You can add the Databricks Unity Catalog capability to Edge or Collibra Cloud site to enable metadata synchronization between Databricks and Collibra.
- Tip
-
- If you're looking for information on how to create technical lineage for Databricks Unity Catalog via Edge, go to the technical lineage for Databricks Unity Catalog documentation.
Prerequisites
In your Collibra environment:
- You have created a connection to Databricks in your Edge or Collibra Cloud site.
- If you want to profile and classify the data or request sample data for assets created via the Databricks Unity Catalog integration, make sure you have created a JDBC Databricks connection.
For the steps on how to allow for sampling, profiling, and classification, go to Steps: Integrate Databricks Unity Catalog via Edge. - You have a global role that has the Manage connections and capabilities global permission, for example, Edge integration engineer.
- When Status validation is activated for your Collibra environment, the synchronization does not complete if your integration's Default Asset Status is set to a status that is not assigned to the ingested asset types. For example, Implemented is no longer assigned to AI-related asset types. To avoid this, do one of the following:
- In your integration's Synchronization configuration or Metadata inbound tab, set Default Asset Status to No Status.
- In Collibra Console, set Status validation to False (default). This setting is in the Knowledge Graph Validation group of the Data Governance Center service configuration.
Steps
- Open a site.
-
On the main toolbar, click
 →
→
 Settings.
Settings.
The Settings page opens. -
In the tab pane, click Edge.
The Sites tab opens and shows a table with an overview of your sites. - In the table, click the name of the site whose status is Healthy.
The site page opens.
-
On the main toolbar, click
- In the Capabilities section, click Add capability.
The Add capability page appears. - Select the Databricks Unity Catalog synchronization capability template.
- Enter the required information.
Field Description Required Name
The name of the capability.
 Yes
Yes
Description
The description of the capability.
 No
Databricks Connection
No
Databricks ConnectionThe Databricks Workspace connection to be used. Yes
JDBC Databricks Connection The JDBC Databricks connection to be used.
Add this connection if you also want to allow sampling, profiling, and classification of assets created via the Databricks Unity Catalog integration (in preview).
No
Create additional capabilities automatically (in preview) Choose which capabilities to create automatically during synchronization if they do not already exist. Select one of the following options:
- Do not create additional capabilities: No additional capabilities are created.
- Create JDBC ingestion, profiling and classification capabilities automatically: The following capabilities are created automatically, Catalog JDBC Ingestion, JDBC Profiling, and Catalog JDBC Classification. This is the default value.
- Create JDBC ingestion, profiling and classification capabilities automatically: The following capabilities are created automatically, Catalog JDBC Ingestion, JDBC Profiling, Catalog JDBC Classification, and Catalog JDBC Sampling.
No
Save input metadataIf you select this option, the metadata extracted from the data source will be saved in a file that can be used for troubleshooting. Select this option only on request of Collibra Support. No
Exclude Schemas (will be removed soon, use domain mapping instead)Comma-separated list of the schemas that you don't want to integrate.
No
(deprecated) Filters and Domain MappingImportant This field is deprecated in the latest UI. You can now define the mappings in the integration configuration.
If you have existing mappings here, they will continue to work. However, we advise you to move them to the integration configuration.Text in JSON format to include or exclude databases and schemas, and to configure domain mappings.
- The text must be in JSON format and can contain an include and an exclude block. You can use any JSON validator to verify the format. Collibra is not responsible for the privacy, confidentiality, or protection of the data you submit to such JSON validators, and has no liability for such use.
- In the include block, you can specify the domain in which specific catalogs or schemas must be ingested. The format is:
“Catalog/Database > schema ”: “domain ID”. For example,"HR > address-schema": "30000000-0000-0000-0000-000000000000". - In the exclude block, you can specify the catalogs or schemas that you don't want to ingest. For example,
"* > test". - The exclude block has priority over the include block.
- If the include block is not present, we ingest all assets into new domains.
- If there is no explicit domain mapping for a schema, we use the domain specified for the database.
- You can use the keyword
defaultas a domain ID. In that case, the catalog or schema will be ingested in a new domain. - A match with a database has priority over a match with a schema.
- The integration fails before the synchronization starts, if one or more domain IDs specified in the include block don't exist.
- The integration fails before the synchronization starts if a domain ID is left empty in the include block.
- You can use the ? and * wildcards in the catalog and schema names. If a catalog or schema matches multiple lines, the most detailed match is taken into account.
