Introduction
In this page we will demonstrate two paths to run a spark submit job on Databricks's cluster. The first approach is to run a DQ spark submit job using Databricks UI and the second approach is by invoking Databricks rest API.
Note These are only examples to demonstrate how to achieve DQ spark submit to Databricks's cluster. These paths are not supported in production and DQ team does not support any bug coverages or professional services or customer questions for these flows.
Limitations
There are a few limitation to spark-submit jobs in Databricks listed in this section: https://docs.databricks.com/jobs.html#create-a-job. Also, spark-submit is only on new clusters from both the UI via Jobs or calling the REST APIs. See Step 4 in: https://docs.databricks.com/jobs.html#create-a-job where it lists that spark-submit is handled by new clusters only.
Steps to create and run a spark submit job from Databricks UI:
- Grant Collibra DQ Database access to your instance of Databricks.
- Upload DQ jars in Databricks File System (DBFS).
- Set up environment variables for your new cluster.
- Prepare the DQ JSON payload.
- Create and Run your job.
- View the status and result of your job from the DQ Jobs page.
Database access
To begin, ensure that sure your Databricks instance has access to the DQ Database.
The entire subnet must be whitelisted to connect to the database. As specified in Databricks' documentation on subnets, Databricks must have access to at least two subnets for each database. To connect to the two Databricks subnets where the nodes will be instantiated, you must allow AWS to whitelist your IP address range.
Upload DQ's jars in DBFS
