes you have created a dataset definition using the UI or from the template.
Command Line instead of JSON dataset def
You can run a similar job submission using the cmd line. Please note it is easiest to get the saved command line from the dataset-def-api /v3/datasetDefs//cmdline (with proper escaping) and passed to the /v3/jobs/runCmdLine.
Breaking Down The Sections
Submit the Job
Send in a data set name, date and agent to submit the job. This kicks off the engine to go do the work.
# Run
dataset = 'API_V3'
runDate = '2021-08-08'
agentName = 'owldq-owl-agent-owldq-dev-0'
response = requests.post(
url = owl + '/v3/jobs/run?agentName='+agentName+'&dataset='+dataset+'&runDate='+runDate,
headers=owl_header
)
jobId = str(response.json()['jobId'])Get the Status
Using the jobId returned from the job submission, you can check the status. In the example above, there is an interval to wait for the job to complete. You can create your own logic and orchestrate more precisely.
response = requests.get(
url = owl + '/v3/jobs/'+jobId,
headers=owl_header
)Get the Results
Using the same jobId returned from the job submission, you can check the results. You will get a detailed json object with all the capabilities and detections in one payload. This is where you would decision, based on your organization and process.
response = requests.get(
url = owl + '/v3/jobs/'+jobId,
headers=owl_header
)Python Example Raw
import requests
import json
# Variables
owl = 'https://<ip_address>' #Edit
user = '<user>' #Edit
password = '<password>' #Edit
tenant = 'public' #Edit
dataset = '<your_dataset_name>' #Edit
runDate = '2021-08-08' #Edit
agentName = 'your_agent_name' #Edit
# Authenticate
url = owl+'/auth/signin'
payload = json.dumps({"username": user, "password": password, "iss": tenant })
headers = {'Content-Type': 'application/json'}
response = requests.request("POST", url, headers=headers, data=payload, verify=False)
owl_header = {'Authorization': 'Bearer ' + response.json()['token']}
# Run
response = requests.post(url = owl + '/v3/jobs/run?agentName='+agentName+'&dataset='+dataset+'&runDate='+runDate, headers=owl_header, verify=False)
jobId = str(response.json()['jobId'])
# Status
for stat in range(100):
time.sleep(1)
response = requests.get(url = owl + '/v3/jobs/'+jobId, headers=owl_header, verify=False)
status = response.json()['status']
if status == 'FINISHED':
break
# Results
response = requests.get(url = owl + '/v3/jobs/'+jobId+'/findings', headers=owl_header, verify=False)Internal API
Collibra DQ also exposes the internal API so that all potential operations are available. The caveat is that these calls may change over time or expose underlying functionality.
.png)
.png)
Dataset Definition
The JSON for the full dataset definition. It can be more terse to send in the cmdline string of just the variables you use for your DQ Job.
-df "yyyy/MM/dd" -owluser <user> -numexecutors 1 -executormemory 1g \
-f s3a://s3-datasets/dataset.csv -h <host>:5432/dev?currentSchema=public \
-fq "select * from dataset" -drivermemory 1g -master k8s:// -ds dataset_csv_1 \
-deploymode cluster -bhlb 10 -rd "2021-04-01" -fullfile -loglevel INFO -cxn s3test5 \
-sparkprinc [email protected] -sparkkeytab /tmp/user2.keytab {
"dataset": "",
"runId": "",
"runIdEnd": "",
"runState": "DRAFT",
"passFail": 1,
"passFailLimit": 75,
"jobId": 0,
"coreMaxActiveConnections": null,
"linkId": null,
"licenseKey": "",
"logFile": "",
"logLevel": "",