Show exampleExample{"include": {"HR": "20000000-0000-0000-0000-000000000000",
"HR > address-schema": "30000000-0000-0000-0000-000000000000","Orders > fk*": "40000000-0000-0000-0000-000000000000",
"Orders > *": "50000000-0000-0000-0000-000000000000",
"* > profiling": "60000000-0000-0000-0000-000000000000",
"sales": "default"},"exclude": ["testDB",
" * > information_schema"]}In this example:
- The "HR" Database asset will be ingested into the domain with ID "20000000-0000-0000-0000-000000000000".
- Assets from the "HR" database will be ingested into the domain with ID "20000000-0000-0000-0000-000000000000". However, all assets from the "HR > address-schema" schema will be ingested into the domain with id "30000000-0000-0000-0000-000000000000".
- The "Orders" Database asset will be ingested in the same asset as the System asset.
- All assets from the "Orders” database with schemas starting with fk (fk*) will be ingested into the domain with ID "40000000-0000-0000-0000-000000000000", and all other assets from the "Orders” database will be ingested into the domain with ID "50000000-0000-0000-0000-000000000000".
- The "sales" Database asset and all assets from the "sales" database will be ingested in the same domain as the System asset.
- Assets from the "profiling" schema will be ingested into the domain with ID "60000000-0000-0000-0000-000000000000". However, the "profiling" schema in the database "Orders" will be ingested in the domain with ID "50000000-0000-0000-0000-000000000000" because a database match has priority over a schema match.
- All assets from the "testDB” database will be excluded.
- All assets from the “information_schema” schema in all databases will be excluded.
No
(deprecated) Extensible Properties Mapping Via the Extensible Properties Mapping field, Databricks Unity Catalog allows you to add additional properties to Catalog, Schema, and Table objects.
Important- This field is deprecated in the latest UI. You can now define the mappings in the integration configuration. If you have existing mappings here, they will continue to work. However, we advise you to move them to the integration configuration.
- If you use this feature, make sure to set up all required characteristic assignments for the asset types.
Three possible JSON formats are available.
- Version 0.1: This version allows you to ingest custom properties only. You can ingest the values from the Properties field from Catalog, Schema, and Table objects into specific attributes in Collibra assets. You do this by adding the mapping between the Properties fields for the objects in Databricks Unity Catalog and the Collibra attribute IDs to ingest the data in, using a JSON string.
- The text must be in JSON format and can contain a Catalogs, Schemas, and Tables block. The Catalogs block refers to Database assets, the Schemas block to Schema assets, and the Tables block to Table assets.
- In each block, you specify the property name and the attribute ID to which you want to map the value in the property. The format is:
"[property name]": "[attribute resource ID]". For example,"Description from source system": "00000000-0000-0000-0001-000500000074".
Show exampleExample{"catalogs": {"color": "00000000-0000-0000-0000-000000001234","Description from source system": "00000000-0000-0000-0001-000500000074"},"schemas": {"File Location": "00000000-0000-0000-0001-000500000004"},"tables": {"delta.lastCommitTimestamp": "00000000-0000-0000-0000-000000003114"}}In this example:
- In the Database assets that we create, we'll add the Color value in attribute 00000000-0000-0000-0000-000000001234, and the Description from Source value in attribute 00000000-0000-0000-0001-000500000074.
- In the Schema assets that we create, we'll add the File Location value in attribute 00000000-0000-0000-0001-000500000004.
- In the Table assets that we create, we'll add the delta.lastCommitTimestamp value in attribute 00000000-0000-0000-0000-000000003114.
- The text must be in JSON format and can contain a Catalogs, Schemas, and Tables block. The Catalogs block refers to Database assets, the Schemas block to Schema assets, and the Tables block to Table assets.
- Version 0.2: This version allows you to ingest both default system properties and custom properties. You can ingest most values from the Details page from Catalog, Schema, and Table objects into specific attributes in Collibra assets. You do this by adding the mapping between the fields for the objects in Databricks Unity Catalog and the Collibra attribute IDs to ingest the data in, using a JSON string.
- The text must be in JSON format.
- A Version block referencing 0.2 must be added.
- A Catalogs, Schemas, and Tables block can be added. The Catalogs block refers to Database assets, the Schemas block to Schema assets, and the Tables block to Table assets.
- Inside a Catalogs, Schemas, or Tables block, you can add a systemAttributes and a customParameters block. systemAttributes refers to the default system properties. customParameters refers to the custom properties.
- In each block, you specify the property name and the attribute ID to which you want to map the value in the property. The format is:
"[property name]": "[attribute resource ID]". For example,"Description from source system": "00000000-0000-0000-0001-000500000074".
Following system properties are supported:- Catalogs: "browse_only", "catalog_type", "connection_name", "created_at", "created_by", "isolation_mode", "metastore_id", "provider_name", "provisioning_info", "securable_kind", "securable_type", "share_name", "storage_location", "storage_root", "updated_at" , and "updated_by".