The jars should be manually uploaded in Databricks file system. The steps can be found on Databricks website: https://docs.databricks.com/data/databricks-file-system.html#access-dbfs.
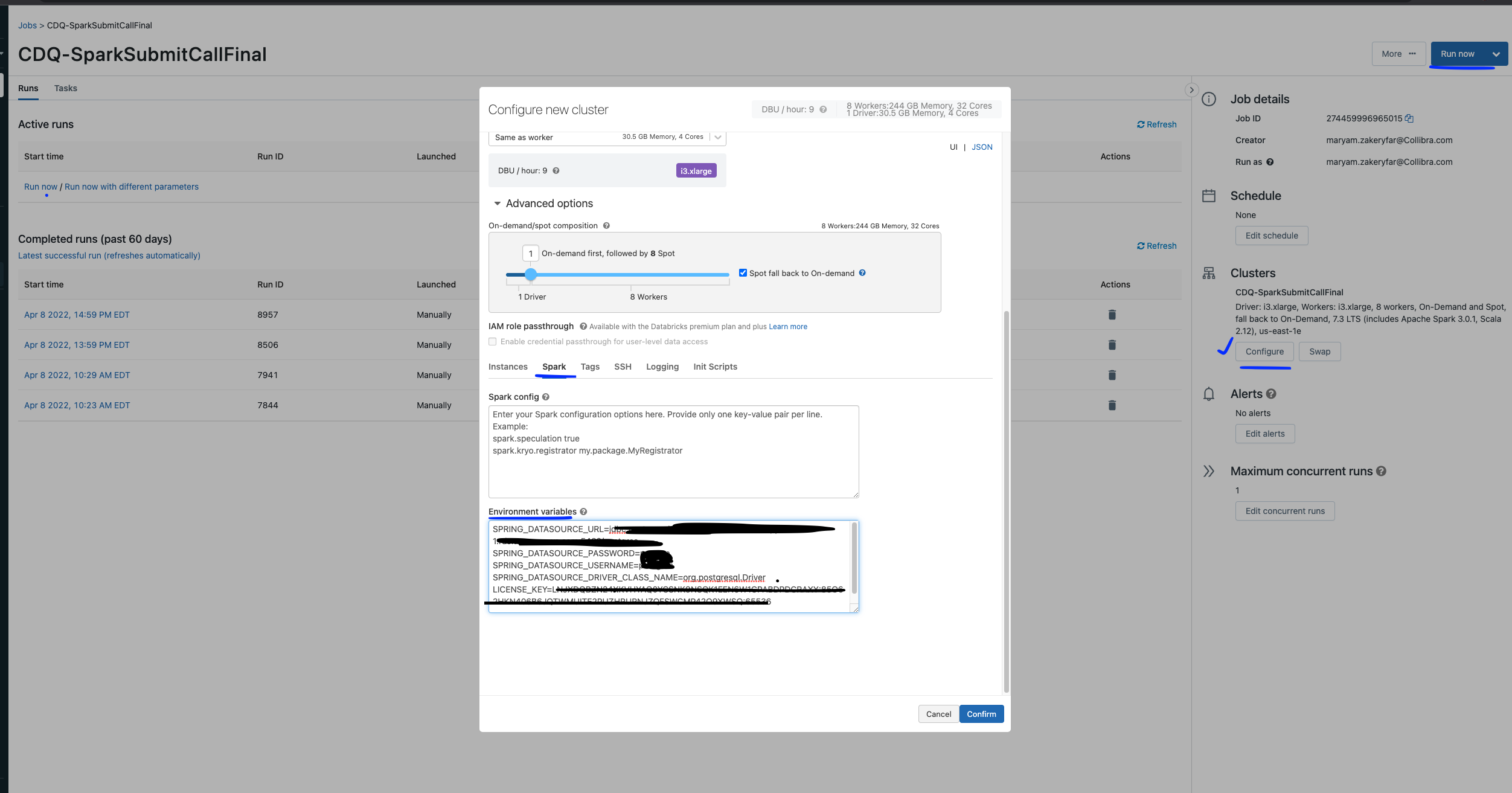
Environment variables for the new cluster:
Here is the documentation from Databricks about how to set up environment variables: https://docs.databricks.com/clusters/configure.html#environment-variables
These CDQ environment variables should be set on the new cluster:SPRING_DATASOURCE_URL=xx\ SPRING_DATASOURCE_USERNAME=xx\ SPRING_DATASOURCE_DRIVER_CLASS_NAME=xx\ LICENSE_KEY=xx // This is DQ's license key
JSON payload
Once the above steps are completed, you can submit a spark submit job with DQ's parameters. Payload parameters can be from DQ's web Run command. You can copy and paste the parameters to prepare a JSON payload. Here is one sample:
"--class",
"com.owl.core.cli.OwlCheck",
"dbfs:/FileStore/cdq/owl-core-2022.02-SPARK301-jar-with-dependencies.jar",
"-lib",
"dbfs:/FileStore/cdq/owl/drivers/postgres",
"-q",
"select * from xx.xxx",
"-bhlb",
"10",
"-rd",
"2022-03-16",
"-driver",
"owl.com.org.postgresql.Driver",
"-drivermemory",
"4g",
"-cxn",
"metastore",
"-h",
"xxxx.xxxxxx.amazonaws.com:xxxx/postgres",
"-ds",
"public.agent_2",
"-deploymode",
"cluster",
"-owluser",
"admin"
]Run the job
Once you have completed the above steps, you can create a spark submit job through Databricks UI.
You can then add the environment variables to the cluster and click Run on Databricks UI.
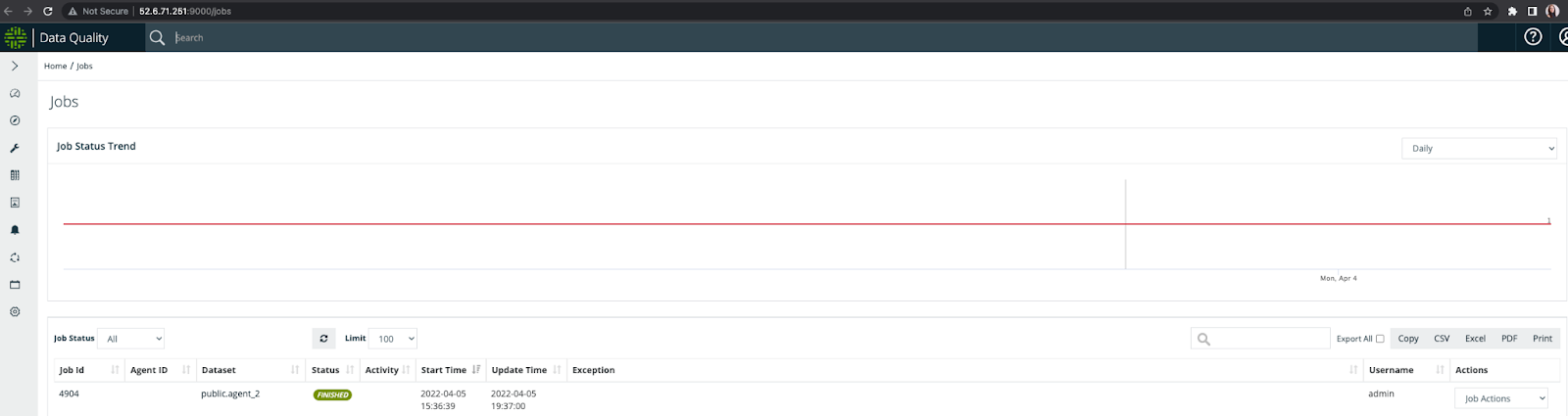
Check the result in DQ web:
Once the job is submitted, you can login to your DQ web instance and check the job in the Jobs page.
Spark submit by invoking Databricks REST API
There are public REST APIS available for the Jobs API, including the latest version.