"hootOnly": false,
"prettyPrint": true,
"useTemplate": false,
"parallel": false,
"plan": false,
"dataPreviewOff": false,
"datasetSafeOff": false,
"obslimit": 300,
"pgUser": "",
"pgPassword": "",
"host": null,
"port": null,
"user": "anonymous : use -owluser",
"alertEmail": null,
"scheduleTime": null,
"schemaScore": 1,
"optionAppend": "",
"keyDelimiter": "~~",
"agentId": null,
"load": {
"readonly": false,
"passwordManager": null,
"alias": "",
"query": "",
"key": "",
"expression": "",
"addDateColumn": false,
"zeroFillNull": false,
"replaceNulls": "",
"stringMode": false,
"operator": null,
"dateColumn": null,
"transform": null,
"filter": "",
"filterNot": "",
"sample": 1,
"backRun": 0,
"backRunBin": "DAY",
"unionLookBack": false,
"cache": true,
"dateFormat": "yyyy-MM-dd",
"timeFormat": "HH:mm:ss.SSS",
"timestamp": false,
"filePath": "",
"fileQuery": "",
"fullFile": false,
"fileHeader": null,
"inferSchema": true,
"fileType": null,
"delimiter": ",",
"fileCharSet": "UTF-8",
"skipLines": 0,
"avroSchema": "",
"xmlRowTag": "",
"flatten": false,
"handleMaps": false,
"handleMixedJson": false,
"multiLine": false,
"lib": "",
"driverName": null,
"connectionName": "",
"connectionUrl": "",
"userName": "",
"password": "",
"connectionProperties": {},
"hiveNative": null,
"hiveNativeHWC": false,
"useSql": true,
"columnName": null,
"lowerBound": null,
"upperBound": null,
"numPartitions": 0,
"escapeWithBackTick": false,
"escapeWithSingleQuote": false,
"escapeWithDoubleQuote": false,
"escapeCharacter": "",
"hasHeader": true
},
"outliers": [
{
"id": null,
"on": false,
"only": false,
"lookback": 5,
"key": null,
"include": null,
"exclude": null,
"dateColumn": null,
"timeColumn": null,
"timeBin": "DAY",
"timeBinQuery": "",
"categorical": true,
"by": null,
"limit": 300,
"minHistory": 3,
"historyLimit": 5,
"score": 1,
"aggFunc": "",
"aggQuery": "",
"query": "",
"q1": 0.15,
"q3": 0.85,
"categoricalColumnConcatenation": false,
"limitCategorical": null,
"measurementUnit": "",
"multiplierUpper": 1.35,
"multiplierLower": 1.35,
"record": true,
"filter": null,
"combine": true,
"categoricalConfidenceType": "",
"categoricalTopN": 3,
"categoricalBottomN": 2,
"categoricalMaxConfidence": 0.02,
"categoricalMaxFrequencyPercentile": 0.25,
"categoricalMinFrequency": 1,
"categoricalMinVariance": 0,
"categoricalMaxCategoryN": 1,
"categoricalParallel": true,
"categoricalAlgorithm": "",
"categoricalAlgorithmParameters": {}
}
],
"outlier": {
"id": null,
"on": false,
"only": false,
"lookback": 5,
"key": null,
"include": null,
"exclude": null,
"dateColumn": null,
"timeColumn": null,
"timeBin": "DAY",
"timeBinQuery": "",
"categorical": true,
"by": null,
"limit": 300,
"minHistory": 3,
"historyLimit": 5,
"score": 1,
"aggFunc": "",
"aggQuery": "",
"query": "",
"q1": 0.15,
"q3": 0.85,
"categoricalColumnConcatenation": false,
"limitCategorical": null,
"measurementUnit": "",
"multiplierUpper": 1.35,
"multiplierLower": 1.35,
"record": true,
"filter": null,
"combine": true,
"categoricalConfidenceType": "",
"categoricalTopN": 3,
"categoricalBottomN": 2,
"categoricalMaxConfidence": 0.02,
"categoricalMaxFrequencyPercentile": 0.25,
"categoricalMinFrequency": 1,
"categoricalMinVariance": 0,
"categoricalMaxCategoryN": 1,
"categoricalParallel": true,
"categoricalAlgorithm": "",
"categoricalAlgorithmParameters": {}
},
"pattern": {
"id": null,
"only": false,
"lookback": 5,
"key": null,
"dateColumn": null,
"include": null,
"exclude": null,