- Schemas: "catalog_type", "created_at", "created_by", "metastore_id", "securable_type", "securable_kind", "storage_location", "storage_root", "updated_at", and "updated_by".
- Tables: "access_point", "created_at", "created_by", "data_access_configuration_id", "data_source_format", "deleted_at", "metastore_id", "securable_type", "securable_kind", "sql_path", "storage_credential_name", "storage_location", "table_type", "updated_at", "updated_by", and "view_definition".
Tables mapping apply to tables and views.
Show exampleExample{"version": 0.2,"catalogs": {"systemAttributes": {"metastore_id": "00000000-0000-0000-0000-000000004224"},"customParameters": {"color": "00000000-0000-0000-0000-000000001234","Description from source system": "00000000-0000-0000-0001-000500000074"}},"schemas": {"customParameters": {"File Location": "00000000-0000-0000-0001-000500000004"}},"tables": {"systemAttributes": {"metastore_id": "00000000-0000-0000-0000-000000004224"},"customParameters": {"delta.lastCommitTimestamp": "00000000-0000-0000-0000-000000003114"}}}In this example:
- In the Database assets that we create, we'll add the metastore_id value in attribute "00000000-0000-0000-0000-000000004224", the Color value in attribute 00000000-0000-0000-0000-000000001234, and the Description from Source value in attribute 00000000-0000-0000-0001-000500000074.
- In the Schema assets that we create, we'll add the File Location value in attribute 00000000-0000-0000-0001-000500000004.
- In the Table and View assets that we create, we'll add the metastore_id value in attribute "00000000-0000-0000-0000-000000004224" and the delta.lastCommitTimestamp value in attribute 00000000-0000-0000-0000-000000003114.
- Version 0.3: This version allows you to ingest both default system properties and custom properties, and define separate decisions for tables and views. You can ingest most values from the Details page from Catalog, Schema, Table, and View objects into specific attributes in Collibra assets. You do this by adding the mapping between the fields for the objects in Databricks Unity Catalog and the Collibra attribute IDs to ingest the data in, using a JSON string.
- The text must be in JSON format.
- A Version block referencing 0.3 must be added.
- A Catalogs, Schemas, Tables, and Views block can be added. The Catalogs block refers to Database assets, the Schemas block to Schema assets, the Tables block to Table assets, and the Views block to Database View assets.
- Inside a Catalogs, Schemas, Tables, or Views block, you can add a systemAttributes and a customParameters block. systemAttributes refers to the default system properties. customParameters refers to the custom properties.
- In each block, you specify the property name and the attribute ID to which you want to map the value in the property. The format is:
"[property name]": "[attribute resource ID]". For example,"Description from source system": "00000000-0000-0000-0001-000500000074".
Following system properties are supported:- Catalogs: "browse_only", "catalog_type", "connection_name", "created_at", "created_by", "isolation_mode", "metastore_id", "provider_name", "provisioning_info", "securable_kind", "securable_type", "share_name", "storage_location", "storage_root", "updated_at" , and "updated_by".
- Schemas: "catalog_type", "created_at", "created_by", "metastore_id", "securable_type", "securable_kind", "storage_location", "storage_root", "updated_at", and "updated_by".
- Tables: "access_point", "created_at", "created_by", "data_access_configuration_id", "data_source_format", "deleted_at", "metastore_id", "securable_type", "securable_kind", "sql_path", "storage_credential_name", "storage_location", "table_type", "updated_at", "updated_by", and "view_definition".
- Views: "access_point", "created_at", "created_by", "data_access_configuration_id", "data_source_format", "deleted_at", "metastore_id", "securable_type", "securable_kind", "sql_path", "storage_credential_name", "storage_location", "table_type", "updated_at", "updated_by", and "view_definition".
Show exampleExample{"version": 0.3,"catalogs": {"systemAttributes": {"metastore_id": "00000000-0000-0000-0000-000000004224"},"customParameters": {"color": "00000000-0000-0000-0000-000000001234","Description from source system": "00000000-0000-0000-0001-000500000074"}},"schemas": {"customParameters": {"File Location": "00000000-0000-0000-0001-000500000004"}},"tables": {"systemAttributes": {"metastore_id": "00000000-0000-0000-0000-000000004224"},"customParameters": {"delta.lastCommitTimestamp": "00000000-0000-0000-0000-000000003114"}}"views": {"systemAttributes": {"metastore_id": "00000000-0000-0000-0000-000000004224"},"customParameters": {"view.sqlConfig.spark.sql.session.timeZone": "018cedbf-37fc-7da3-9ea8-da2af754222e"}}}In this example:
- In the Database assets that we create, we'll add the metastore_id value in attribute "00000000-0000-0000-0000-000000004224", the Color value in attribute 00000000-0000-0000-0000-000000001234, and the Description from Source value in attribute 00000000-0000-0000-0001-000500000074.