For this path we need to do the steps 1-4 of the the previous section and then call directly the REST API using Postman, or your preferred API testing tool. We assume that as per step 2, CDQ jars are uploaded to the DBFS path in the location dbfs:/FileStore/cdq.
Also JDBC postgres driver should be uploaded to DBFS. For example: dbfs:/FileStore/cdq/owl/drivers/postgres
Steps:
- Prepare the DQ JSON Payload.
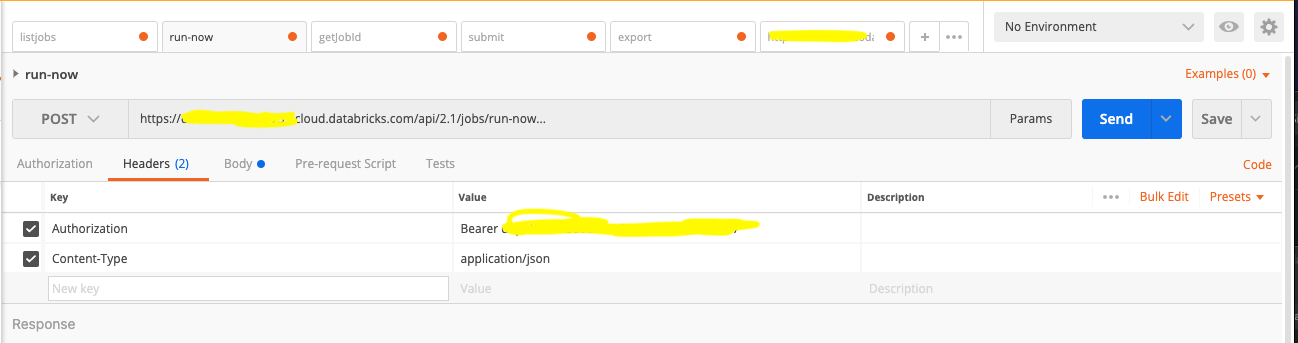
- Authenticate the Databricks REST API.
JSON payload
Sample JSON payload:
POST /api/2.1/jobs/runs/submit HTTP/1.1Host: xxxxxx.cloud.databricks.com\ `Content-Type: application/json`\ `Authorization: Bearer ~~xxxxxxxxxxxxx~~\ Cache-Control: no-cache\ Postman-Token: xxxxxxxx`
{
"tasks": [
{
"task_key": "CDQ-SparkSubmitCallFinal",
"spark_submit_task": {
"parameters": [
"--class",
"com.owl.core.cli.OwlCheck",
"dbfs:/FileStore/cdq/owl-core-2022.02-SPARK301-jar-with-dependencies.jar",
"-lib",
"dbfs:/FileStore/cdq/owl/drivers/postgres",
"-q",
"select * from public.agent",
"-bhlb",
"10",
"-rd",
"2022-03-16",
"-driver",
"owl.com.org.postgresql.Driver",
"-drivermemory",
"4g",
"-cxn",
"metastore",
"-h",
"xxxs.amazonaws.com:xxx/postgres",
"-ds",
"public.agent_2",
"-deploymode",
"cluster",
"-owluser",
"admin"
]
},
"new_cluster": {
"cluster_name": "",
"spark_version": "7.3.x-scala2.12",
"aws_attributes": {
"zone_id": "us-east-1e",
"first_on_demand": 1,
"availability": "SPOT_WITH_FALLBACK",
"spot_bid_price_percent": 100,
"ebs_volume_count": 0
},
"node_type_id": "i3.xlarge",
"spark_env_vars": {
"SPRING_DATASOURCE_URL": "jdbc:postgresql://xxx-xx-xxs.amazonaws.com:xx/postgres",
"SPRING_DATASOURCE_PASSWORD": "xxx",
"SPRING_DATASOURCE_USERNAME": "xxx",
"SPRING_DATASOURCE_DRIVER_CLASS_NAME": "org.postgresql.Driver",
"LICENSE_KEY": "xxxx"
},
"enable_elastic_disk": false,
"num_workers": 8
},
"timeout_seconds": 0
}
]
}Values to be updated in above payload are:
Cluster variables:"SPRING_DATASOURCE_URL":"SPRING_DATASOURCE_PASSWORD":"SPRING_DATASOURCE_USERNAME":"LICENSE_KEY": //CDQ License key
``
CDQ variables\ Users can customize the variables based on the activity they choose from CDQ Web. They can copy the variables from Run CMD option of their DQ job and paste it in their Json message. ``
Authenticate the Databricks REST API
Here is the Databricks documentation about how to create a personal access token: https://docs.databricks.com/dev-tools/api/latest/authentication.html
View the job's result in DQ web
You can view the result of your job run by navigating to the DQ Jobs page.