"score": 1,
"minSupport": 0.000033,
"confidence": 0.6,
"limit": 30,
"query": "",
"filter": null,
"timeBin": "DAY",
"on": false,
"match": true,
"lowFreq": false,
"bucketLimit": 450000,
"deDupe": true
},
"patterns": [
{
"id": null,
"only": false,
"lookback": 5,
"key": null,
"dateColumn": null,
"include": null,
"exclude": null,
"score": 1,
"minSupport": 0.000033,
"confidence": 0.6,
"limit": 30,
"query": "",
"filter": null,
"timeBin": "DAY",
"on": false,
"match": true,
"lowFreq": false,
"bucketLimit": 450000,
"deDupe": true
}
],
"dupe": {
"on": false,
"only": false,
"include": null,
"exclude": null,
"depth": 0,
"lowerBound": 99,
"upperBound": 100,
"approximate": 1,
"limitPerDupe": 15,
"checkHeader": true,
"filter": null,
"ignoreCase": true,
"score": 1,
"limit": 300
},
"profile": {
"on": true,
"only": false,
"include": null,
"exclude": null,
"shape": true,
"correlation": null,
"histogram": null,
"semantic": null,
"limit": 300,
"histogramLimit": 0,
"score": 1,
"shapeTotalScore": 0,
"shapeSensitivity": 0,
"shapeMaxPerCol": 0,
"shapeMaxColSize": 0,
"shapeGranular": null,
"behavioralDimension": "",
"behavioralDimensionGroup": "",
"behavioralValueColumn": "",
"behaviorScoreOff": false,
"behaviorLookback": 10,
"behaviorMinSupport": 4,
"profilePushDown": null,
"behaviorRowCheck": true,
"behaviorTimeCheck": true,
"behaviorMinValueCheck": true,
"behaviorMaxValueCheck": true,
"behaviorNullCheck": true,
"behaviorEmptyCheck": true,
"behaviorUniqueCheck": true,
"adaptiveTier": null
},
"source": {
"on": false,
"only": false,
"validateValues": false,
"matches": false,
"sourcePushDownCount": false,
"include": null,
"exclude": null,
"includeSrc": null,
"excludeSrc": null,
"key": null,
"map": null,
"score": 1,
"limit": 30,
"dataset": "",
"driverName": "",
"user": "",
"password": "",
"passwordManager": "",
"connectionName": "",
"connectionUrl": "",
"query": "",
"lib": "",
"checkType": true,
"checkCase": false,
"validateValuesFilter": "",
"validateSchemaOrder": false,
"connectionProperties": {},
"filePath": "",
"fileQuery": "",
"fullFile": false,
"header": null,
"skipLines": 0,
"inferSchema": true,
"fileType": null,
"delimiter": ",",
"fileCharSet": "UTF-8",
"avroSchema": "",
"xmlRowTag": "",
"flatten": false,
"handleMaps": false,
"handleMixedJson": false,
"multiLine": false,
"hasHeader": true
},
"rule": {
"on": true,
"only": false,
"lib": null,
"name": "",
"absoluteScoring": false,
"ruleBreakPreviewLimit": 6
},
"colMatch": {
"colMatchParallelProcesses": 3,
"colMatchDurationMins": 20,
"colMatchBatchSize": 2,
"level": "exact",
"fuzzyDistance": 1,
"connectionList": []
},
"spark": {
"numExecutors": 3,
"driverMemory": "",
"executorMemory": "",
"executorCores": 1,
"conf": "",
"queue": "",
"master": "local[*]",
"principal": "",
"keyTab": "",
"deployMode": "",
"jars": null,
"packages": null,
"files": null
},
"env": {
"jdbcPrincipal": "",
"jdbcKeyTab": ""
},
"record": {
"on": false,
"in": "",
"notIn": "",
"include": null,
"percDeltaLimit": 0.1,
"score": 1
},
"transforms": [],
"pipeline": []
}
Generate Client SDK
- Go to https://editor.swagger.io/.
- Click File Import URL.
- Paste a URL that looks like this https://<host>/v2/api-docs?group=Product%20API.
- Click generate client (python, java, scala, C#).
#Python SDK Example
#GET CMDLINE
cmdLine = get_job_cmdline(dataset)
#SUBMIT JOB
job_id = run(dataset, run_date)
#CHECK STATUS
status = get_job_status(job_id)
#GET DQ ISSUES
status = get_job_findings(dataset, run_date)