- In the Schema assets that we create, we'll add the File Location value in attribute 00000000-0000-0000-0001-000500000004.
- In the Table assets that we create, we'll add the metastore_id value in attribute "00000000-0000-0000-0000-000000004224" and the delta.lastCommitTimestamp value in attribute 00000000-0000-0000-0000-000000003114.
- In the Database View assets that we create, we'll add the metastore_id value in attribute "00000000-0000-0000-0000-000000004224" and the view.sqlConfig.spark.sql.session.timeZone value in attribute 018cedbf-37fc-7da3-9ea8-da2af754222e.
No
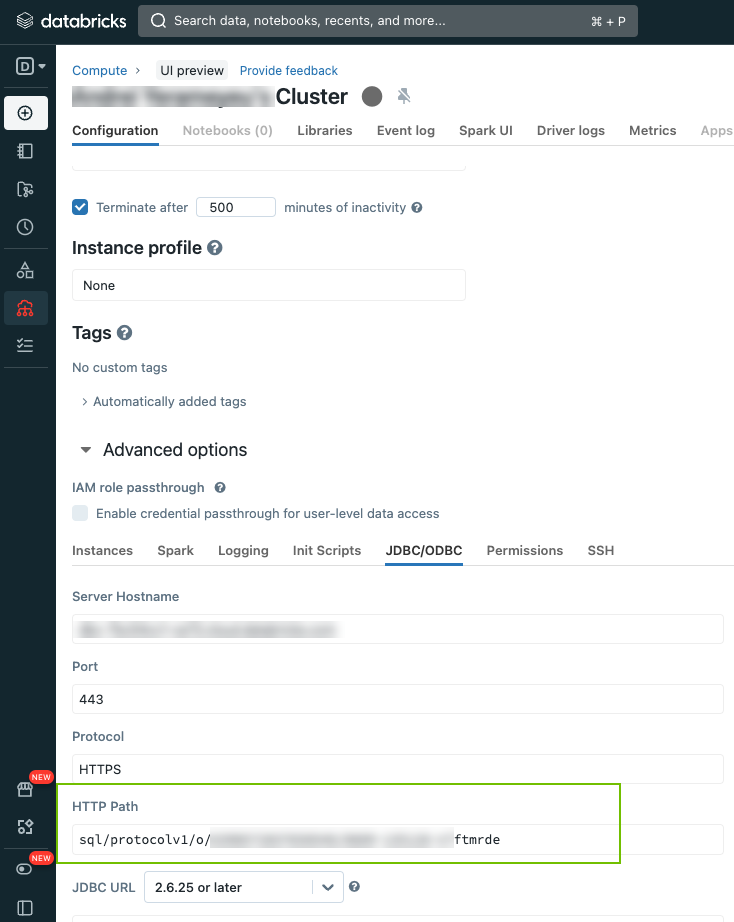
Compute Resource HTTP Path The HTTP path of the compute resource in Databricks Unity Catalog that we can process to extract the source tags.
You can find the HTTP path in the connection details of your cluster. For details, go to Get connection details for a cluster in Databricks documentation.
To integrate source tags, make sure the required permissions are given to the Databricks access token or OAuth Client.
No
Default Asset Status
Define the status that assets need to receive during the integration synchronization.
- No Status (default, recommended): With the first synchronization, assets receive the first status listed in the Operating Model statuses. During a resynchronization, the status is not updated. For example, if you change an asset status from Candidate to Review before resynchronization, the status remains Review.
- Implemented: All assets get the Implemented status. Before you select this option, turn off Status validation in Collibra Console. Otherwise, the synchronization does not complete for asset types that no longer have the Implemented status assigned. For more information, go to the Data Governance Center service configuration options.
Note This field can currently be overruled by the Default Asset Status (Deprecated) field in the synchronization configuration.
Yes
Advanced Configuration - Logging configuration
- Memory
- JVM arguments
These configuration options help when investigating issues with the capability.
Important- Only complete the fields Save Input Metadata, Logging configuration, Memory (MiB), and JVM arguments on request of or together with Collibra Support.
- Only use Log level if your data source is a commercial JDBC offering. For more information, go to the Collibra Marketplace.
No
Debug
This setting is not valid for this integration. It should be set to false. No
Log level
Only complete this field on the request of or together with Collibra Support.
No
- Click Add.
The capability is added to the Edge or Collibra Cloud site.
The fields become read-only.
You can now synchronize Databricks Unity Catalog.